
Inference results
Inference results
-
The inference component of this analysis demonstrates the effectiveness of running a single T4 GPU PowerEdge R740xd system with the additional OpenShift Container Platform layer relative to a four T4 GPU PowerEdge R740xd system with no container orchestration layer. We expect times to be similar on a per-GPU basis, but we ran these tests to demonstrate that the single-GPU system is a cost-effective way of performing inference workloads, depending on the inference task and the different benchmarks used. The following table presents the inference test results in terms of queries per second (server scenario) or inputs per second (offline scenario):
Table 3. MLPerf Inference v0.5 results: PowerEdge R740xd worker node with one T4 GPU
Model Type
Image Classification
Object Detection
Translation
Data Source
ImageNet
ImageNet
COCO
COCO
WMT E-G
Model
MobileNet-v1
ResNet-50 v1.5
SSD w/ MobileNet-v1
SSD w/ ResNet-34
NMT
Scenario
Server
Offline
Server
Offline
Server
Offline
Server
Offline
Server
Offline
Result *
15911
15558
4098
5283
5930
6420
95
129
180
314
* Server scenario results are in queries per second, offline scenario results are in inputs per second.
In the server inference scenario comparison, shown in the following figure, the queries per second for the single-GPU system are lower by a factor of 4, as expected. Input rates vary significantly, based on the size of input files and the application.
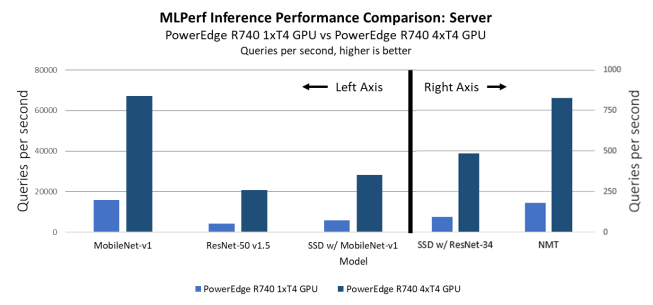
Figure 11. MLPerf Inference results: PowerEdge R740xd with four T4 GPUs compared to PowerEdge R740xd with one T4 GPU
On a per-GPU basis, the single-GPU system outperforms the multi-GPU system, likely because of the overhead that is required to manage the distribution of the workload. In every benchmark, the single-GPU system is faster compared to the multi-GPU system by approximately 10 to 15 percent.
The following figure shows the inference performance comparison per GPU for the server scenario:
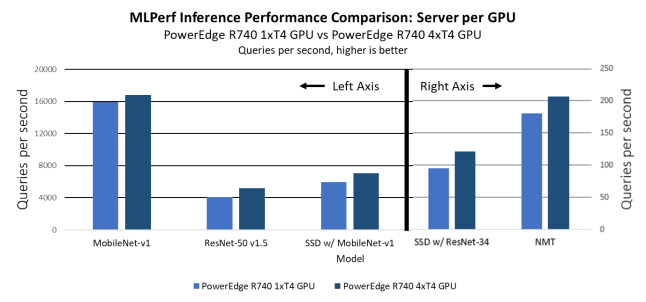
Figure 12. Per GPU MLPerf Inference results: Comparison of PowerEdge R740xd with four T4 GPUs compared to PowerEdge R740xd with one T4 GPU on OpenShift, with ECC turned on
In the offline scenarios, we observe results that are similar to the server scenario results: The single-GPU system is slower, by a factor of 4, in terms of raw performance, as shown in Figure 13, while the system performs better on a per-GPU basis, as shown in Figure 14.
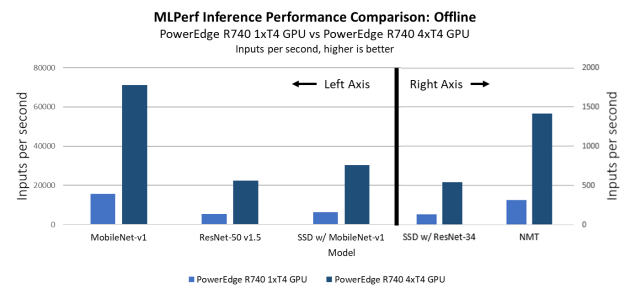
Figure 13. MLPerf Inference results: PowerEdge R740xd with one T4 GPU on OpenShift compared to PowerEdge R740xd with four T4 GPUs without OpenShift
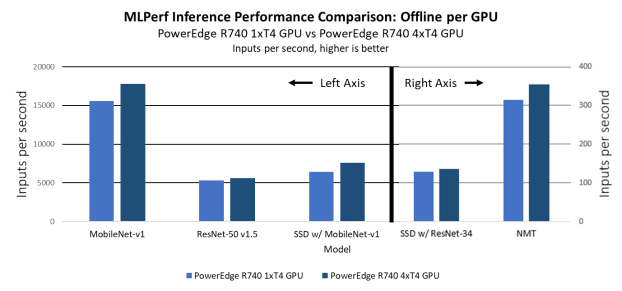
Figure 14. Per-GPU MLPerf Inference results: PowerEdge R740xd with one T4 GPU on OpenShift compared to PowerEdge R740xd with four T4 GPUs without OpenShift