
ECS constructs
ECS constructs
-
Understanding the main ECS constructs is necessary in managing application workflow and load balancing. This section details each of the upper-level ECS constructs.
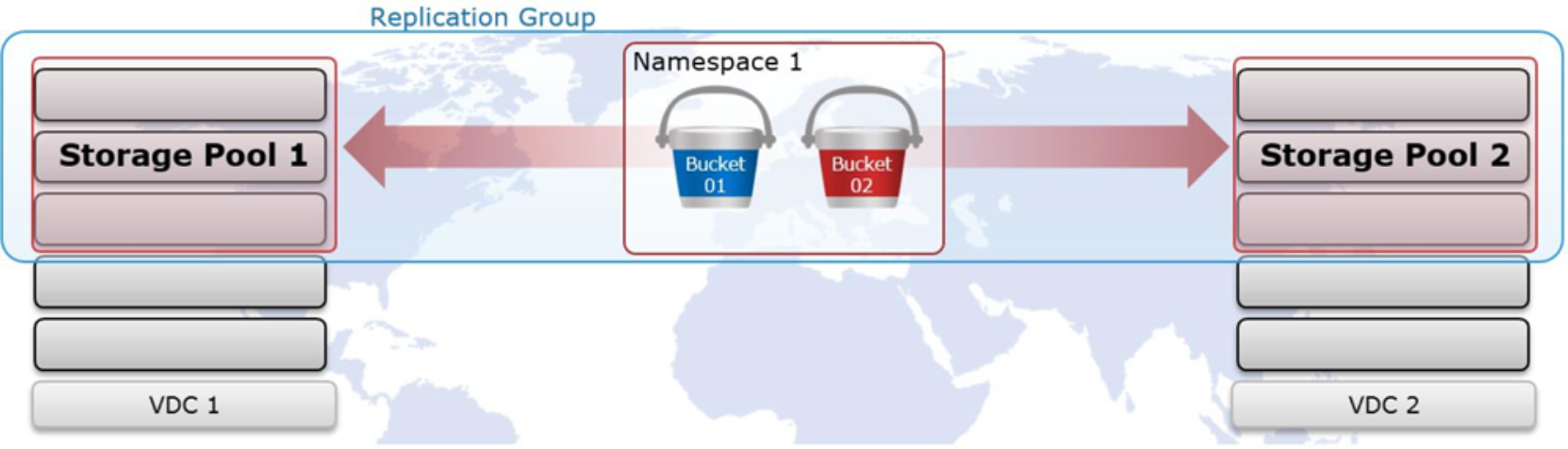
Figure 1. ECS upper-level constructs
Storage Pool - The first step in provisioning a site is creating a storage pool. Storage pools form the basic building blocks of an ECS cluster. They are logical containers for some or all nodes at a site.
ECS storage pools identify which nodes will be used when storing object fragments for data protection at a site. Data protection at the storage pool level is rack, node, and drive aware. System metadata, user data, and user metadata all coexist on the same disk infrastructure.
Storage pools provide a means to separate data on a cluster, if required. By using storage pools, organizations can organize storage resources based on business requirements. For example, if separation of data is required, storage can be partitioned into multiple different storage pools. Erasure coding (EC) is configured at the storage pool level. The two EC options on ECS are 12+4 or 10+2 (aka cold storage). EC configuration cannot be changed after storage pool creation.
Only one storage pool is required in a VDC. Generally, at most two storage pools should be created, one for each EC configuration, and only when necessary. Additional storage pools should only be implemented when there is a use case to do so, for example, to accommodate physical data separation requirements. This is because each storage pool has unique indexing requirements. As such, each storage pool adds overhead to the core ECS index structure.
A storage pool should have a minimum of five nodes and must have at least three or more nodes with more than 10% free space in order to allow writes.
Virtual Data Center (VDC) - VDCs are the top-level ECS resources and are also generally referred to as a site or zone. They are logical constructs that represent the collection of ECS infrastructure you want to manage as a cohesive unit. A VDC is made up of one or more storage pools.
Between two and eight VDCs can be federated. Federation of VDCs centralizes and thereby simplifies many management tasks associated with administering ECS storage. In addition, federation of sites allows for expanded data protection domains that include separate locations.
Replication Group - Replication groups are logical constructs that define where data is protected and accessed. Replication groups can be local or global. Local replication groups protect objects within the same VDC against disk or node failures. Global replication groups span two or more federated VDCs and protect objects against disk, node, and site failures.
The strategy for defining replication groups depends on multiple factors including requirements for data resiliency, the cost of storage, and physical versus logical separation of data. As with storage pools, the minimum number of replication groups required should be implemented. At the core ECS indexing level, each storage pool and replication group pairing is tracked and adds significant overhead. It is best practice to create the absolute minimum number of replication groups required. Generally, there is one replication group for each local VDC, if necessary, and one replication group that contains all sites. Deployments with more than two sites may consider additional replication groups, for example, in scenarios where only a subset of VDCs should participate in data replication, but this decision should not be made lightly.
Namespace - Namespaces enable ECS to handle multi-tenant operations. Each tenant is defined by a namespace and a set of users who can store and access objects within that namespace. Namespaces can represent a department within an enterprise, can be created for each unique enterprise or business unit, or can be created for each user. There is no limit to the number of namespaces that can be created from a performance perspective. However, the management overhead can also be a concern in creating and managing many namespaces.
Bucket - Buckets are containers for object data. Each bucket is assigned to one replication group. Namespace users with the appropriate privileges can create buckets and objects within buckets for each object protocol using its API. Buckets can be configured to support NFS and HDFS. Within a namespace, it is possible to use buckets as a way of creating subtenants. It is not recommended to have more than 1000 buckets per namespace. Generally, a bucket is created per application, workflow, or user.