
Storage engine
Storage engine
-
At the core of ECS is the storage engine. The storage engine layer contains the main components responsible for processing requests and storing, retrieving, protecting, and replicating data.
This section describes the design principles and how data is represented and handled internally.
Storage services
The ECS storage engine includes the services shown in the following figure:
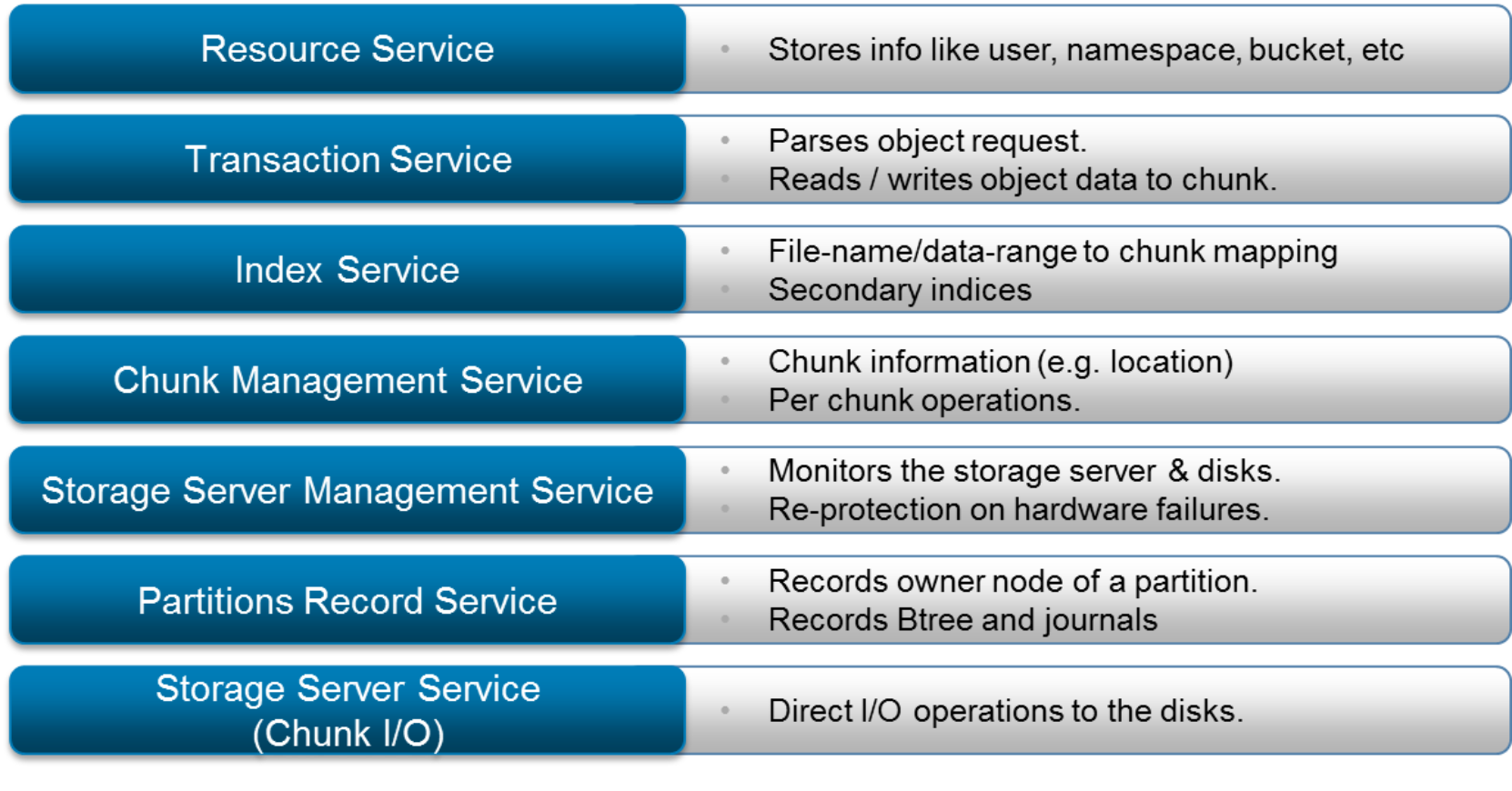
Figure 5. Storage engine services
The services of the Storage Engine are encapsulated within a Docker container that runs on every ECS node to provide a distributed and shared service.
Data
The primary types of data stored in ECS can be summarized as follows:
- Data - Application- or user-level content stored such as an image. Data is used synonymously with object, file, or content. Applications may store an unlimited amount of custom metadata with each object. The storage engine writes data and associated application-provided custom metadata together in a logical repository. Custom metadata is a robust feature of modern storage systems that provide further information or categorization of the data being stored. Custom metadata is formatted as key-value pairs and provided with write requests.
- System metadata - System information and attributes relating to user data and system resources. System metadata can be broadly categorized as follows:
- Identifiers and descriptors - A set of attributes used internally to identify objects and their versions. Identifiers are either numeric ids or hash values which are not of use outside the ECS software context. Descriptors define information such as type of encoding.
- Encryption keys in encrypted format - Data encryption keys are considered system metadata. They are stored in encrypted form inside the core directory table structure.
- Internal flags - A set of indicators used to track if byte range updates or encryption are enabled, and to coordinate caching and deletion.
- Location information - Attribute set with index and data location such as byte offsets.
- Timestamps - Attribute set that tracks time such as for object create or update.
- Configuration/tenancy information - Namespace and object access control.
Data and system metadata are written in chunks on ECS. An ECS chunk is a 128MB logical container of contiguous space. Each chunk can have data from different objects, as shown below in the following figure. ECS uses indexing to keep track of all the parts of an object that may be spread across different chunks and nodes.

Figure 6. 128MB chunk storing data of three objects
Chunks are written in an append-only pattern. The append-only behavior means that an application’s request to modify or update an existing object will not modify or delete the previously written data within a chunk, but rather the new modifications or updates will be written in a new chunk. Therefore, no locking is required for I/O and no cache invalidation is required. The append-only design also simplifies data versioning. Old versions of the data are maintained in previous chunks. If S3 versioning is enabled and an older version of the data is needed, it can be retrieved or restored to a previous version using the S3 REST API.
Data integrity and protection explains how data is protected at the chunk level.
