
Llama 2: Inferencing on a Single GPU
Deploy the model
Deploy the model
-
For this experiment, we used Pytorch: 23.06 from NVIDIA NGC.
- Install the NVIDIA-container toolkit for the docker container to use the system GPU.
- Install the packages in the container using the commands below:
sudo docker run --runtime=NVIDIA -it --rm -v <File_location_Model>:/llama --ulimit memlock=-1 --ulimit stack=67108864 nvcr.io/NVIDIA/pytorch:23.06-py3 /bin/bash
root@43a3bd38ffa2:/workspace# cd /llama/
root@43a3bd38ffa2:/llama# python -m pip install --upgrade pip
root@43a3bd38ffa2:/llama# pip install -e.
root@43a3bd38ffa2:/llama# pip install deepspeed
- An example script for chat (example_chat_completion.py) is provided with the Llama model which we used for inferencing. This file has been modified for the purpose of this study. The flop profiler code was added to this file to calculate the numbers. Run the file using the following command:
root@43a3bd38ffa2:/llama# torchrun --nproc_per_node 1 example_chat_completion.py --ckpt_dir llama-2-7b-chat/ --tokenizer_path tokenizer.model --max_seq_len 800 --max_batch_size 1
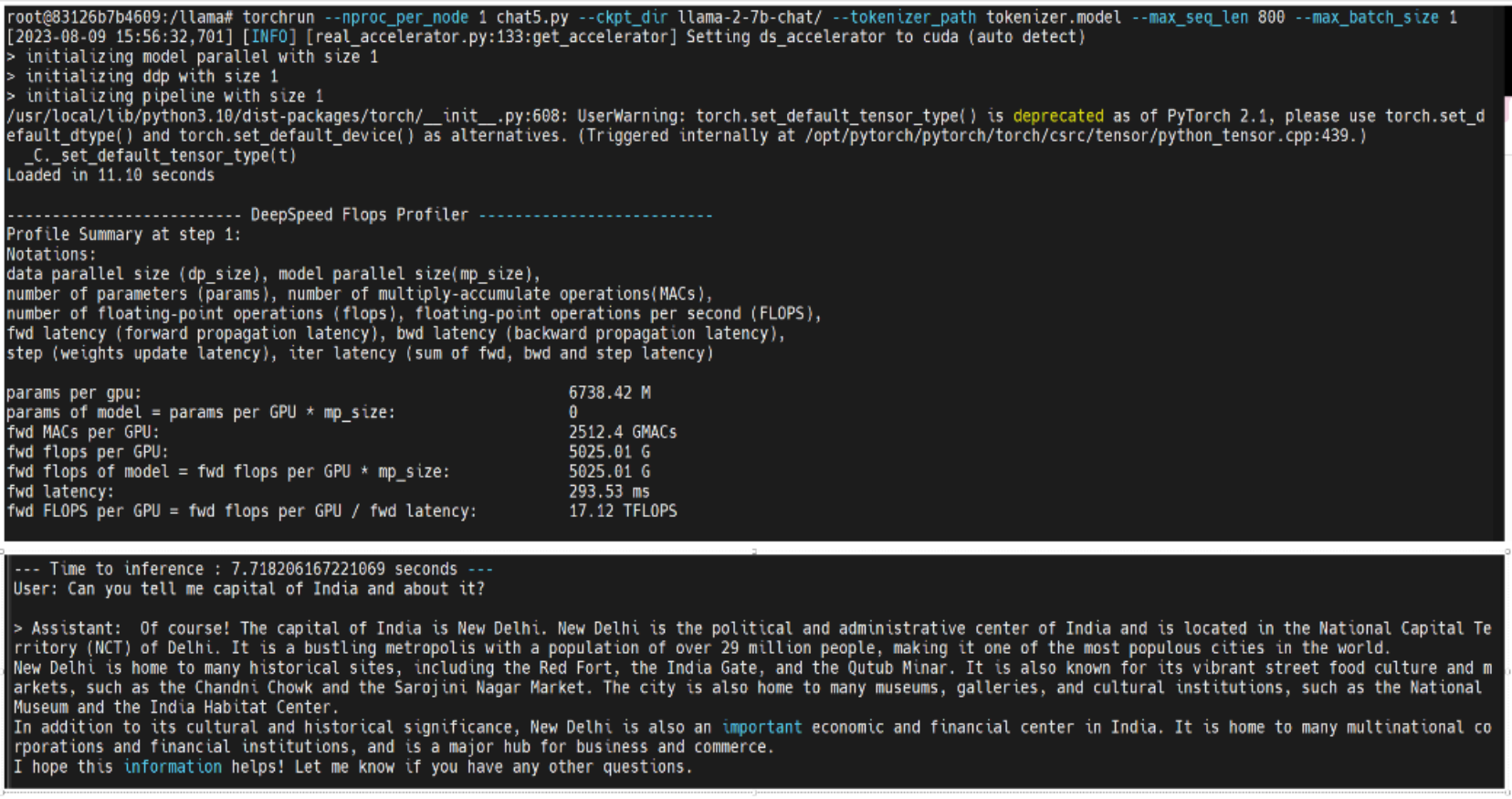
Figure 2. Example screenshot of DeepSpeed profile output