
Multisite deployment
Multisite deployment
-
A multisite deployment, also referred to as a federated environment or federated ECS, may span across up to eight VDCs. Data is replicated in ECS at the chunk level. Nodes participating in an RG send their local data asynchronously to one or all other sites. Data is encrypted using AES256 before it is sent across the WAN over HTTP. Key benefits recognized when federating multiple VDCs are:
- Consolidation of multi-VDC management efforts into a single logical resource
- Site-level protection in addition to locally to the node-, disk- and rack-level
- Geographically distributed access to storage in an everywhere-active strongly-consistent manner
This section on multisite deployment describes features specific to federated ECS such as:
- Data consistency - By default ECS provides a strongly-consistent storage service.
- Replication Groups - Global containers used to designate protection and access boundaries.
- Geo-caching - Optimization for remote-site access workflows in multisite deployments.
- ADO - Client access behavior during temporary site outage (TSO).
Data consistency
ECS is a strongly consistent system that uses ownership to maintain an authoritative version of each namespace, bucket, and object. Ownership is assigned to the VDC where the namespace, bucket or object is created. For example, if a namespace, NS1, is created at VDC1, VDC1 owns NS1 and responsible for maintaining the authoritative version of buckets inside NS1. If a bucket, B1, is created at VDC2 inside NS1, VDC2 owns B1 and responsible for maintaining the authoritative version of the bucket contents and each object’s owner VDC. Similarly, if an object, O1, is created inside B1 at VDC3, VDC3 owns O1 and is responsible for maintaining the authoritative version of O1 and associated metadata.
The resiliency of multisite data protection comes at the expense of increased storage protection overhead and WAN bandwidth consumption. Index queries are required when an object is accessed or updated from a site that does not own the object. Similarly index lookups across the WAN are also required to retrieve information such as an authoritative list of buckets in a namespace or objects in a bucket, owned by a remote site.
Understanding how ECS uses ownership to authoritatively track data at the namespace, bucket, and object level helps administrators and application owners make decisions in configuring their environment for access.
Active replication group
During RG creation a Replicate to All Sites setting is available which is either left off, by default, or can be toggled on which enables this feature. Replicating data to all sites means that data written individually to each VDC is replicated to all other RG member VDCs. For example, a federated X-number-of-sites ECS instance with an active RG configured to replicate data to all sites will result in X times protection overhead, or X * 1.33 (or 1.2 in cold archive EC) total data protection overhead. Replicating to all sites may make sense especially for smaller data sets where local access is important. Leaving this setting off means that all data written to each VDC will be replicated to one other VDC. The primary site, where on object is created, and the site storing the replicate copy, each protect the data locally using the EC schema assigned to the local SP. That is, that only the original data is replicated across the WAN and not any associated EC coding segments.
Data stored in an active RG is accessible to clients by any available RG member VDC. The following figure shows an example of a federated ECS built using VDC1, VDC2, and VDC3. Two RGs are shown, RG1 has a single member, VDC1, and RG2 has all three VDCs as members. Three buckets are shown, B1, B2, and B3.
In this example:
- Clients accessing VDC1 have access to all buckets
- Clients accessing VDC2 and VDC3 have access only to buckets B2 and B3.