Data management
ECS has a built-in snappy compression mechanism. The granularity is 2MB for small objects and 128MB for large objects. ECS employs a smart compression logic where it only compresses data that is compressible, saving resources from trying to compress already compressed or in-compressible data (such as encrypted data or video files). If more sophisticated compression is required, the ECS Java SDK supports client side ZIP and LZMA.
ECS uses a set of logical tables to store information relating to the objects. Key-value pairs are eventually stored on disk in a B+ tree for fast indexing of data locations. By storing the key-value pair in a balanced, searched tree like a B+ tree, the location of the data and metadata can be accessed quickly. ECS implements a two-level log-structured merge tree where there are two tree-like structures; a smaller tree is in memory (memory table) and the main B+ tree resides on disk. Lookup of key-value pairs occurs in memory first subsequently at the main B+ tree on disk if needed. Entries in these logical tables are first recorded in journal logs and these logs are written to disks in triple-mirrored chunks. The journals are used to track transactions not yet committed to the B+ tree. After each transaction is logged into a journal, the in-memory table is updated. Once the table in the memory becomes full or after a certain period, its merge sorted or dumped to B+ tree on disk. The number of journal chunks used by the system is insignificant when compared to B+ tree chunks. The following figure illustrates this process:
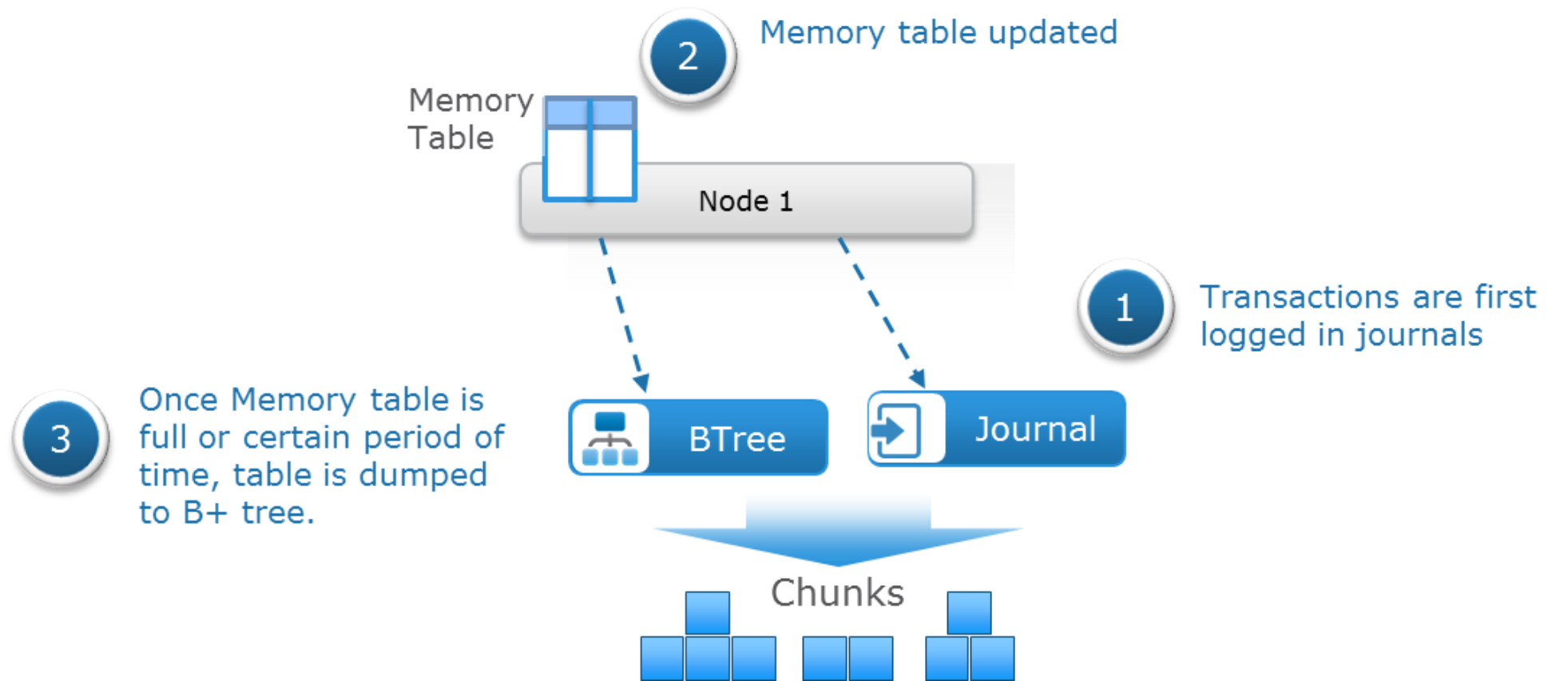
Figure 7. Memory table dumped to B+ tree
The following table shows the information stored in the Object (OB) table. The OB table contains the names of objects and their chunk location at a certain offset and length within that chunk. In this table, the object name is the key to the index and the value is the chunk location. The index layer within the Storage Engine is responsible for the object name-to-chunk mapping.
