
Enabling entitled builds
Enabling entitled builds
-
The NVIDIA GPU Operator deploys several pods that are used to manage and enable GPUs for use in OpenShift Container Platform. Some of these pods require packages that are not available by default in the Universal Base Image (UBI) that OpenShift Container Platform uses. To make packages available to the NVIDIA GPU driver container, you must enable cluster-wide entitled container builds in OpenShift.
At a high level, enabling entitled builds involves three steps:
- Download Red Hat OpenShift Container Platform subscription certificates from the Red Hat Customer Portal (access requires login credentials).
- Create a MachineConfig that enables the subscription manager and provides a valid subscription certificate. Wait for the nodes to reboot and then finish applying the MachineConfig.
- Validate that entitled builds are enabled.
The following sections elaborate on these steps. For more information about entitled builds in OpenShift, see this Red Hat blog post.
Download the subscription certificates
Obtain your subscription certificates under the Subscriptions tab in Red Hat Customer Portal, as shown in the following figure:
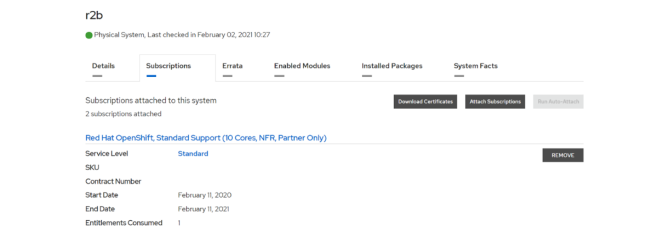
Figure 1. Downloading OpenShift subscription certificates
Extract the certificates file to the CSAH node
Run:
$ unzip cert_20210202.zip
$ ls
cert_20210202.zip consumer_export.zip openshift signature
$ unzip consumer_export.zip
Archive: consumer_export.zip
Candlepin export for beedde9c-a893-4a58-8313-4862e78806e5
inflating: export/meta.json
inflating: export/entitlement_certificates/6834535004259762316.pem
Create the entitlement MachineConfig
- Obtain the MachineConfig template by running the command:
- Generate the MachineConfig file by appending the entitlement certificate:
$ sed "s/BASE64_ENCODED_PEM_FILE/$(base64 -w 0 </path/to/certificate_file.pem>)/g" 0003-cluster-wide-machineconfigs.yaml.template > 0003-cluster-wide-machineconfigs.yaml
- Create the MachineConfig file, wait for the nodes to reboot, and then apply the configuration changes:
$ oc create -f 0003-cluster-wide-machineconfigs.yaml
Validate the entitled builds
- Download the validation pod yaml file and create the pod:
oc create -f 0004-cluster-wide-entitled-pod.yaml
- Examine the pod’s logging output by running:
oc logs cluster-entitled-build-pod
- Validate that the pod can locate the various kernel-devel packages, as shown in the following figure:
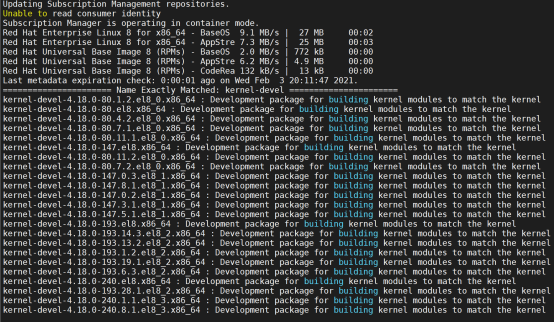
Figure 2. Locating the kernel-dev packages
Installing the NFD Operator
To install the NFD Operator, you must log in to the OpenShift cluster through the web console (see the Dell EMC Ready Stack for Red Hat OpenShift Container Platform 4.6 Deployment Guide). Follow these steps:
- Create a new project to manage the GPU resources:
$ oc new-project gpu-operator-resources
- From the web console, log into your OpenShift cluster, select Operators > OperatorHub, and then search for the NFD Operator.