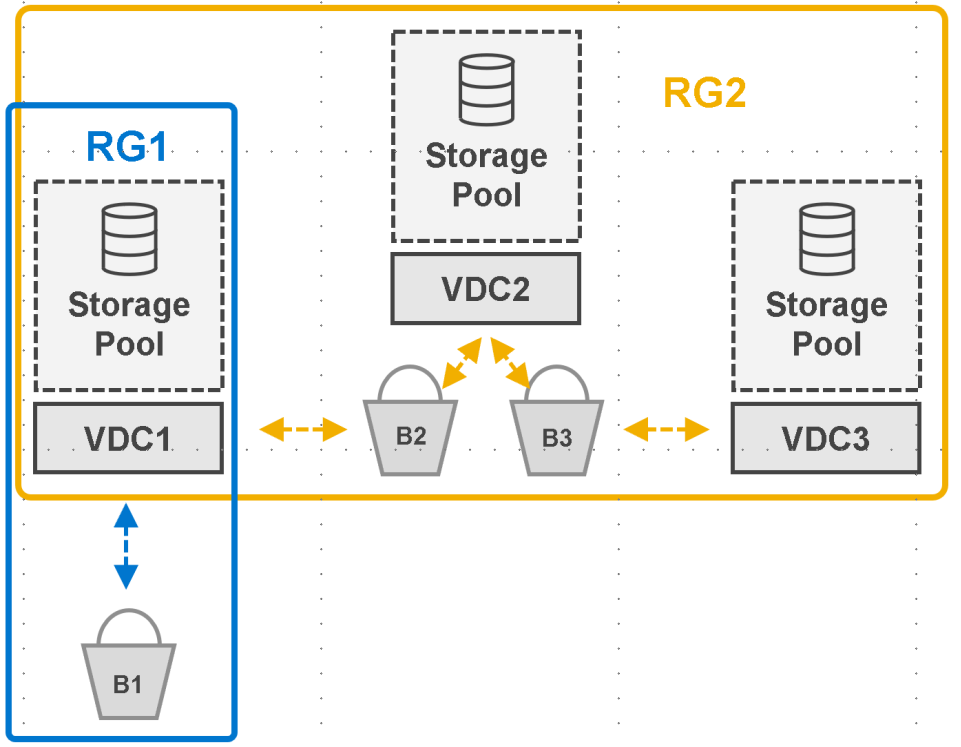
Figure 23. Bucket-level access by site with single site and multisite replication groups
Passive replication group
A passive RG has three member VDCs. Two of the VDCs are designated as active and are accessible to clients. The third VDC is designated passive and used as a replication target only. The passive site is used for recovery purposes only and does not allow for direct client access. Benefits of geo-passive replication are:
- Decrease in storage protection overhead by increasing the potential for XOR operations
- Administrator-level control of the location used for replicate-only storage
The following figure shows an example of a geo-passive configuration whereby VDC 1 and VDC 2 are primary (source) sites that both replicate their data (chunks) to the replication target, VDC 3:
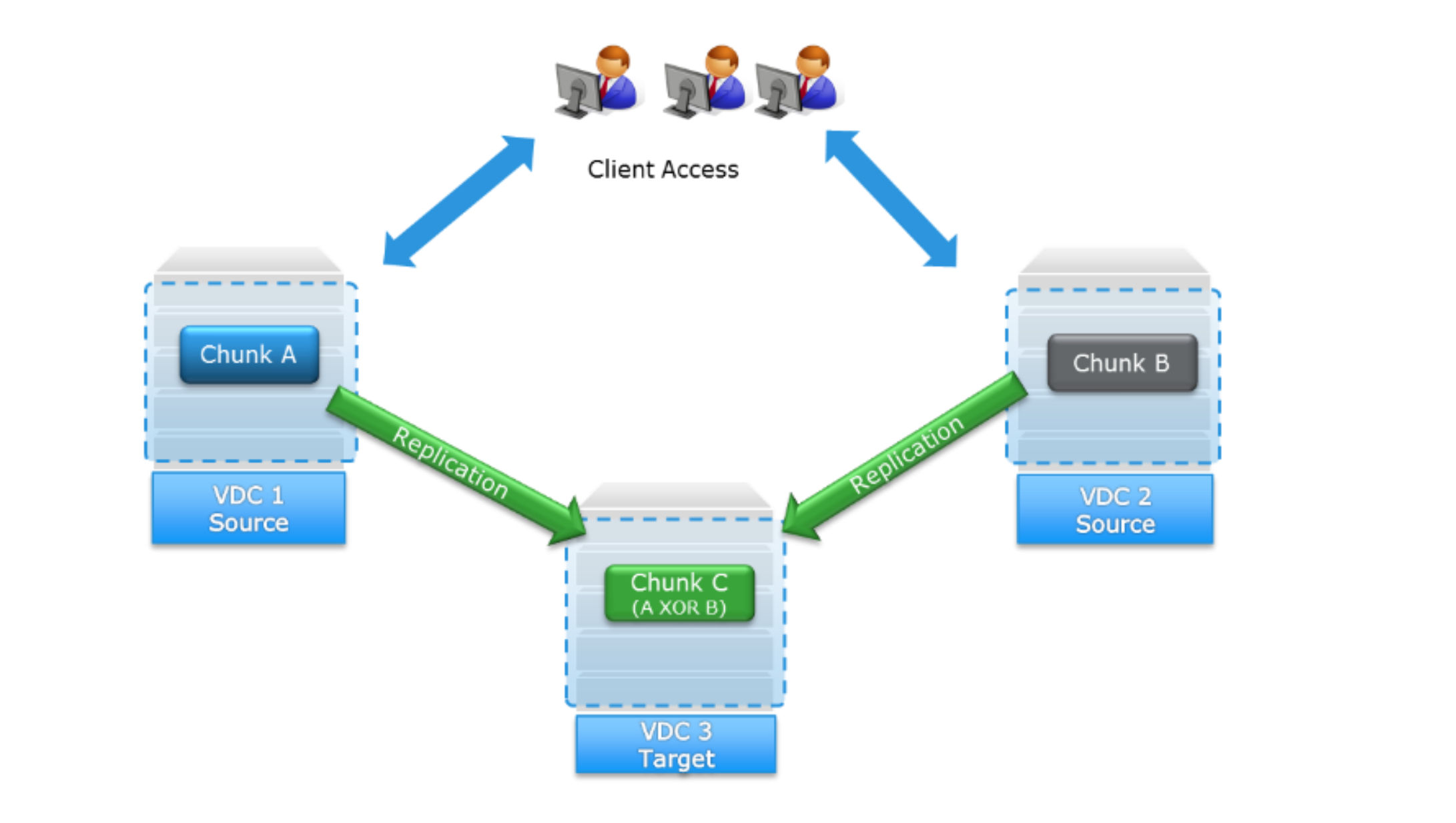
