
None
None
-
Overall, our performance testing identified several key considerations to address prior to deploying APEX File Storage for Microsoft Azure clusters. These considerations are crucial to ensure that the clusters can effectively meet your organization's performance needs.
This section describes the three key factors that affect performance when designing a OneFS cluster of APEX File Storage for Microsoft Azure. The key factors are:
- Node types
- Node scale-out
- Virtual machine-level bursting
Note: The performance testing is conducted with supported +2d:1n protection level configurations. See Appendix A: supported cluster configuration details for all supported combinations.
Starting with OneFS 9.8.0.0, APEX File Storage for Microsoft Azure supports Ddv5-series VMs, Ddsv5-series VMs, Edv5-series VMs, and Edsv5-series VMs. Table 4 shows two Azure storage throughput limits and the network bandwidth limit at the node level for tests. These three limits will directly impact the maximum sequential read throughput performance.
Table 4. Azure storage throughput limits and network bandwidth limits for tested node types
Node type/VM size
vCPU
Memory (GiB)
Max uncached disk throughput (MBps)
Max burst uncached disk throughput (MBps)
Max network bandwidth (Mbps)
32
128
865
2,000
16,000
48
192
1,315
3,000
24,000
64
256
1,735
3,000
30,000
104
672
4,000
4,000
100,000
When optimizing the performance of a cluster, it is recommended to see Appendix C: recommended data disk configuration details for optimal performance for data disks configuration per node.
Node types
This section describes sequential read and sequential write performance for different node types.
Sequential read throughput
The Figure 2 represents a 128KB sequential read workload for different node types. It indicates that the sequential read performance increases with more powerful (larger VM size) nodes in the cluster.
The max burst uncached disk throughput and max network bandwidth directly impact the maximum sequential read throughput performance.
- Max burst uncached disk throughput: For E104ids_v5 node, its sequential read performance is constrained by the node-level storage throughput limit, which is max uncached disk throughput or max burst uncached disk throughput as shown in Table 5.
- Max network bandwidth: For most node types (excluding E104ids_v5), their sequential read performance is constrained by their node-level network bandwidth limit as shown in Table 5. The network bandwidth of a node is measured based on egress traffic across all network interfaces. This network bandwidth is shared by both node’s external (front-end) and internal (back-end) interfaces.
