
NVIDIA GPU operator deployment
NVIDIA GPU operator deployment
-
NVIDIA GPU drivers are required to provision GPU on OpenShift Container Shift Platform. These drivers enable Compute Unified Device Architecture (CUDA) and allow workloads to consume GPU. The Dell OpenShift engineering team provisioned an NVIDIA H100 GPU on a compute node to validate the solution deployment.
Install the NFD operator
The Node Feature Discovery (NFD) operator is required for the NVIDIA GPU operator. To install the NFD operator:
- In the OpenShift Container Platform web console, select Operators > OperatorHub.
- Choose Node Feature Discovery from the list of available operators and click Install.
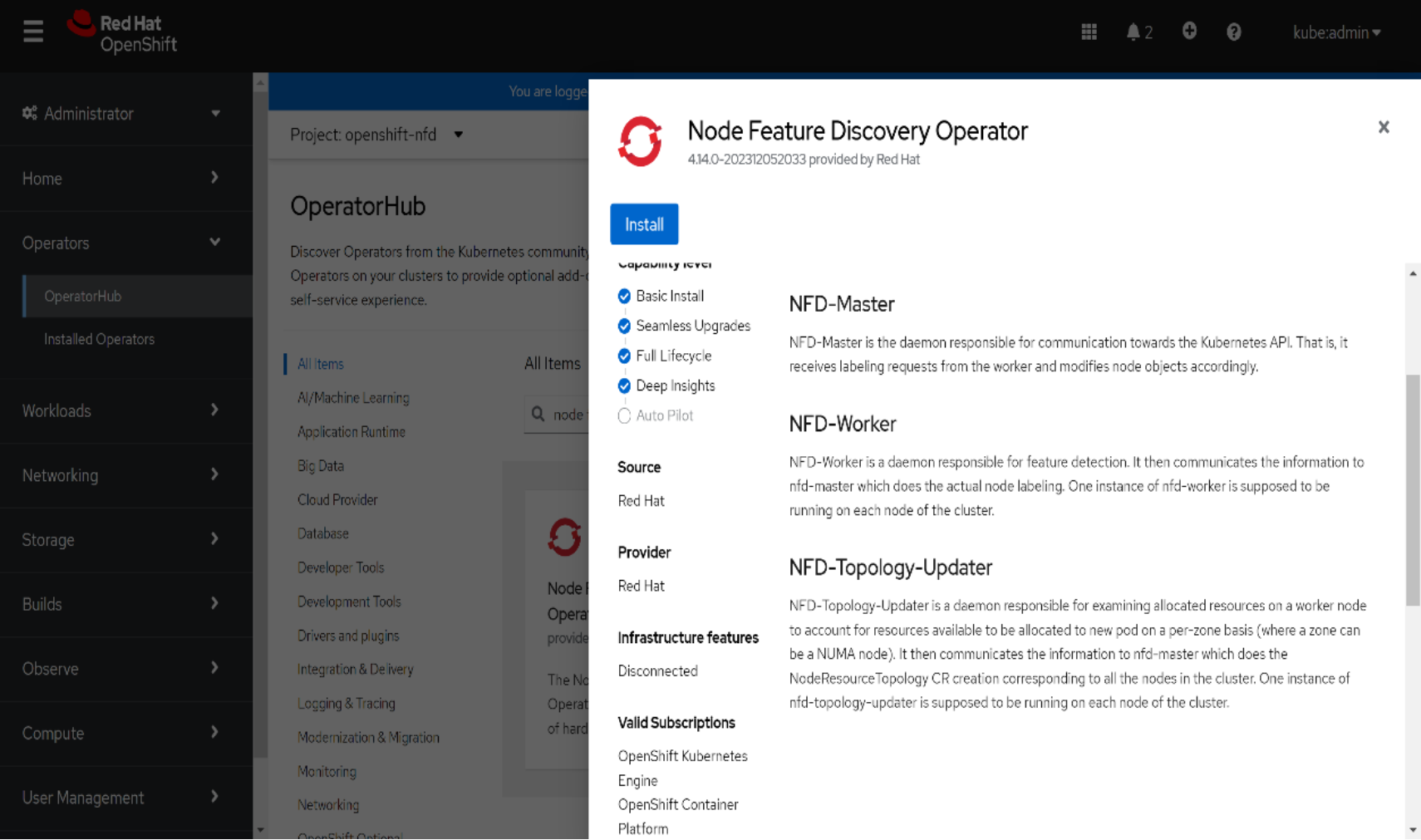
Figure 43. Installing the NFD operator
- On the Install Operator page, select a specific namespace on the cluster and click Install. The recommended namespace is openshift-nfd.
