
Failure tolerance
Failure tolerance
-
ECS is designed to tolerate a range of equipment failure situations using a number of fault domains. The range of failure conditions spans a varying scope including:
- Single hard drive failure in a single node
- Multiple hard drive failure in a single node
- Multiple nodes with single hard drive failure
- Multiple nodes with multiple hard drive failures
- Single node failure
- Multiple node failure
- Loss of communication to one replicated VDC
- Loss of one entire replicated VDC
In either a single site, dual-site, or geo-replicated configuration, the impact of the failure depends on the quantity and type of components affected. However, at each level, ECS provides mechanisms to defend against the impact of component failures. Many of these mechanisms have already been discussed in this paper but are reviewed here and in the following figure to show how they are applied to the solution. These include:
- Disk failure
- EC segments or replica copies from the same chunk are not stored on the same disk
- Checksum calculation on write and read operations
- Background consistency checker re-verifying checksums
- Node failure
- Distribute segments or replica copies of a chunk equally across nodes in a VDC
- ECS Fabric keeps services running and manages resources such as disks and network.
- Partition records and tables protected by partition ownership failover from node to node.
- Rack failure within VDC
- Distribute segments of replica copies of a chunk equally across racks in a VDC[BJ6][ZJ7][BJ8][ZJ9][BJ10].
- One fabric registry instance runs in each rack and can be restarted on any other node in the same rack should the node fail.
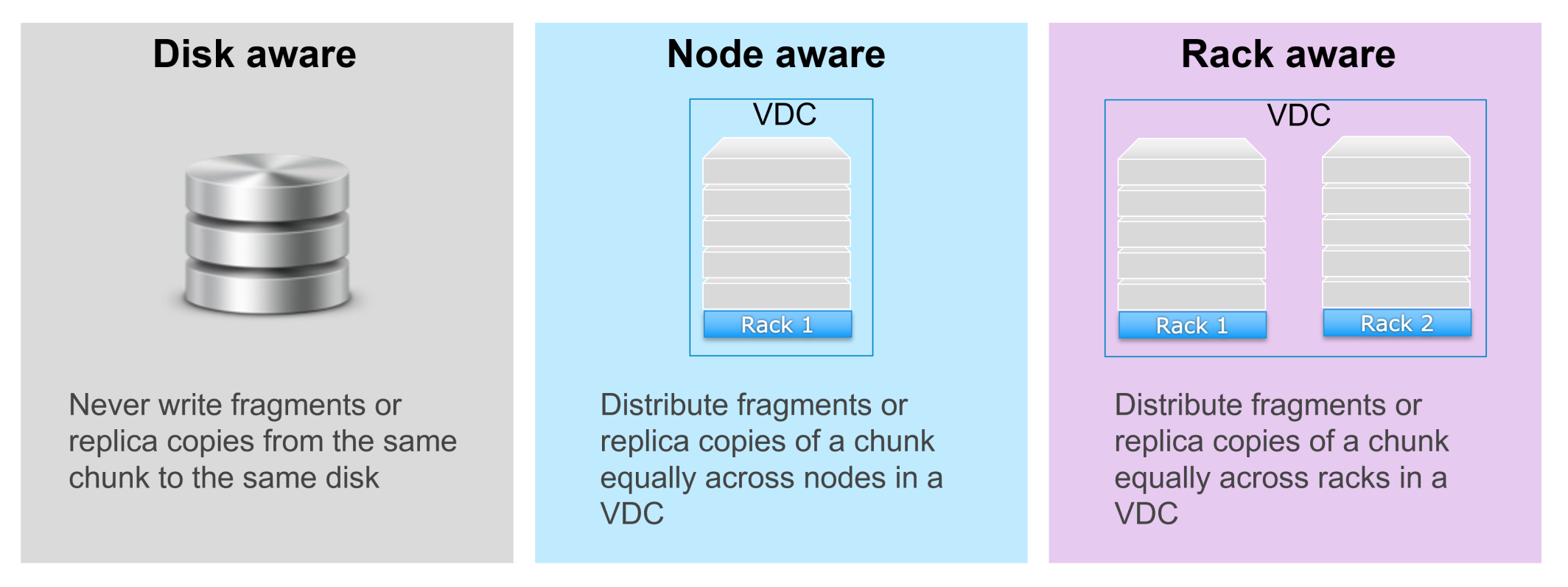
Figure 27. Protection mechanisms at the disk, node, and rack levels
Note: For the rack aware, when adding new rack to the exist cluster, some of the data will be moved to the new rack to balance the data across all the racks equally. However, the process could take a long period of time to avoid having a performance impact on the system. If the customer keeps writing aggressively and fills the first rack, then all the new writes will happen only on the new rack.
The following table defines the type and number of component failures that each EC scheme protects against per basic rack configuration. The table highlights the importance of considering the impact of protective failure domains on overall data and service availability in terms of number of nodes required at each EC scheme.
Table 10. Erasure code protection across failure domains
EC scheme
# nodes in VDC
# chunk fragments per node
EC data protected against…
12+4
Default
5 or less
4
- Loss of up to four disks or
- Loss of one node
6 or 7
3
- Loss of up to four disks or
- Loss of one node and one disk from a second node
8 or more
2
- Loss of up to four disks or
- Loss of two nodes or
- Loss of one node and two disks
15
one node with 2 fragments and other nodes with 1 fragment.
- Loss of up to four disks or
- Loss of three nodes or
- Loss of two nodes and one disk or
- Loss of one node and two disks
16 or more
1
- Loss of four nodes or
- Loss of three nodes and disks from one additional node or
- Loss of two nodes and disks from up to two different nodes or
- Loss of one node and disks from up to three different nodes or
- Loss of four disks from four different nodes
10+2
Cold Storage
11 or less
2
- Loss of up to two disks or
- Loss of one node
12 or more
1
- Loss of any number of disks from two different nodes or
- Loss of two nodes