Table 2. Object table entries
Object name
Chunk location
ImgA
C1:offset:length
FileB
- C2:offset:length
- C3:offset:length
The chunk table (CT) records the location for each chunk, as detailed in the following table:
Table 3. Chunk table entries
Chunk ID
Location
C1
- Node1:Disk1:File1:Offset1:Length
- Node2:Disk2:File1:Offset2:Length
- Node3:Disk2:File6:Offset:Length
ECS was designed to be a distributed system such that storage and access of data are spread across all nodes. Tables used to manage object data and metadata grow over time as the storage is used and grows. The tables are divided into partitions and assigned to different nodes where each node becomes the owner of the partitions it is hosting for each of the tables. To get the location of a chunk, for example, the Partition Records table (PR) is queried for owner node which has knowledge of the chunk location. A basic PR table is illustrated in the following table:
Table 4. Partition records table entries
Partition ID
Owner
P1
Node 1
P2
Node 2
P3
Node 3
If a node goes down, other nodes take ownership of its partitions. The partitions are recreated by reading the B+ tree root and replaying the journals stored on disk. The following figure shows the failover of partition ownership:
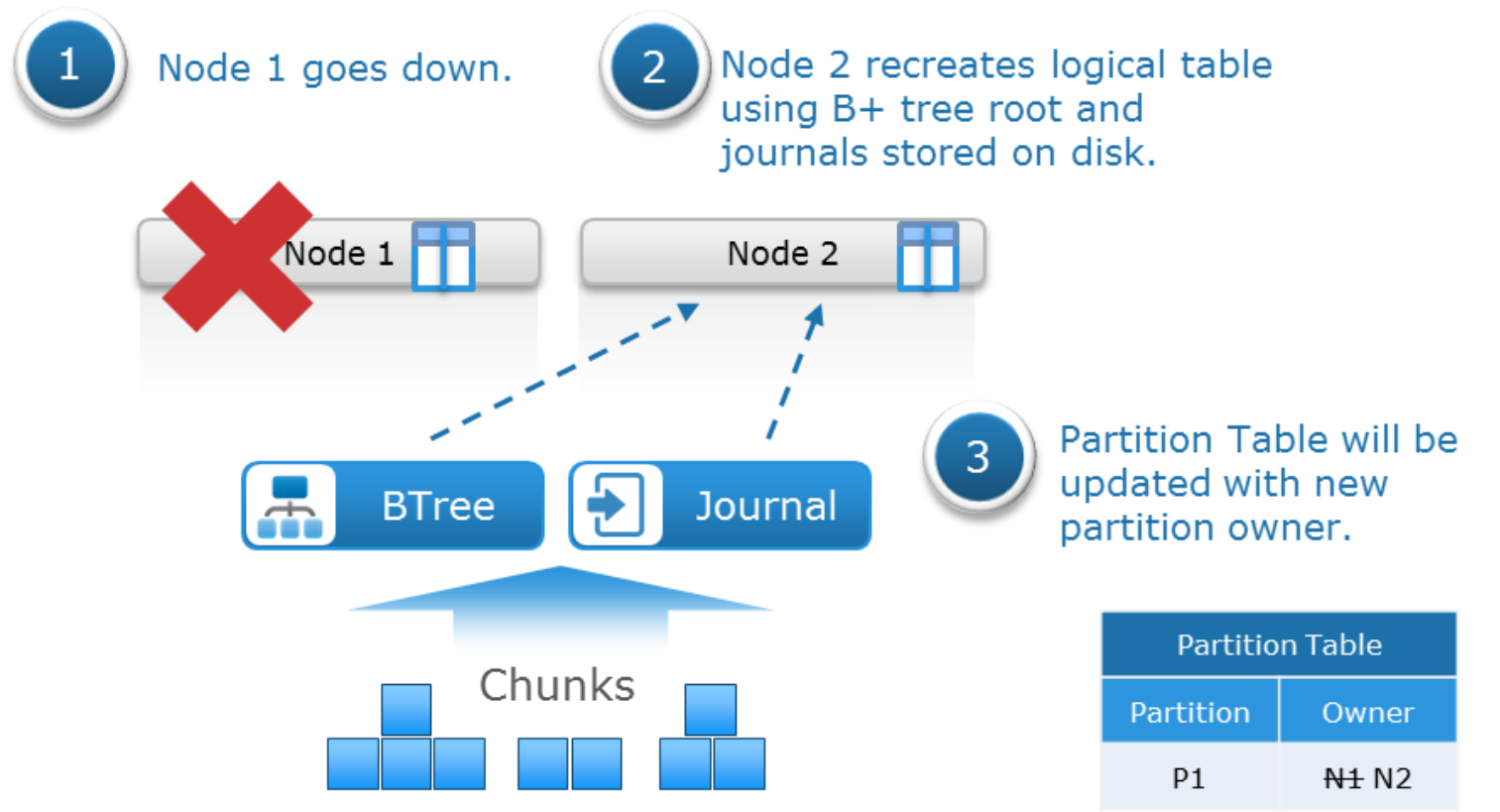
Figure 8. Failover of partition ownership
Data flow
Storage services are available from any node. Data is protected by distributed EC segments across drives, nodes, and racks. ECS runs a checksum function and stores the result with each write. If the first few bytes of data are compressible ECS will compress the data. With reads, data is decompressed, and its stored checksum is validated. Here is an example of a data flow for a write in five steps:
- Client sends object create request to a node.
- Node servicing the request writes the new object’s data into a repo (short for repository) chunk.
- On successful write to disk a PR transaction occurs to enter name and chunk location.
- The partition owner records the transaction in journal logs.
- Once the transaction has been recorded in the journal logs, an acknowledgment is sent to the client.
The following figure shows an example of the data flow for a read for hard disk drive architecture like Gen2 and EX300, EX500, EX3000, and EX5000.
- A read object request is sent from client to Node 1.
- Node 1 uses a hash function using the object name to determine which node is the partition owner of the logical table where this object information resides. In this example, Node 2 is owner and thus Node 2 will do a lookup in the logical tables to get location of chunk. In some cases, the lookup can occur on two different nodes, for instance when the location is not cached in logical tables of Node 2.
- From the previous step, location of chunk is provided to Node 1 who will then issue a byte offset read request to the node that holds the data, Node 3 in this example, and will send data to Node 1.
- Node 1 sends data to requesting client.