- Select Operators > Installed Operators.
- Verify that Node Feature Discovery is listed in the openshift-nfd project with a status of Succeeded.
- Verify that the status of the nfd-controller-manager pod is “Running,” as shown in the following code snippet:
[root@csah ~]# oc get pods -n openshift-nfd
NAME READY STATUS RESTARTS AGE
nfd-controller-manager-8c4b5d5cb-d76l4 2/2 Running 0 32s
- In the NodeFeatureDiscovery tab, create an NFD instance:
- Click Operators > Installed Operators and locate the Node Feature Discovery entry.
- Click NodeFeatureDiscovery under Provided APIs.
- Click Create NodeFeatureDiscovery.
- Click Create to start labeling the nodes in the cluster that have GPUs.
The NFD operator uses vendor PCI IDs to identify hardware in a node. NVIDIA uses the PCI ID 10de.
You can review the status of the NFD from the OpenShift Container Platform CLI.
- Verify that the new node labels have been added by running the following command:
oc describe node <node name>
Install the NVIDIA GPU
Perform this task as the cluster administrator from the OpenShift Container Platform web console:
- Select Operators > OperatorHub > All Projects.
- Search for NVIDIA GPU Operator and select it.
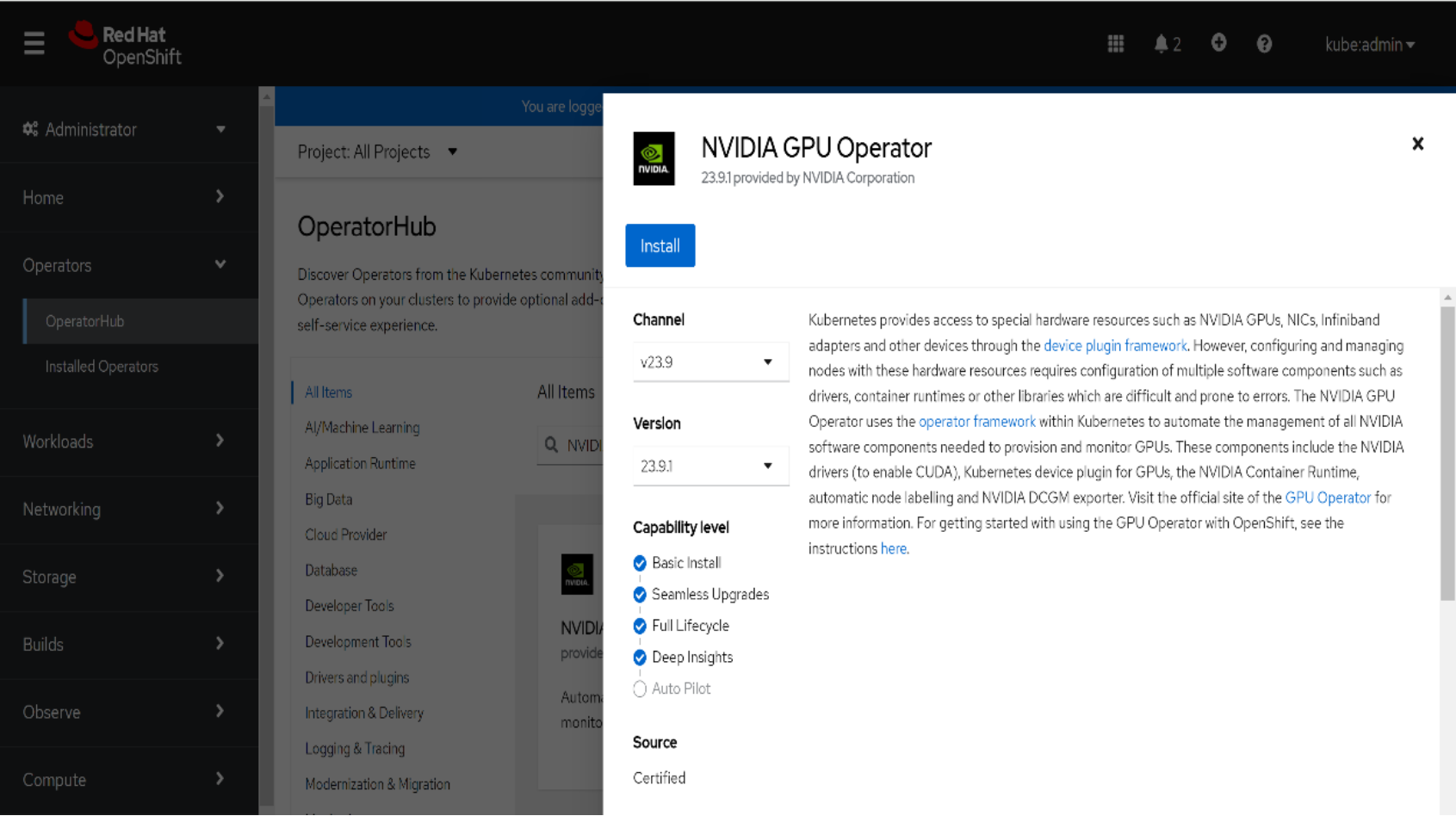
Figure 44. Installing the NVIDIA GPU operator
- Click Install.