The Install Operator page opens, as shown in the following figure:
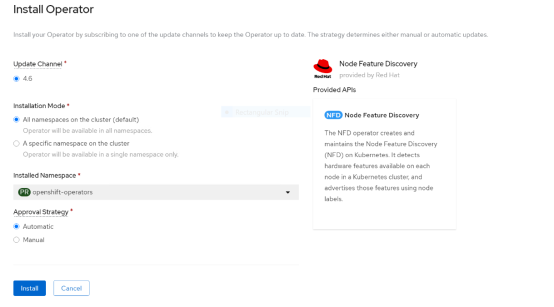
Figure 3. NFD Operator installation page
- Choose to install the operator in All namespaces on the cluster (default) and select Automatic under Approval Strategy.
- In the navigation pane, select Operators > Installed Operators, switch to the gpu-operator-resources namespace, and click NFD Operator.
- Click the Node Feature Discovery tile, and then click Create NodeFeatureDiscovery.
- Click Create to start the pods that are needed to label the nodes.
After the NFD pods have started running, more compute node labels are added.
- Validate that the GPU labels are present.
Note: Depending on the GPUs that you are using, the node label that the NFD generates might vary. The V100 GPUs in this example have the label
pci-de.present=true.Installing the NVIDIA GPU Operator
- Log in to the OpenShift web console, select Operators > OperatorHub, and then search for the NVIDIA GPU Operator.
- Choose to install the Operator in all namespaces in the cluster and select the automatic approval strategy.
- After the Operator is installed:
- Select Operators > Installed Operators, switch to the gpu-operator-resources project, and select the NVIDIA GPU Operator.
- Select the ClusterPolicy tab, click Create ClusterPolicy, and then click Create to start the NVIDIA GPU Operator pods.
- Under the gpu-operator-resources namespace, select Workloads > Pods and confirm that all NVIDIA GPU Operator pods are running or have completed, as shown in the following figure:
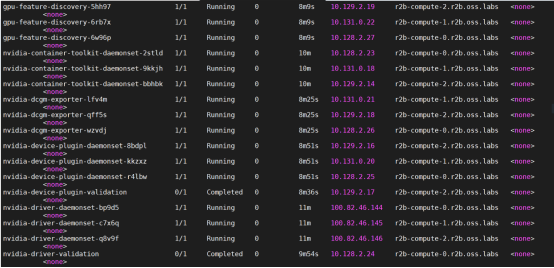
Figure 4. NVIDIA GPU Operator pods status
A new nvidia.com/gpu resource is displayed In the NodeSpec for nodes with GPUs.
- To confirm that the new resource is present, run:
oc get node <gpu_node> -o yaml | grep -i nvidia.com/gpu
The following output is displayed:
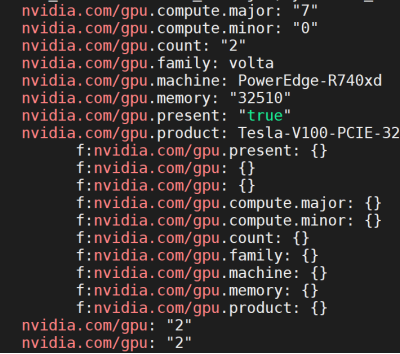
Figure 5. Resources present
Providing GPU resources to a pod
Pod Spec
apiVersion: v1
kind: Pod
metadata:
name: tensorflow-benchmarks-gpu
spec:
nodeSelector:
nvidia.com/gpu.product: Tesla-V100-PCIE-32GB
containers:
- image: nvcr.io/nvidia/tensorflow:19.09-py3
name: cudnn
command: ["/bin/sh","-c"]
args: ["git clone https://github.com/tensorflow/benchmarks.git;cd benchmarks/scripts/tf_cnn_benchmarks;python3 tf_cnn_benchmarks.py --num_gpus=2 --data_format=NHWC --batch_size=32 --model=resnet50 --variable_update=parameter_server"]
resources:
limits:
nvidia.com/gpu: 2
requests:
nvidia.com/gpu: 2
restartPolicy: Never
As shown in the sample Pod Spec, you can provide GPUs to pods by specifying the GPU resource nvidia.com/gpu and requesting the number of GPUs that you want. This number must not exceed the number of GPUs present on a specific node.
The NVIDIA GPU Operator also deploys gpu-feature-discovery pods on each compute node. The pod labels each node with information about the GPU type, family, count, and so on, as shown in the Pod Spec. These node labels can be used in the Pod Spec to schedule workloads based on criteria such as the GPU product name, as shown under nodeSelector.