
Partner technology overview
Partner technology overview
-
Red Hat OpenShift Container Platform
RHOCP is a consistent hybrid cloud foundation for containerized applications, powered by Kubernetes. Using RHOCP Developers and DevOps engineers can quickly build, modernize, deploy, run, and manage applications anywhere, securely, and at scale.
RHOCP is powered by open-source technologies and offers flexible deployment options ranging from physical, virtual, private, and public cloud, and at the Edge. RHOCP cluster consists of one or more control-plane nodes and a set of worker nodes.
For more information about RHOCP, see the Red Hat webpage.
Red Hat OpenShift Data Foundation
RHODF is a highly available software-defined, persistent storage and cluster data management solution integrated with and optimized for the Red Hat OpenShift Container Platform. RHODF allows the provision and management of file, block, and object storage for containerized workloads, from the same underlying raw block storage.
RHODF runs anywhere OpenShift runs such as on-premises, private, or public cloud environments, and at the edge, and provides a consistent experience, irrespective of the underlying infrastructure. Organizations can extend and federate data across multiple infrastructures using multicloud data management capabilities.
RHODF is deployed, consumed, and managed through the OpenShift administrator console. This platform is built on Red Hat Ceph storage, offering tightly integrated persistent data services for OpenShift environments. RHODF supports a broad range of diverse workloads and applications including analytics, and AI/ML.
For more information, see the Red Hat webpage.
AMD processor
The 4th Generation AMD EPYC processors have been engineered to provide optimization capabilities across various market segments and applications. By doing so, businesses can effectively allocate data center resources to facilitate additional workload processing and expedite output.
For the SQL Server 2022 database instances, we opted for AMD EPYC 9334 processors in this exercise. This decision was made based on the requirement for fast response time when running T-SQL queries for data analytics. The AMD EPYC 9334 processors are equipped with 32 cores per socket, operating at a default speed of 2.7 GHz, and offer an L3 cache size of up to 1152 MB per socket. These specifications provide the necessary horsepower to handle any data analytic workloads.
For more information about AMD EPYC, see the AMD webpage.
Microsoft SQL Server 2022
Microsoft SQL Server 2022 is a robust database platform that includes many new features that enhance its capabilities as a leading relational database management system.
The analytics feature of Microsoft SQL Server 2022 is a game-changer for organizations seeking to extract valuable insights from disparate data sources. This feature introduces object storage integration to the data platform, enabling users to seamlessly integrate SQL Server with S3-compatible object storage.
PolyBase technology has been enhanced in SQL Server 2022. This technology significantly reduces data transfer and transformation processes such as extract, transform, and load (ETL) by allowing data to remain in its source location and format. It empowers businesses to run T-SQL queries across relational databases, big data systems, and cloud-based data sources.
For more information about Microsoft SQL Server 2022 and the PolyBase feature, see the Microsoft webpage.
Apache Spark
Apache Spark is an open-source distributed data-processing engine used for big data. It can handle both batch and real-time analytics and data processing workloads. It is designed to deliver the computational speed, scalability, and programmability required for big data applications.
One of the main features of Apache Spark is its in-memory computing which increases the processing speed for any application. Apache Spark is designed to cover a wide range of workloads such as batch processing, interactive queries, and streaming. Apart from supporting all these workloads in a system, it also reduces the management burden of maintaining multiple tools.
For more information about Apache Spark, see the Spark webpage.
Delta Lake
A Delta Lake is an open-source storage layer that brings reliability, security, and performance to the data lake. Delta Lake runs on top of your existing data lake and supports ACID transactions, scalable metadata handling, and unified streaming and batch data processing.