The suggested namespace is nvidia-gpu-operator.
- Review the status of the GPU operator pod by running the following command:
oc get pods -n nvidia-gpu-operator
A ClusterPolicy CRD is created. The ClusterPolicy configures the GPU stack, including the image, the repository, and pod restrictions and credentials.
- From the web console, click Operators > Installed Operators > NVIDIA GPU Operator.
- In the ClusterPolicy tab, click Create ClusterPolicy.
The platform assigns the default name gpu-cluster-policy to the policy.
- Click Create.
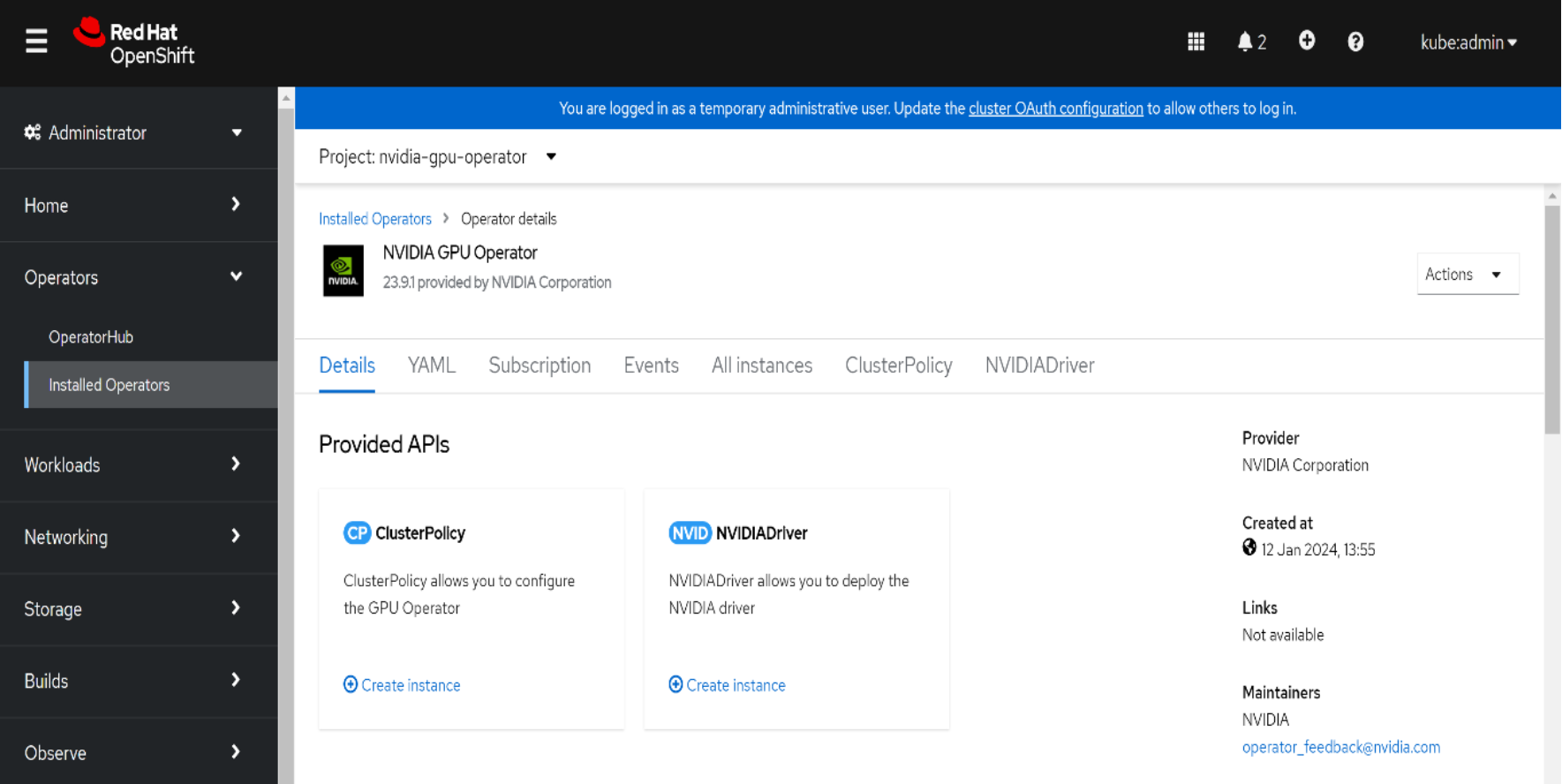
Figure 45. Creating the ClusterPolicy
The GPU operator installs the components that are required to set up the NVIDIA GPUs in the cluster.