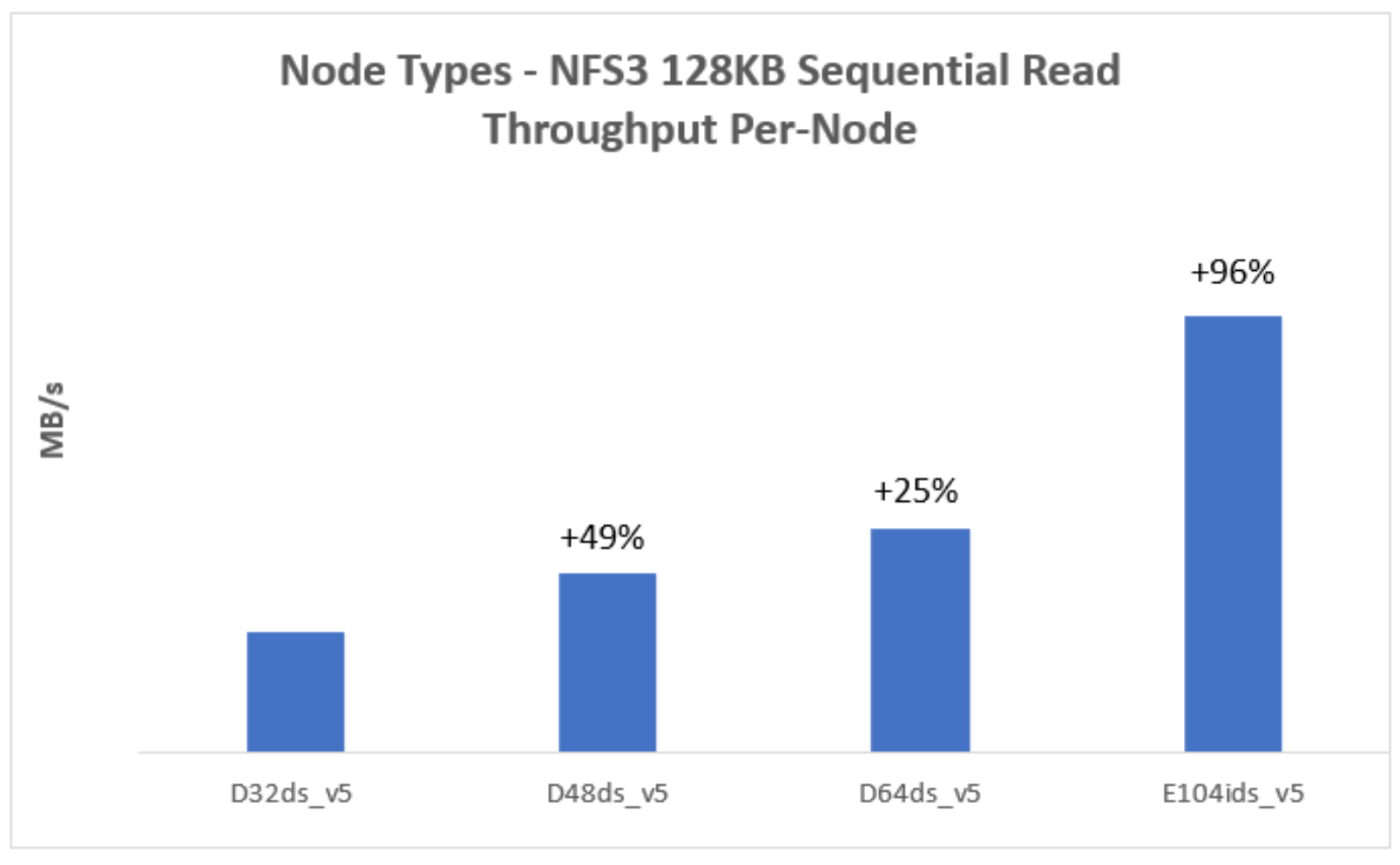
Figure 2. Sequential read throughput for different node types
Note: Each test uses 4-node cluster with 12 data disks per node.
Sequential write throughput
The Figure 3 represents a 512KB sequential write workload for different node types. It indicates that the sequential write performance increases with more powerful (larger VM size) nodes in the cluster.
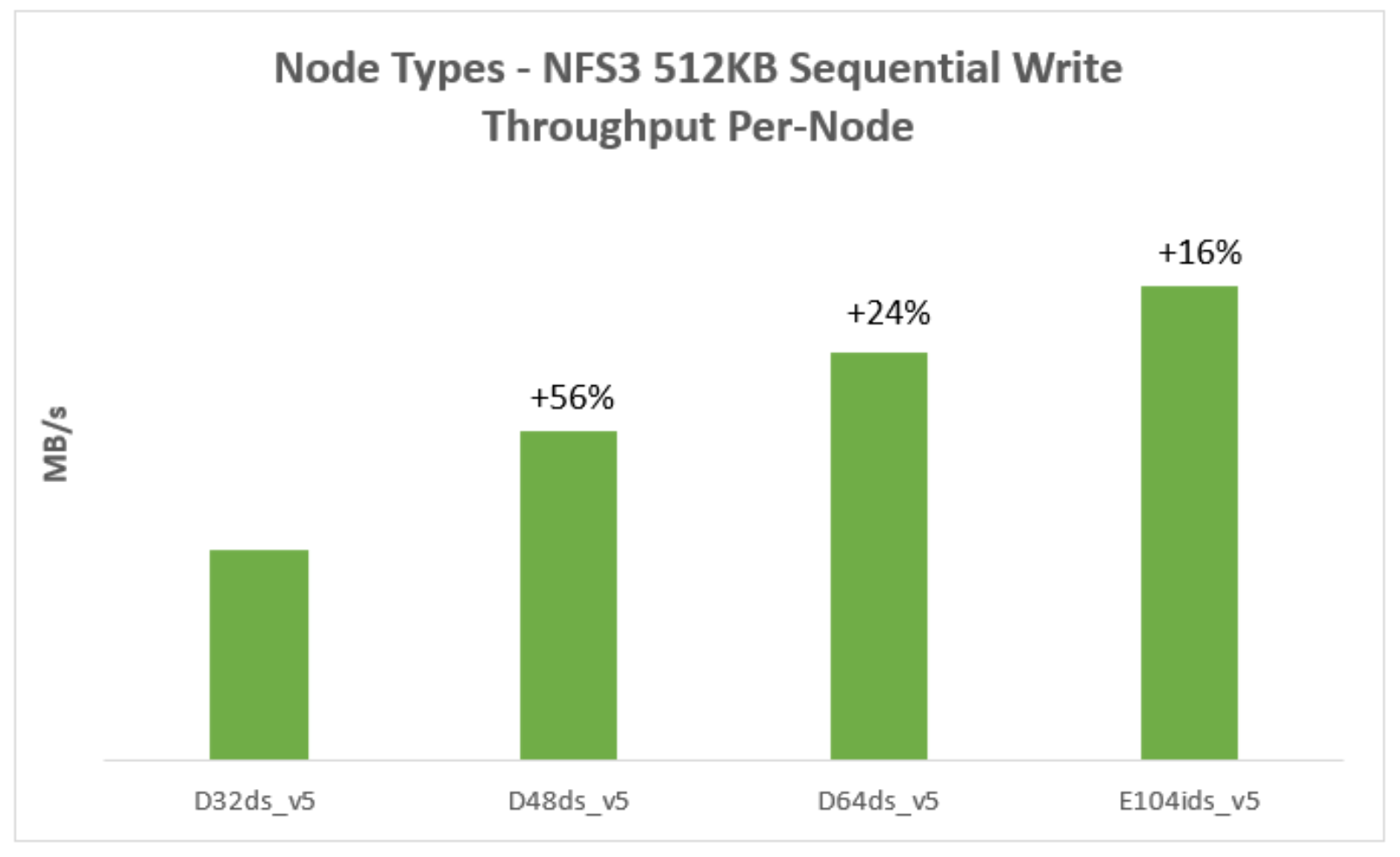
Figure 3. Sequential write throughput for different node types
Note: Each test uses 4-node cluster with 12 data disks per node.
Node scale-out
This section describes sequential read and sequential write performance for node scale-out.
Table 5 shows cluster configurations for node scale-out tests.
Table 5. Cluster configurations for node scale-out tests
Node type
Node count
Data disk type
Data disk count
10
P40
12
14
P40
12
18
P40
12
Note: The performance testing is conducted with supported +2d:1n protection level configurations. See Appendix A: supported cluster configuration details for all supported combinations.
Sequential read throughput
Figure 4 represents a 128KB sequential read workload for node scale-out. It indicates that the sequential read performance increases with more nodes in the cluster.
