
Solution concepts
Solution concepts
-
Overview
This section discusses the concepts involved in building the solution. The following list includes the hardware and software layers in the solution stack.
- AMD-based Dell PowerEdge servers.
- Red Hat OpenShift Container Platform.
- Red Hat OpenShift Data Foundation.
- Dell ObjectScale
- Microsoft SQL Server 2022
- Apache Spark and Delta Lake
Data Lakehouse
A traditional data lake tends to be a flexible and cost-effective implementation by storing data in its raw form typically unstructured or semi-structured. A data warehouse is a more advanced repository that stores structured data for reporting and analysis, typically cleansed and optimized for better data quality and querying.
A data lakehouse is a modern data platform that combines the flexibility low cost, and scalability of data lakes with the ACID transaction, data management, and data querying capability of the data warehouse to provide a centralized repository for all data.
A data lakehouse supports diverse datasets such as structured, semi-structured, and unstructured data, meeting the needs of both business intelligence and data science use cases. It typically supports programming languages like Python, R, and SQL.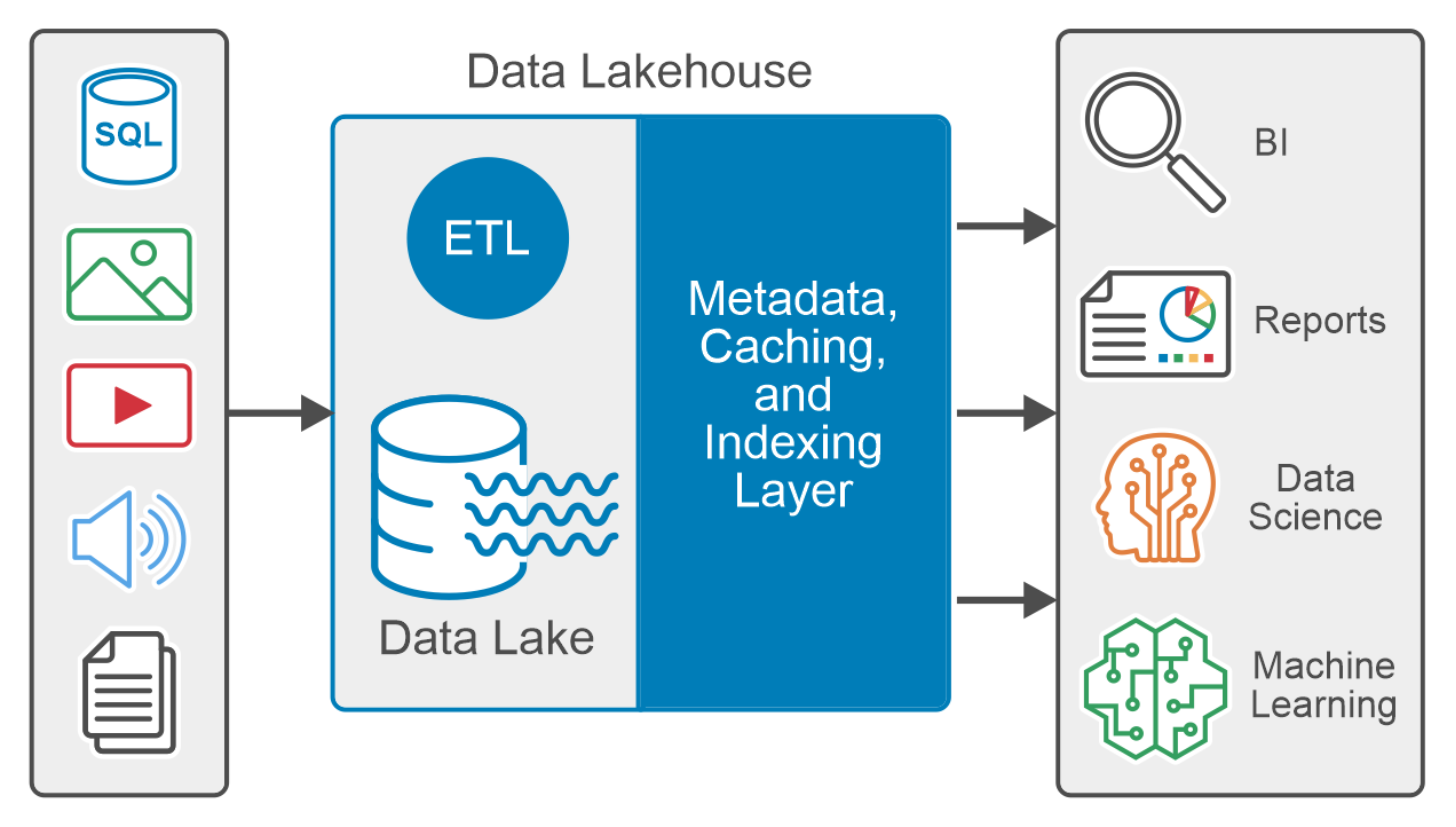 Figure 1. Data Lakehouse logical diagram
Figure 1. Data Lakehouse logical diagramThe metadata layer, like the open-source Delta Lake, is the foundation of the data lakehouse architecture. The metadata layer is a unified catalog that maintains metadata for every object in the data lake storage, which helps to organize and provide information about the data in the system. The metadata layer enables other features common in data lakehouse, like support for ACID transactions, streaming, caching hot data, time travel, schema enforcement, evolution, and data validation.