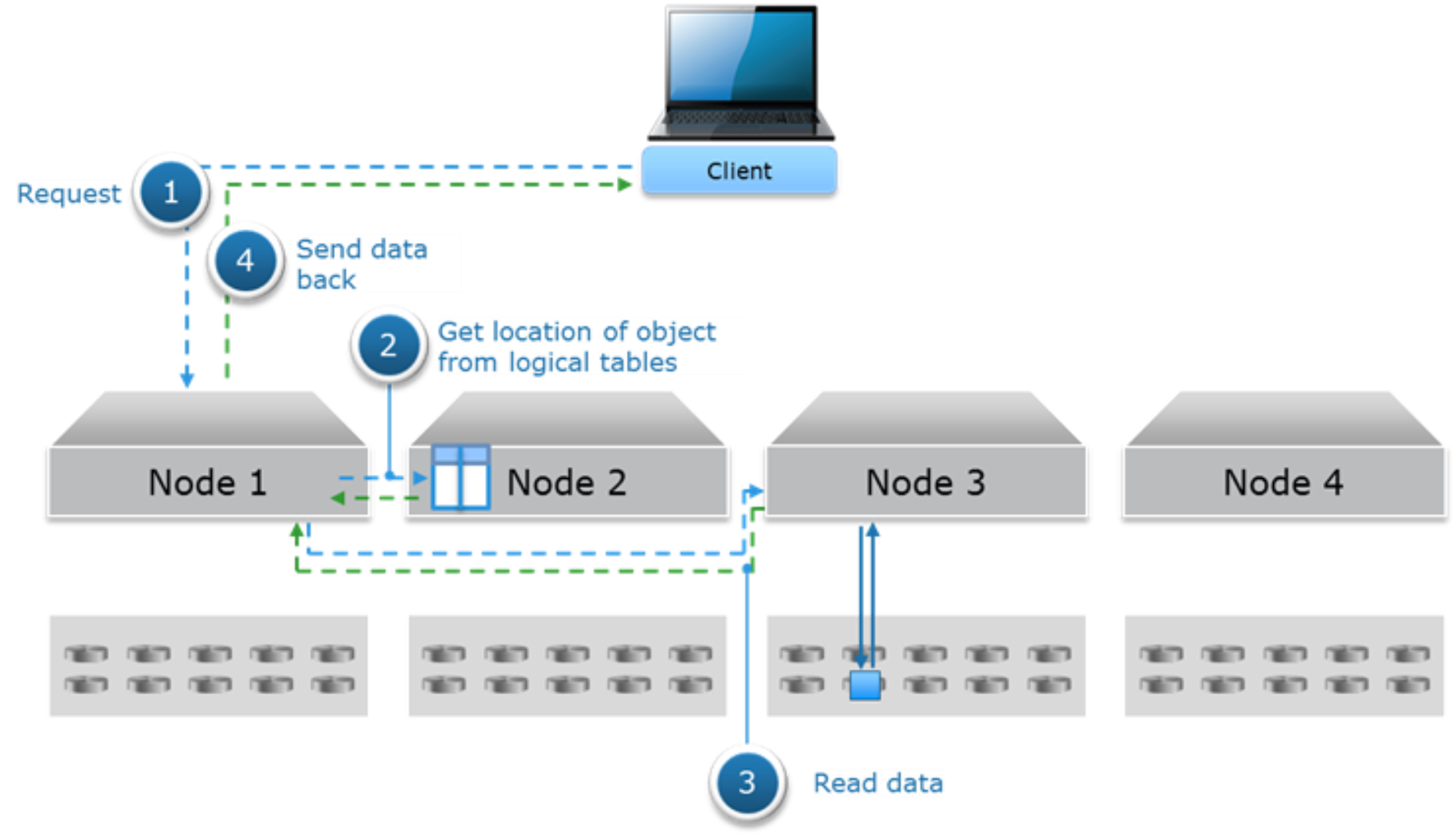
Figure 9. Read data flow for hard disk drive architecture
The following figure Figure 10shows an example the data flow for a read for all flash architecture like EXF900.
- A read object request is sent from client to Node 1.
- Node 1 uses a hash function using the object name to determine which node is the partition owner of the logical table where this object information resides. In this example, Node 2 is owner and thus Node 2 will do a lookup in the logical tables to get location of chunk. In some cases, the lookup can occur on two different nodes, for instance when the location is not cached in logical tables of Node 2.
- From the previous step, location of chunk is provided to Node 1 who will then read the data from Node 3 directly.
- Node 1 sends data to requesting client.
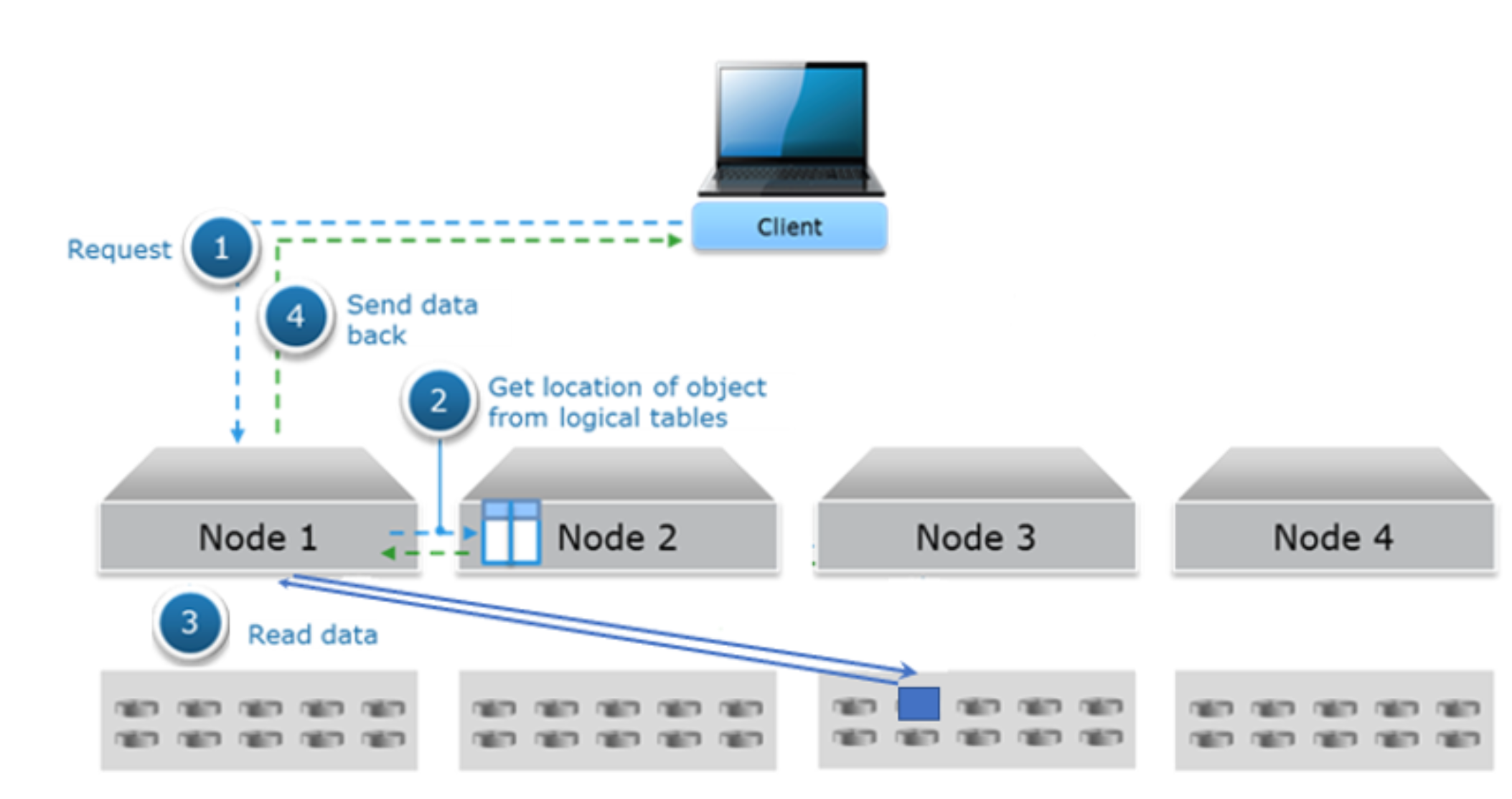
Figure 10. Read data flow for all-flash architecture
Note: In the all-flash architecture like EXF900, each node can read data from other node directly, other than the hard disk drive architecture that each node can only read the data store in themselves.