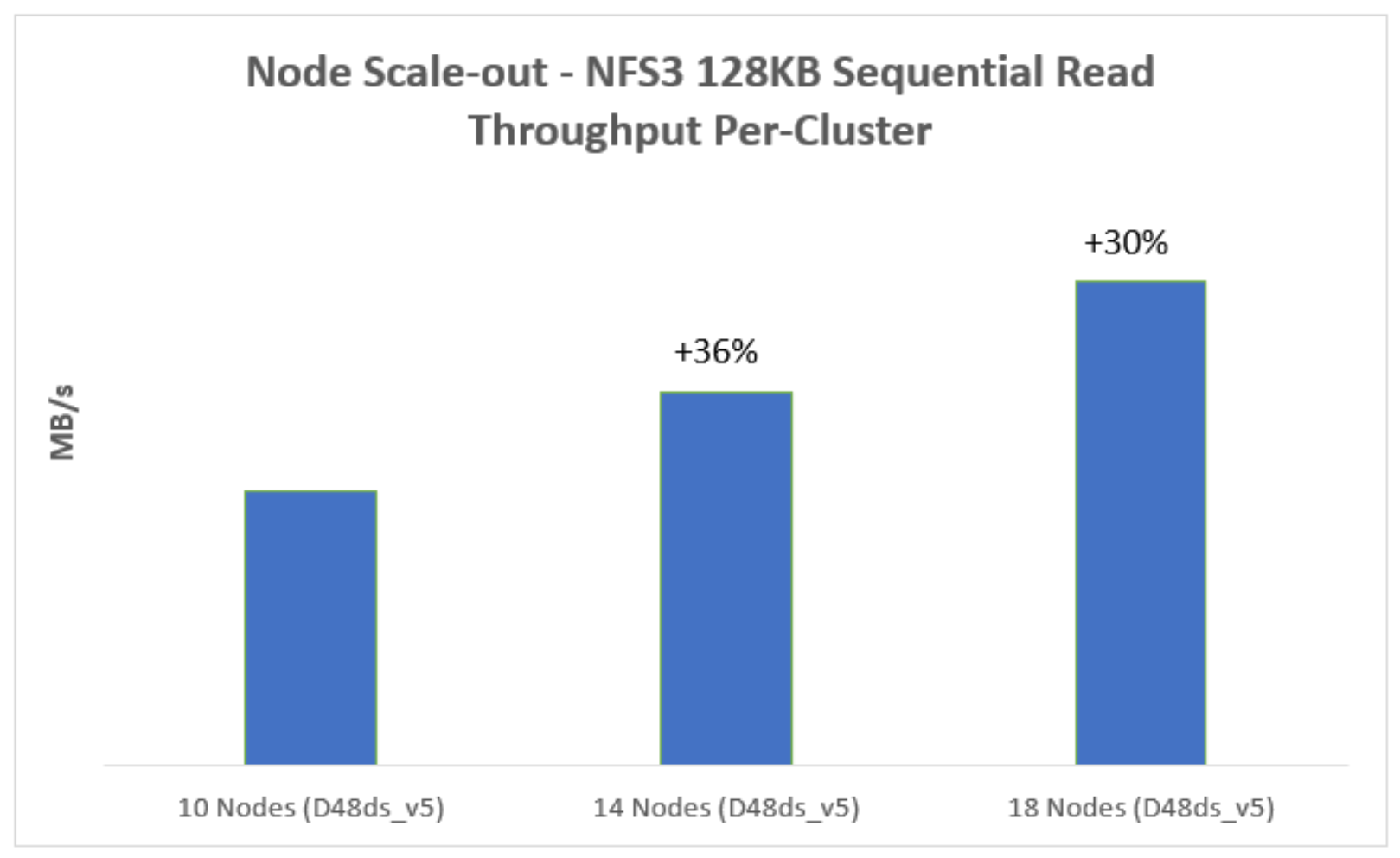
Figure 4. Sequential read performance for node Scale-out
Sequential write throughput
Figure 5 represents a 512KB sequential write workload for node scale-out. It indicates that the sequential write performance increases with more nodes in the cluster.