Figure 24. Client access and replication paths for geo-passive replication group
Multisite access to strongly-consistent data is accomplished using namespace, bucket, and object ownership across RG member sites. Inter-site across-the-WAN index queries are required when API access originates from a VDC that does not own the required logical construct(s). WAN lookups are used to determine the authoritative version of data. Thus, if an object created in Site 1 is read from Site 2, a WAN lookup is required to query the object’s owner VDC, Site 1, to verify if the object’s data that has been replicated to Site 2 is the latest version of the data. If Site 2 does not have the latest version, it fetches the necessary data from Site1; otherwise, it uses the data previously replicated to it. This is illustrated in the following figure:
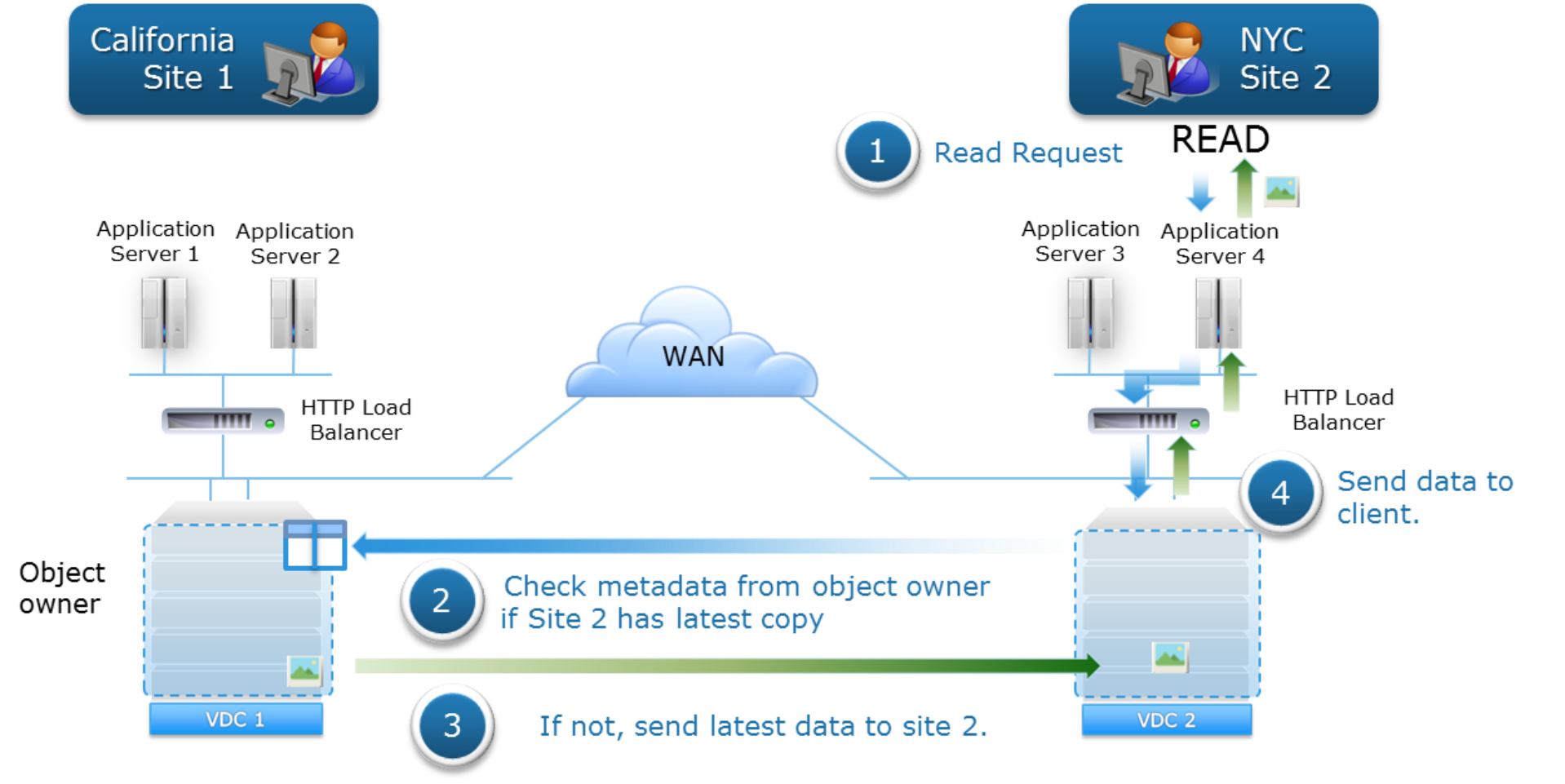
Figure 25. Read request to non-owner VDC triggers WAN lookup to object-owner VDC
The following figure shows the data flow of writes in a geo-replicated environment in which two sites are updating the same object. In this example, Site 1 initially created and owns the object. The object has been erasure-coded and the related journal transactions written to disk at Site 1. The data flow for an update to the object received at Site 2 is as follows:
- Site 2 first writes the data locally.
- Site 2 synchronously updates the metadata (journal write) with the object owner, Site 1, and waits for acknowledgment of metadata update from Site 1.
- Site 1 acknowledges the metadata write to Site 2.
- Site 2 acknowledges the write to the client.
Note: Site 2 asynchronously replicates the data Site 1, the object owner site, as usual. If the data must be served from Site 1 before it is replicated to it from Site 2, Site 1 will retrieve the data directly from Site 2.