Data virtualization
Data virtualization is a data management methodology that enables applications to access and manipulate data without requiring technical knowledge of the source data, physical location, or the format.
Data virtualization involves abstracting multiple sources through a single data access layer. This enables organizations to integrate different types of data virtually. The integration is critical for data mining, analytics, and predictive analytics tools which use machine learning (ML) and artificial intelligence (AI).
Dell ObjectScale
Dell ObjectScale is a software-defined, containerized architecture that delivers enterprise-class, high-performance object storage in a Kubernetes-native environment. ObjectScale empowers organizations with the ability to put data closer to the applications they support, reducing latency and improving the user experience. Dell ObjectScale is the foundation that provides support to store, manipulate, and analyze unstructured data on a very large scale.
Dell ObjectScale is built on a Kubernetes platform, to deliver a simplified product where operating system and hardware-level layers are managed by Kubernetes and ObjectScale manages the storage.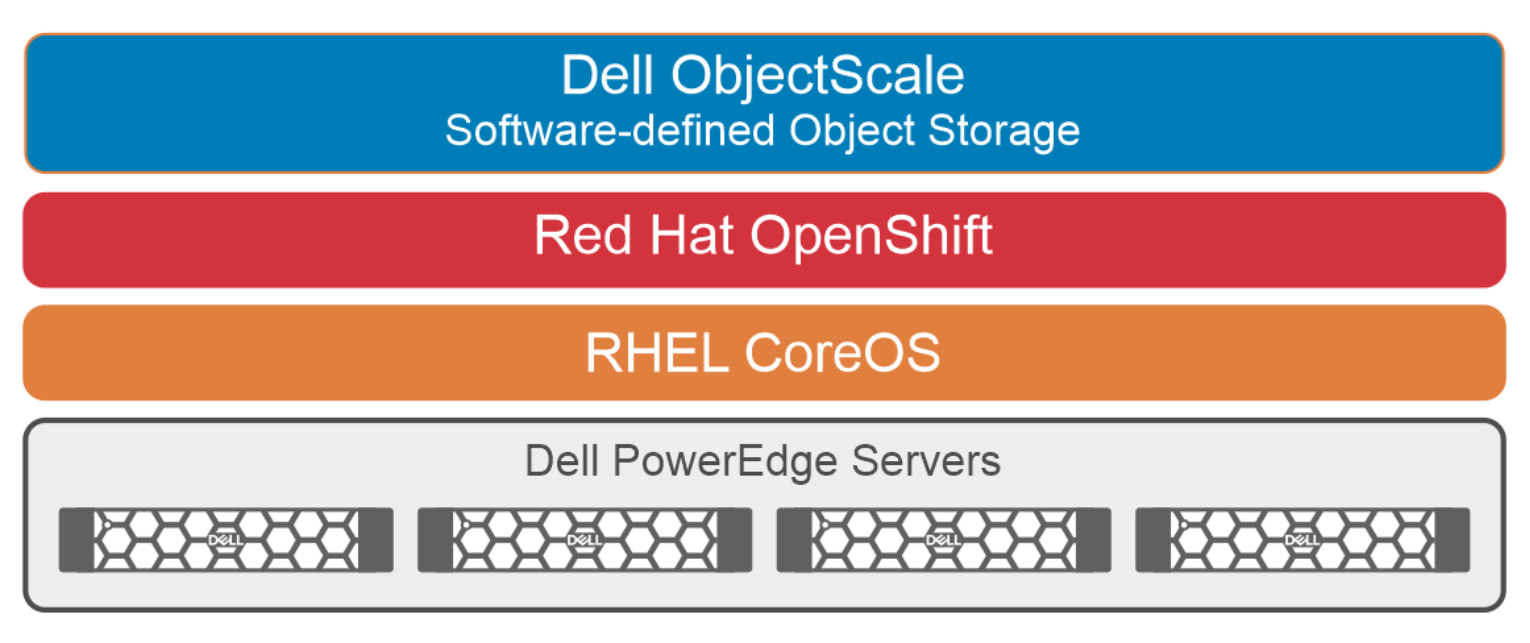 Figure 2. Dell ObjectScale physical architecture
Figure 2. Dell ObjectScale physical architectureObjectScale is a next-generation object storage software that is lighter, faster, and deployable on existing infrastructure. It can be deployed on the Red Hat OpenShift Container Platform or SUSE Linux Enterprise Server (SLES) infrastructure. ObjectScale allows organizations to deliver scalable cloud services with the reliability and control of a private cloud infrastructure.
Key features of ObjectScale include:
- Kubernetes native, customer-deployable
- Rich S3 compatibility
- Self-service APIs help in the quick spin-up of object storage containers
- Scalability
- Built as a scaled-out, software-defined architecture, following the microservices principle of cloud applications
- Data protection
- Geo-replication
- Superior performance irrespective of the size of an object
The following list describes some of the benefits that Kubernetes provides for ObjectScale:
- Dynamic scaling of resources
- Deployment using minimal required resources
- Highly portable
- Self-healing: Auto placement, auto restart, and auto replication
For more information, see the Dell ObjectScale webpage.