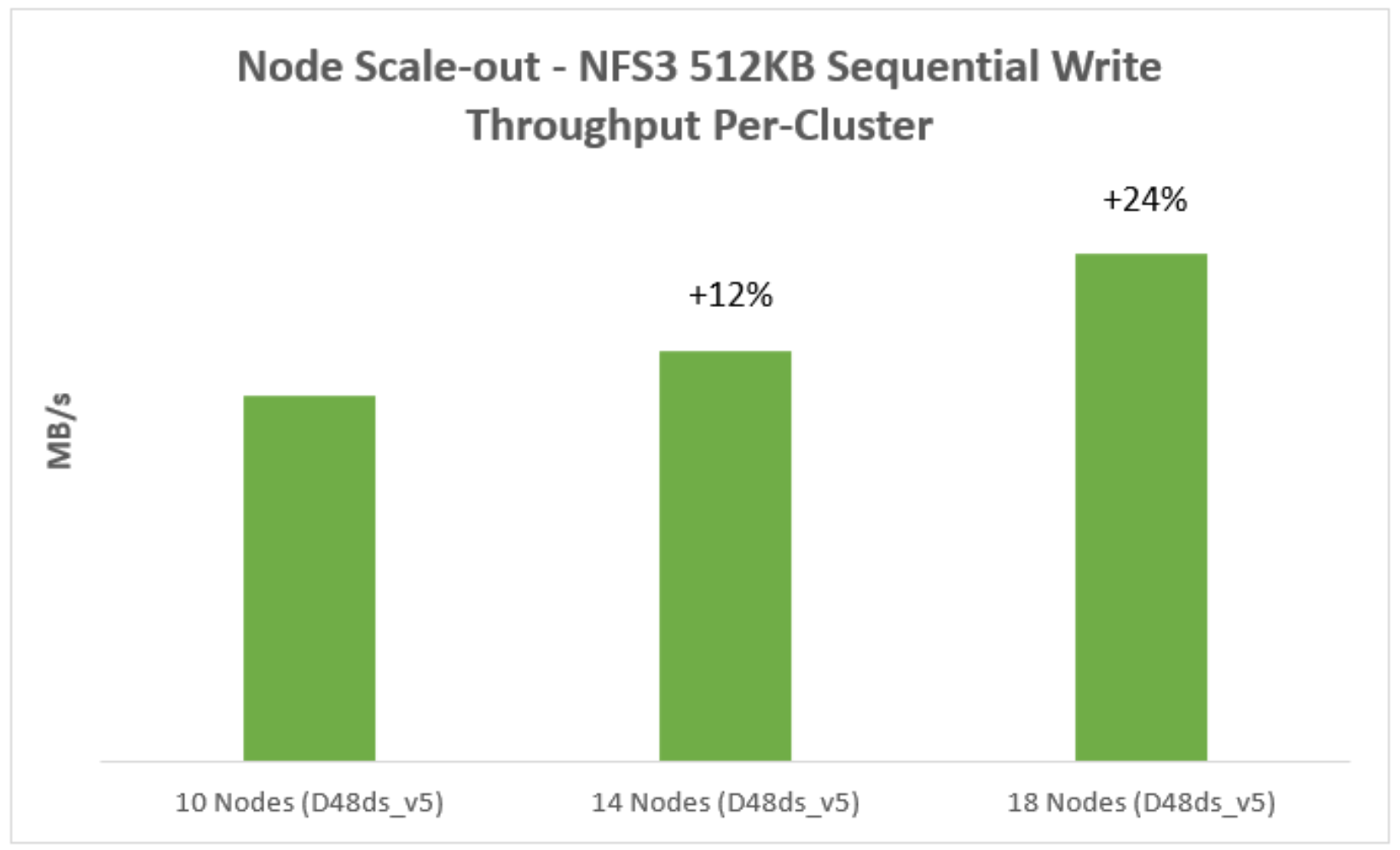
Figure 5. Sequential write performance for node Scale-out
Virtual machine-level bursting
This section describes sequential read performance when leveraging virtual machine-level bursting.
For VMs that support bursting, Azure will start with fully stocked credits for the VM and allow bursting for up to 30 minutes at the maximum burst rate, which is higher than the virtual machine-level’s max uncached disk throughput. The VM-level burst credits are restocked whenever throughput falls below the VM-level maximum uncached disk throughput limit. It takes less than a day to fully restock when burst credits are fully depleted. For more information about virtual machine-level bursting, see the Azure bursting document.
Since sequential writes do not utilize virtual machine-level bursting due to sequential write throughput lower than the virtual machine-level’s max uncached disk throughput, virtual machine-level bursting does not affect sequential write performance.
Sequential read throughput
The Figure 6 represents a 128KB sequential read workload with and without VM-level bursting.