Write optimizations for file size
For smaller writes to storage ECS uses a method called box-carting to minimize impact to performance. Box-carting aggregates multiple smaller writes of 2MB or less in memory and writes them in a single disk operation. Box-carting limits the number of roundtrips to disk required process individual writes.
For writes of larger objects, nodes within ECS can process write requests for the same object simultaneously and take advantage simultaneous writes across multiple spindles in the ECS cluster. Thus, ECS can ingest and store small and large objects efficiently.
Space reclamation
Writing chunks in an append-only manner means that data is added or updated by first keeping the original written data in place and secondly by creating net new chunk segments which may or may not be included in the chunk container of the original object. The benefit of append-only data modification is an active/active data access model which is not hindered by file-locking issues of traditional filesystems. This being the case, as objects are updated or deleted, data in chunks becomes no longer referenced or needed. Two garbage collection methods used by ECS to reclaim space from discarded full chunks, or chunks containing a mixture of deleted and non-deleted object fragments which are no longer referenced, are:
- Normal Garbage Collection - When an entire chunk is garbage, reclaim space.
- Partial Garbage Collection by Merge - When a chunk is 2/3 garbage, reclaim the chunk by merging the valid parts of with other partially filled chunks to a new chunk, reclaim space.
Garbage collection has also been applied to the ECS CAS data services access API to clean up orphan blobs. Orphan blobs, which are unreferenced blobs identified in the CAS data stored on ECS, will be eligible for space reclamation using normal garbage collection methods.
SSD metadata caching
ECS metadata is stored in B-trees. Each B-tree may have entries in memory, journal transactions and on disk. For the system to have a complete picture of a particular B-tree all three locations are queried which often includes multiple look ups to disk.
To minimize latency for metadata lookups, an optional SSD-based cache mechanism has been implemented in ECS 3.5. The cache holds recently accessed B-tree pages. This means read operations on the latest B-trees will always hit the SSD-based cache and avoids trips to spinning disks.
Here are some highlights for the new SSD metadata caching feature:
- Improved system-wide read latency and TPS (Transactions Per Second) for small files
- One 960GB flash drive per node
- Net new nodes from manufacturing include the SSD drive as an option
- Existing field nodes—Gen3 and Gen2—can be upgraded using upgrade kits and self-service installation
- SSD drives can be added while ECS is online
- Improvement for small file analytics workloads which require fast reads of large data sets
- All nodes in a VDC must have SSDs to enable this feature
The ECS fabric detects when an SSD kit has been installed. This triggers the system to automatically initialize and begin using the new drive. The following figure shows SSD cache enabled:
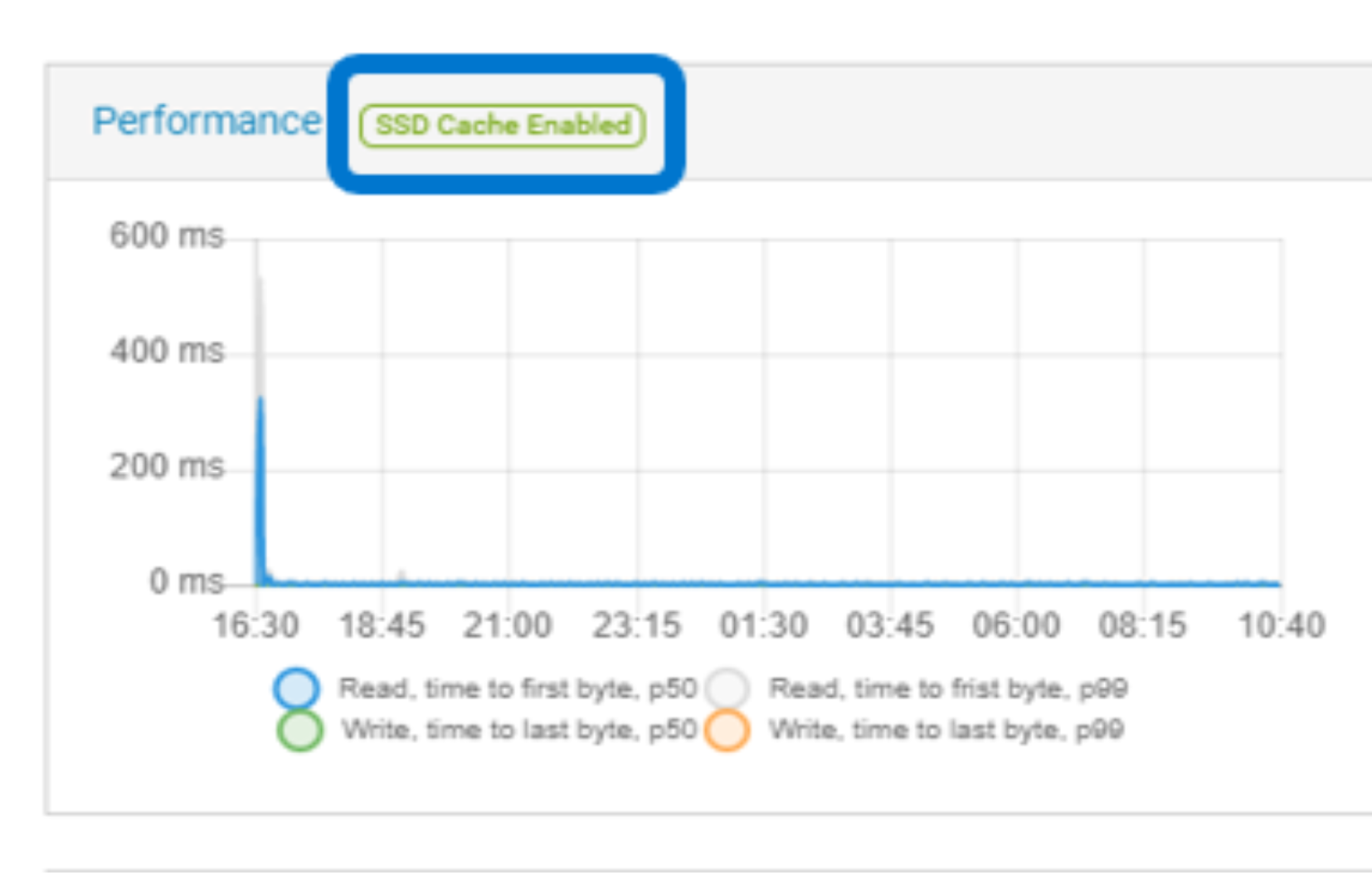
Figure 11. SSD cache enabled
SSD metadata caching improves small reads and bucket listing. As we tested in our lab, the listing performance improves 50% with 10MB objects. The read performance improves 35% with 10KB objects and 70% with 100KB objects.