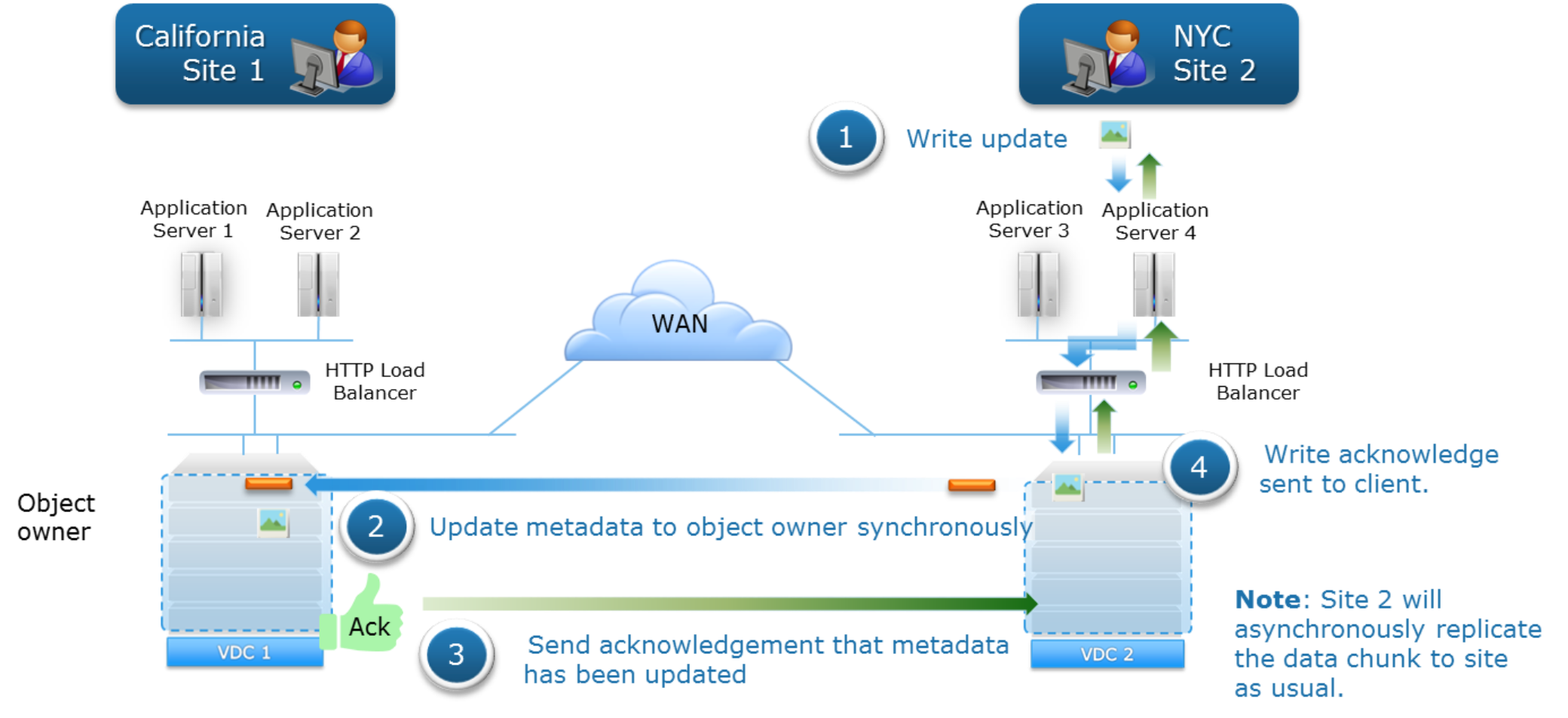
Figure 26. Update of the same object data flow in geo-replicated environment
In both read and write scenarios in a geo-replicated environment, there is latency involved in reading and updating the metadata and retrieving data from the object-owner site.
Note: Starting from ECS 3.4, you can remove a VDC from a replication group (RG) in a multi VDC federation without affecting the VDC or other RGs associated with the VDC. Removing VDC from RG no longer initiates PSO (permanent site outage). Removing a VDC from RG initiates recovery.
See the latest ECS Administrator Guide for further information about Replication Group.
Geo-caching remote data
ECS optimizes response times for accessing data stored on remote sites by locally caching objects read across the WAN. This can be useful for multi-site access patterns where data is often fetched from a remote, or non-owner site. Consider a geo-replicated environment with three sites, VDC1, VDC2 and VDC3, where an object is written to VDC1 and the replicate copy of the object is stored at VDC2. In this scenario, to service a read request received at VDC3, for the object created at VDC1 and replicated to VDC2, the object data must be sent to VDC3 from either VDC1 or VDC2. Geo-caching frequently accessed remote data helps reduce response times. A Least Recently Used algorithm is used for caching. Geo-cache size is adjusted when hardware infrastructure such as disks, nodes, and racks are added to a geo-replicated SP.
Behavior during site outage
Temporary site outage (TSO) generally refers to either a failure of WAN connectivity or of an entire site such as during a natural disaster. ECS uses heartbeat mechanisms to detect and handle temporary site failures. Client access and API-operation availability at the namespace, bucket, and object levels during a TSO is governed the following ADO options set at the namespace and bucket level:
- Off (default) - Strong consistency is maintained during a temporary outage.