- With VM-level bursting: The sequential read performance can surpass the VM-level maximum uncached disk throughput limit when utilizing VM-level bursting. With VM-level bursting, Figure 6 shows that a single D32ds_v5 node can exceed the VM-level maximum uncached disk throughput limit. However, the sequential read performance does not reach the VM-level maximum burst uncached disk throughput limit due to constraints imposed by the VM-level network bandwidth limit. This network bandwidth is shared between both the VM's external (front-end) and internal (back-end) interfaces.
- Without VM-level bursting: When VM-level burst credits are depleted, the sequential read workload runs without VM-level bursting. The sequential read throughput per node closely aligns with its VM-level maximum uncached disk throughput. Without VM-level bursting. Figure 6 shows that a single D32ds_v5 node read throughput is close to its VM-level maximum uncached disk throughput limit.
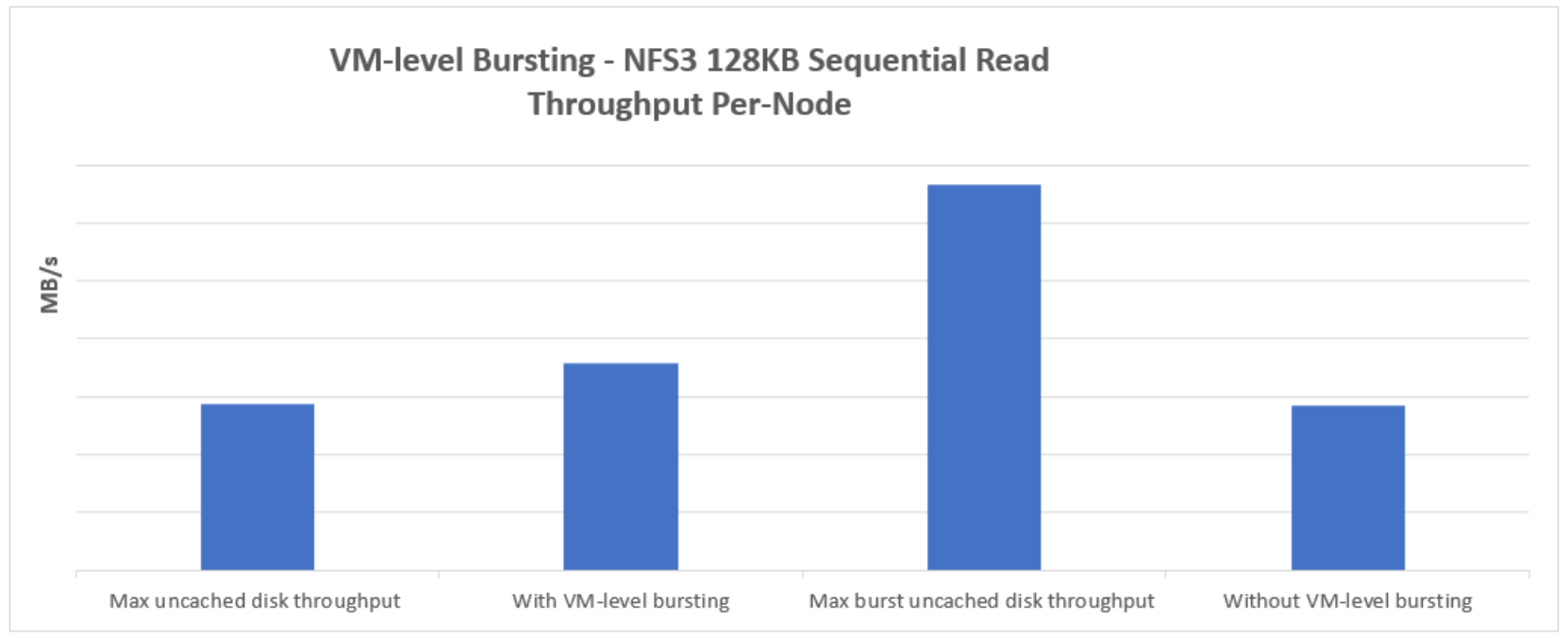
Figure 6. Sequential read performance for with and without VM-level bursting
Note: This test uses 4 D32ds_v5 nodes cluster with 12 data disks per node.