Cloud DVR
ECS supports cloud Digital Video Recording (DVR) feature which addresses a legal copyright requirement for cable and satellite companies. The requirement is every unit of recording mapped to an object on ECS needs to be copied a predetermined number of times. The predetermined number of copies are known as fanout. The pre-determined number of copies (fan-out) is not really a requirement for redundancy or performance gain, but it is more of a legal copyright requirement for cable and satellite companies. ECS supports:
- Create fanout number of copies of object created in ECS
- Allow read of specific copy
- Allow delete of specific copy
- Allow delete of all copies
- Allow copy of specific copy
- Allow listing of copies
- Allow bucket listing of fanout objects
The cloud DVR feature can be enabled through Service Console. For the first time, you must enable the cloud DVR feature using Service Console. After enabling cloud DVR, by default, for all the new nodes cloud DVR is enabled.
Run the following command in Service Console to enable the cloud DVR feature:
service-console run Enable_CloudDVR
The cloud DVR feature supports APIs and you can refer to the ECS Data Access Guide for more details.
S3 select
S3 select, launched in version 3.7, enables applications to retrieve only a subset of data from an object by using simple SQL expressions. By using s3 select to retrieve only the data needed by your application, you can achieve drastic performance increases and network bandwidth savings.
Using the example of a 2GB csv object, without s3 select an application would have to download the entire 2GB object and then do the processing on that data. With s3 select, the application issues SQL select commands and potentially gets only a small subset of that data.
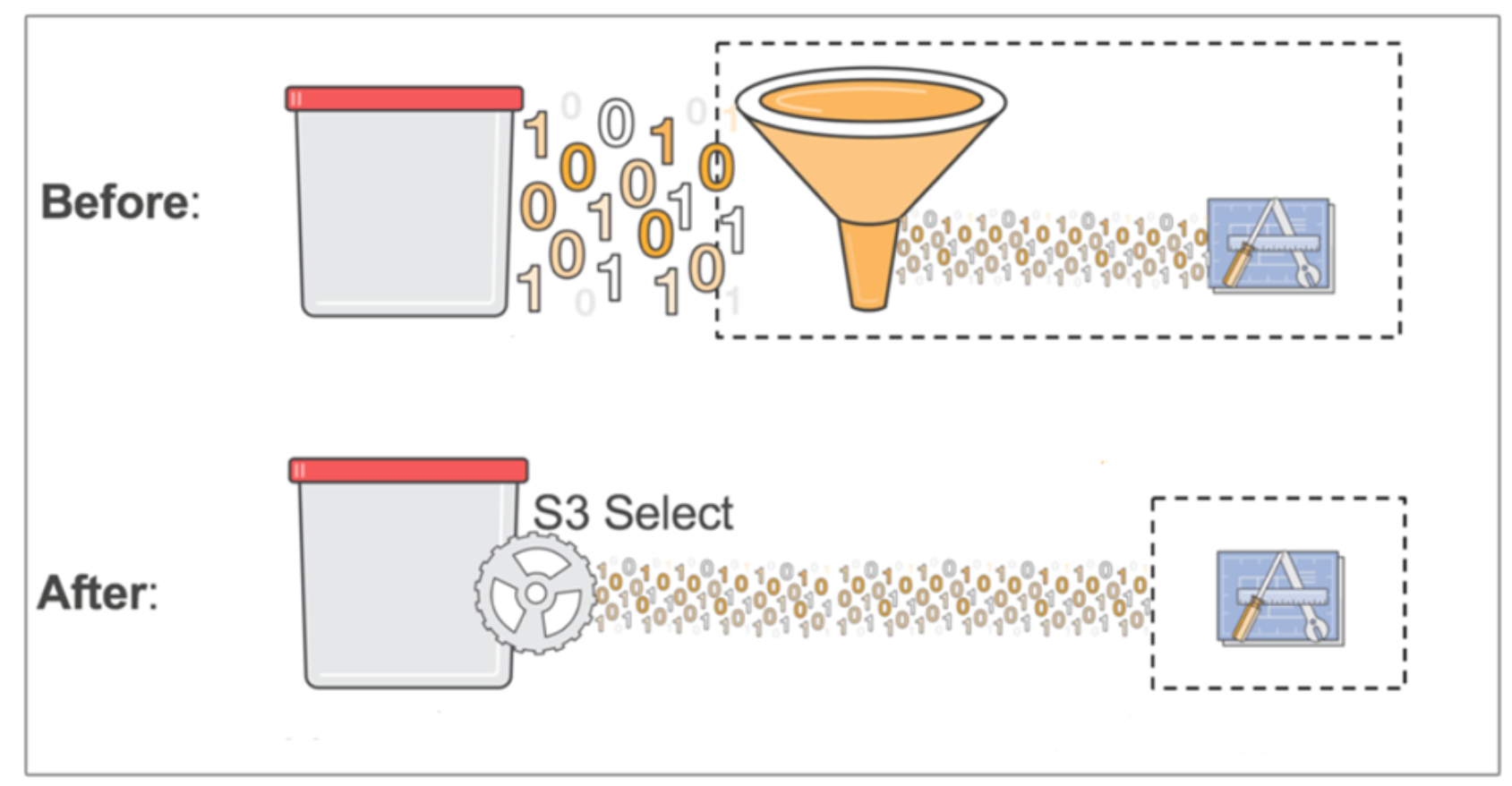
Figure 12. S3 select
S3 select can be used for objects in the csv, json, and parquet formats. It supports querying gzip/bzip2 compressed objects of these three file types.
S3 select is commonly used by query engines, like presto. A connector in presto can determine if a particular query can be sent directly to storage. For example, s3 select pushdown.