It enables building a Lakehouse architecture with compute engines including Spark, PrestoDB, Flink, Trino, and Hive and APIs for Scala, Java, Rust, and Python.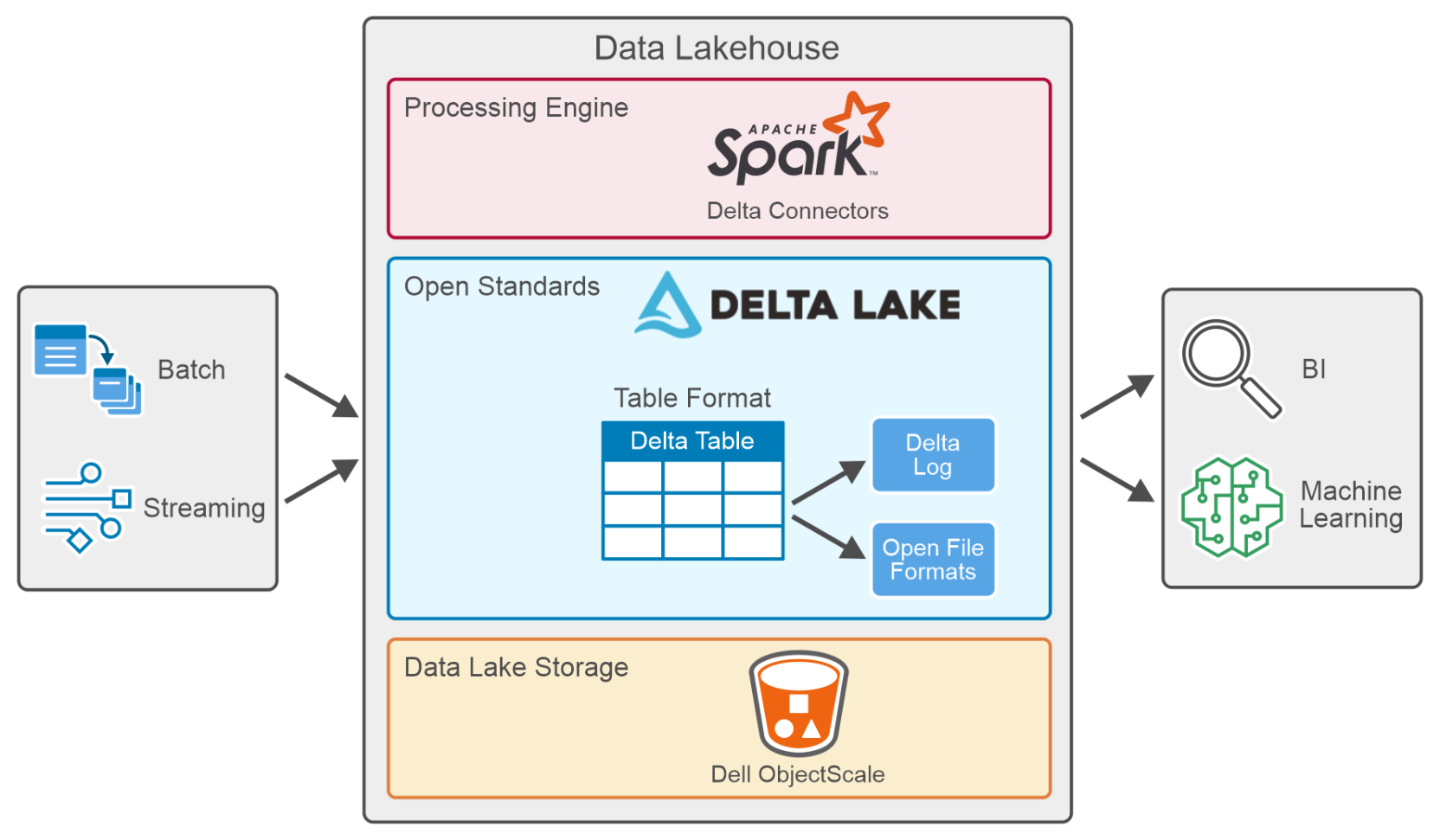 Figure 3. Data Lakehouse data processing
Figure 3. Data Lakehouse data processingA table in Delta Lake (Delta Table) is stored in open formats such as Parquet files along with a file-based transaction log stored in JSON format, for ACID transactions and scalable metadata handling.
A delta connector is a library that allows external applications to read from and write to Delta tables. Delta connectors are available for various popular big data frameworks, including Apache Spark, Apache Hive, and Apache Flink.
Key features defining Delta Lake include:
- ACID transactions: ACID properties ensure that data never falls into a bad data quality because of a transaction that failed or partially completed and provides data reliability and integrity. Delta Lake keeps track of all the commits made to the delta table in a transaction log to implement ACID Transactions.
- Scalable metadata: Handles terabytes or even petabytes of table data with ease. Metadata is stored just like any other data and handled by Delta Lake.
- Time travel (data versioning): Delta Lake allows users to access and analyze previous versions of data using time travel capabilities for querying, auditing, and rollback. It also enables data exploration and analysis at different points in time, making it easier to identify trends, track changes and perform historical analysis.
- Unified batch and stream processing: Every table in a Delta Lake is a batch and streaming sink. Additionally, with efficient metadata handling, ease of scale, and ACID transactions, near-real-time analytics become possible without using a more complicated two-tiered data architecture.
- Schema enforcement: Delta Lake automatically handles schema variations to prevent insertion of bad records during data ingestion.
- Schema evolution: Delta Lake supports schema evolution, allowing users to evolve the schema of their data over time.
- Audit history: Delta Lake logs all changes to the transaction log and provides historical audit trails.
- DML operations: Delta Lakes supports DML operations like updates, deletes, and merges, which play a crucial role in complex data operations.
- Open source: Community-driven, open standards, open protocol, open file format, and open discussions.
For more information about Delta Lake, see the Delta IO webpage.