- On - Eventually consistent access is allowed during a temporary site outage.
Data consistency during a TSO is implemented at the bucket level. Configuration is set at the namespace level, which sets the default ADO setting in place for ADO during new bucket creation. This can be overridden at new bucket creation. This means that TSO can be configured for some buckets and not for others.
Access during outage (ADO) not enabled
By default, ADO is not enabled, and strong consistency is maintained. All client API requests where authoritative namespace, bucket or object data is required but temporarily unavailable will fail. Object operations to read, create, update, delete, and list buckets not owned by an online site, will fail. Also, operations of create and edit of bucket, user, and namespace will also fail.
As previously mentioned, the initial site owner of bucket, namespace and an object, is the site where the resource was first created. During a TSO, certain operations may fail if the site owner of resource is not accessible. Highlights of operations permitted or not permitted during a temporary site outage include:
- Creation, deletion, and update of buckets, namespaces, object users, authentication providers, RGs, and NFS user and group mappings are not allowed from any site.
- Listing buckets within a namespace is allowed if the namespace owner site is available.
NFS enables buckets that are owned by the inaccessible site are read-only.
ADO enabled
In an ADO-enabled bucket, during a TSO, the storage service provides eventually consistent responses. In this scenario reads and optionally writes from a secondary (non-owner) site are accepted and honored. Further, a write to a secondary site during a TSO causes the secondary site to take ownership of the object. This allows each VDC to continue to read and write objects from buckets in a shared namespace. Finally, the new version of the object becomes the authoritative version of the object during post-TSO reconciliation even if another application updates the object on the owner VDC.
Although many object operations continue during a network outage, certain operations are not be permitted, such as creating new buckets, namespaces, or users. When network connectivity between two VDCs is restored, the heartbeat mechanism automatically detects connectivity, restores service and reconciles objects from the two VDCs. If the same object is updated on both VDC A and VDC B, the copy on the non-owner VDC is the authoritative copy. So, if an object that is owned by VDC B is updated on both VDC A and VDC B during synchronization, the copy on VDC A will be the authoritative copy that is kept, and the other copy will be un-referenced and available for space reclamation.
When more than two VDCs are part of an RG, and if network connectivity is interrupted between one VDC and the other two, then write/update/ownership operations continue just as they would with two VDCS; however, the process for responding to read requests is more complex, as described below.
If an application requests an object that is owned by a VDC that is not reachable, ECS sends the request to the VDC with the secondary copy of the object. However, the secondary site copy might have been subject to a data contraction operation, which is an XOR between two different data sets that produces a new data set. Therefore, the secondary site VDC must first retrieve the chunks of the object included in the original XOR operation and it must XOR those chunks with the recovery copy. This operation will return the contents of the chunk originally stored on the failed VDC. The chunks from the recovered object can then be reassembled and returned. When the chunks are reconstructed, they are also cached so that the VDC can respond more quickly to subsequent requests. Note reconstruction is time consuming. More VDCs in an RG imply more chunks that must be retrieved from other VDCss, and hence reconstructing the object takes longer.
If a disaster occurs, an entire VDC can become unrecoverable. ECS treats the unrecoverable VDC as a temporary site failure. If the failure is permanent, the system administrator must permanently failover the VDC from the federation to initiate fail over processing, which initiates resynchronization and re-protection of the objects stored on the failed VDC. The recovery tasks run as a background process. You can review the recovery progress in the ECS Portal.
An additional bucket option is available for read-only (RO) ADO which ensures object ownership never changes and removes the chance of conflicts otherwise caused by object updates on both the failed and online sites during a temporary site outage. The disadvantage of RO ADO is that during a temporary site outage no new objects can be created and no existing objects in the bucket can be updated until after all sites are back online. The RO ADO option is available during bucket creation only, it cannot be modified afterwards. By default, this option is disabled.
Note: Starting in 3.8.1, there is an option to enable CAS read operations on the target system which is similar to eventual consistency. Please refer to the Administration Guide for more details.