AWS compliant S3 performs partial reads of an Object. This offloads query and sort to ECS rather than using compute resources. This may provide a performance benefit for use cases where network bandwidth and or compute resources are a bottleneck.
Note: S3 select is not enabled by default. It is suggested to enable it with 192GB of memory on each node. Contact your Dell support team if you need to enable this feature.
Data movement
Data movement, also called copy-to-cloud, is a new feature in ECS 3.8.0.1 where a user can copy local object data to an external S3 target, such as a secondary ECS that is not federated, or to a public cloud target. (Currently, only AWS targets are supported).
Data movement is configured as a bucket option in the UI, as shown in the following figure. It can be monitored by an account admin or system admin within the UI. The admin can define policies about source and target buckets and criteria for objects. The admin can also monitor the logs for all copy operations at the object level, including the copy time, source object key, object size, target endpoint, duration, and result of the copy operation (success/failure, error message). There are also alerts that show a summary of all copy operations and errors on any failures.
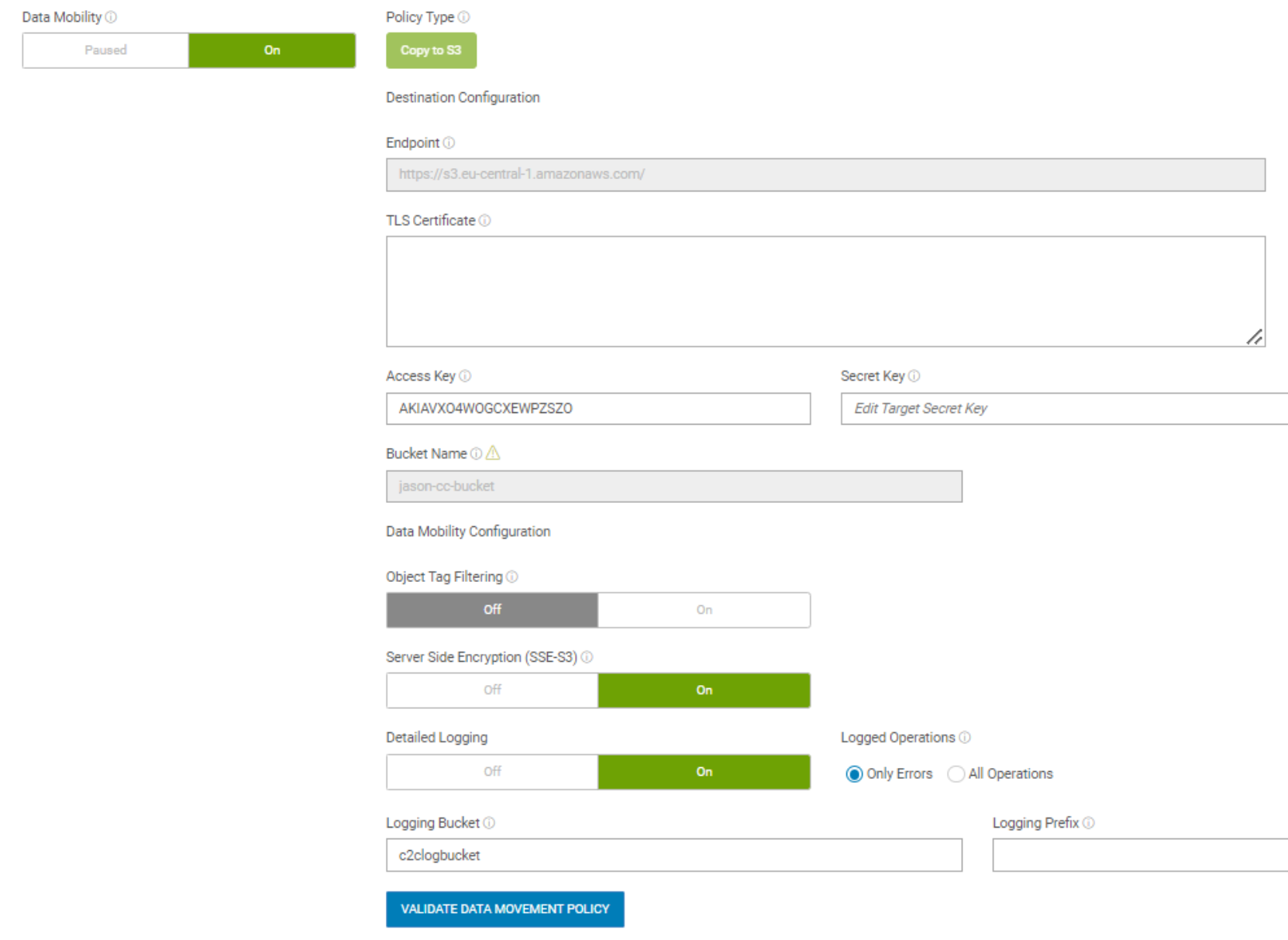
Figure 13. Config data movement in a bucket
The data movement service can only run in Gen2 or later that have been upgraded to 192GB memory. It can only exist on IAM enabled buckets. Data movement policies cannot sync deletes. This means that if an object is deleted from the source bucket, it will not be deleted from the target bucket. The default scan interval (transfer frequency) is one hour. The metadata search with LastModified index must be enabled in the bucket as shown in the following figure.