After 20 minutes, the status of the deployed gpu-cluster-policy for the NVIDIA GPU operator changes to State:ready.
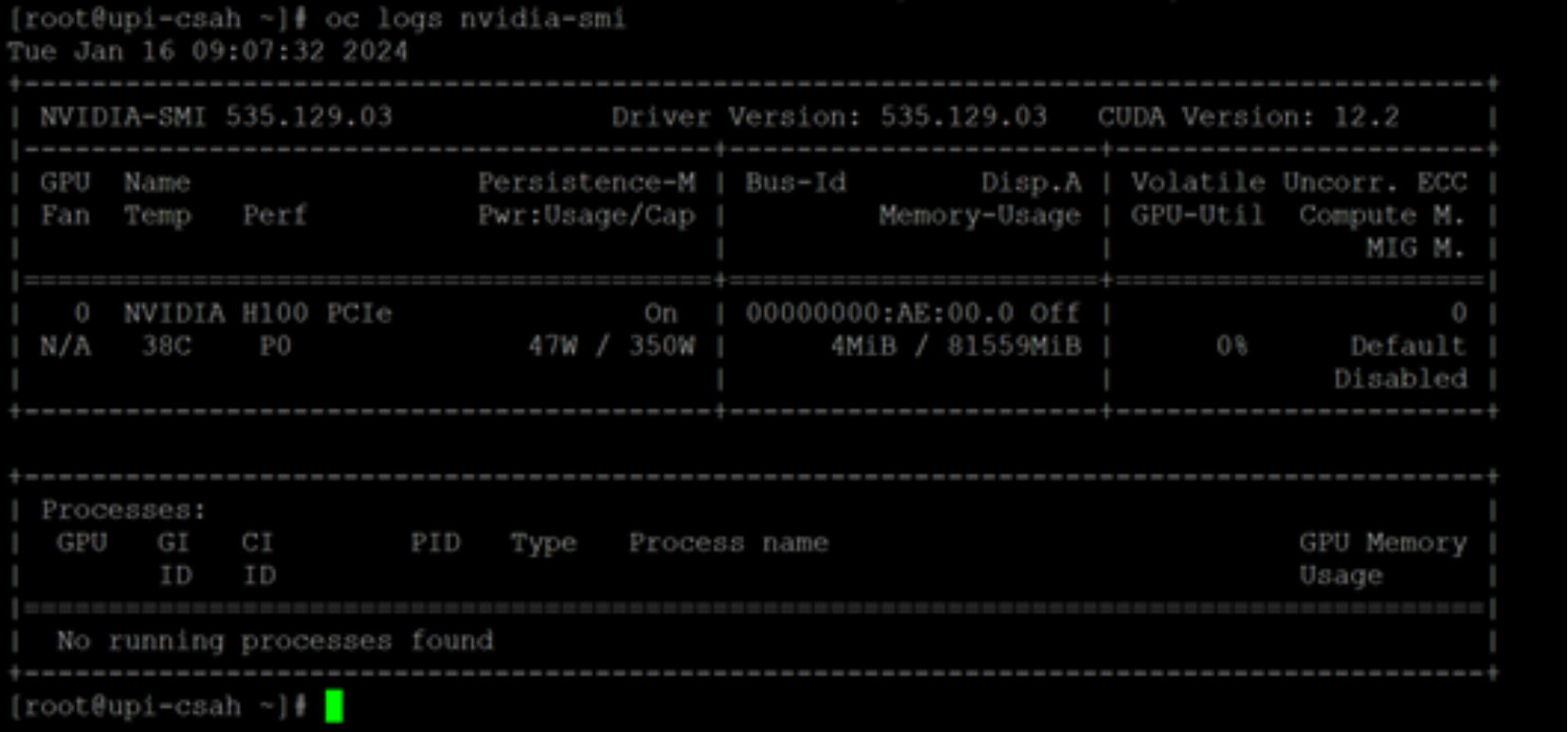
Figure 46. Sample nvidia-smi command output