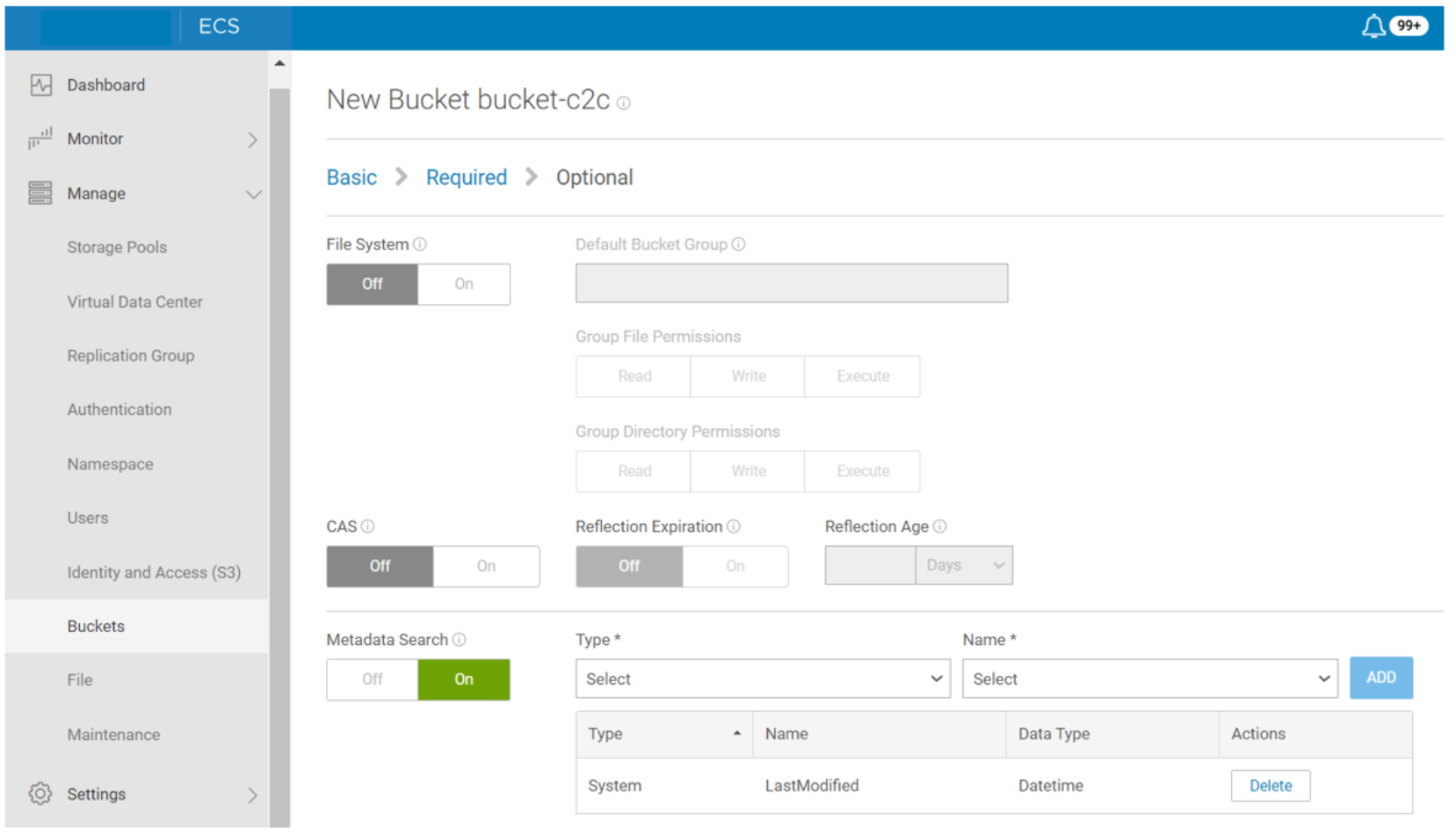
Figure 14. Enable metadata search with LastModified
With a versioning enabled bucket, only the current version at the time of policy job execution will be copied. File system (FS) enabled buckets are not supported because FS buckets do not support IAM access.
We are extending our ecosystem to support a multi-cloud experience for Snowflake which runs on public clouds in AWS. Dell and Snowflake customers can use on-premises data stored on Dell ECS while keeping their data local or seamlessly copying it to public clouds to leverage Snowflake’s ecosystem of cloud-based data analysis services.
The following workflow shows how Snowflake works with ECS Data movement:
- An application writes data to an ECS local bucket.
- A data movement policy in ECS is configured to copy all or a subset of the data to a customer owned predefined staging bucket within AWS.
- Data is written to the staging bucket.
- This bucket will have S3 notifications set up to notify a customer owned AWS SQS queue to which Snowflake is subscribed.
- A Snowflake data pipeline process called Snowpipe wakes up and ingests the data into Snowflake.
- Data can then be deleted according to lifecycle policy in AWS.
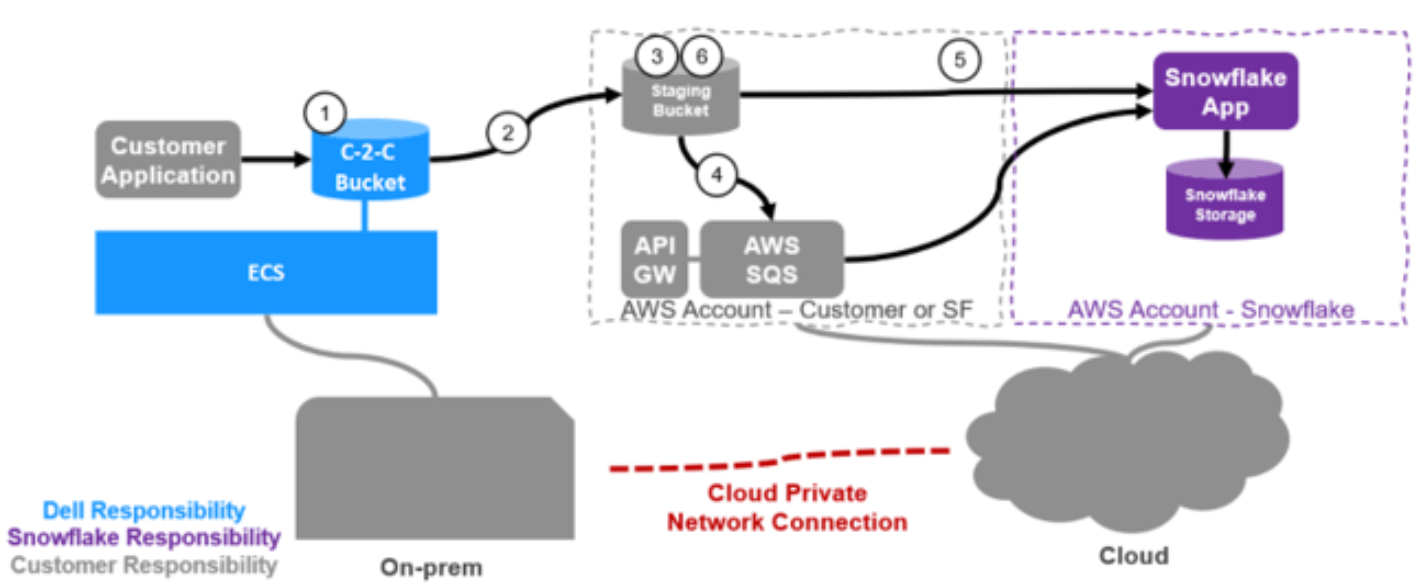
Figure 15. Data movement with Snowflake