
PowerEdge R650 Metadata performance with MDtest using empty files
PowerEdge R650 Metadata performance with MDtest using empty files
-
This section is different from the metadata performance in previous sections that are based on the HDMD module using the ME4024 array because one or more pairs of NVMe servers based on the PowerEdge R650 server with 10 NVMe direct attached devices replaces the HDMD module based on two PowerEdge R750 servers and one or more ME4024 arrays. This section addresses metadata performance on the new HDMD NVMe module with PowerEdge R650 NVMe servers for data. Metadata performance for the new HDMD NVMe module with ME-based storage for data will be documented for the next update of the pixstor solution using a new PowerVault array (ME5).
Metadata performance was measured with MDtest version 3.3.0, with by with OpenMPI 4.1.4rc1 to run the benchmark over the 16 compute nodes. The tests that we ran varied from single thread up to 512 threads. The benchmark was used for files only (no directories metadata), getting the number of create, stat, read, and remove operations that the solution can handle.
Several HDMD on NVMe Modules (NVMe R650 pairs) can be used to increase the number of files supported (inodes) and increase the metadata performance with each additional pair of servers. An exception to this increase might be stat operations (and read operations for empty files) because their numbers are high, and the CPUs become a bottleneck and performance does not continue to increase.
The following command was used to run the benchmark, where the Threads variable is the number of threads used (1 to 512 incremented in powers of 2), and my_hosts.$Threads is the corresponding file that allocated each thread on a different node, using the round-robin method to spread them homogeneously across the 16 compute nodes. Like the IOR benchmark, the maximum number of threads was limited to 512 because there are not enough cores for more than 640 threads and context switching could affect the results, reporting a number lower than the real performance of the solution.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads –map-by node --mca btl_openib_allow_ib 1 --oversubscribe --prefix /usr/mpi/gcc/openmpi-4.1.2a1 /usr/local/bin/mdtest -v -d /mmfs1/perf/mdtest -P -i 1 -b $Directories -z 1 -L -I 1024 -u -t -F
Because performance results can be affected by the total number of IOPs, the number of files per directory and the number of threads, we decided to keep the total number of files fixed to 2 Mi files (2^21 = 2097152), the number of files per directory fixed at 1024, and the number of directories varied as the number of threads changed as shown in the following table:
Table 9. MDtest distribution of files on directories
Number of threads
Number of directories per thread
Total number of files
1
2048
2,097,152
2
1024
2,097,152
4
512
2,097,152
8
256
2,097,152
16
128
2,097,152
32
64
2,097,152
64
32
2,097,152
128
16
2,097,152
256
8
2,097,152
512
4
2,097,152
1024
2
2,097,152
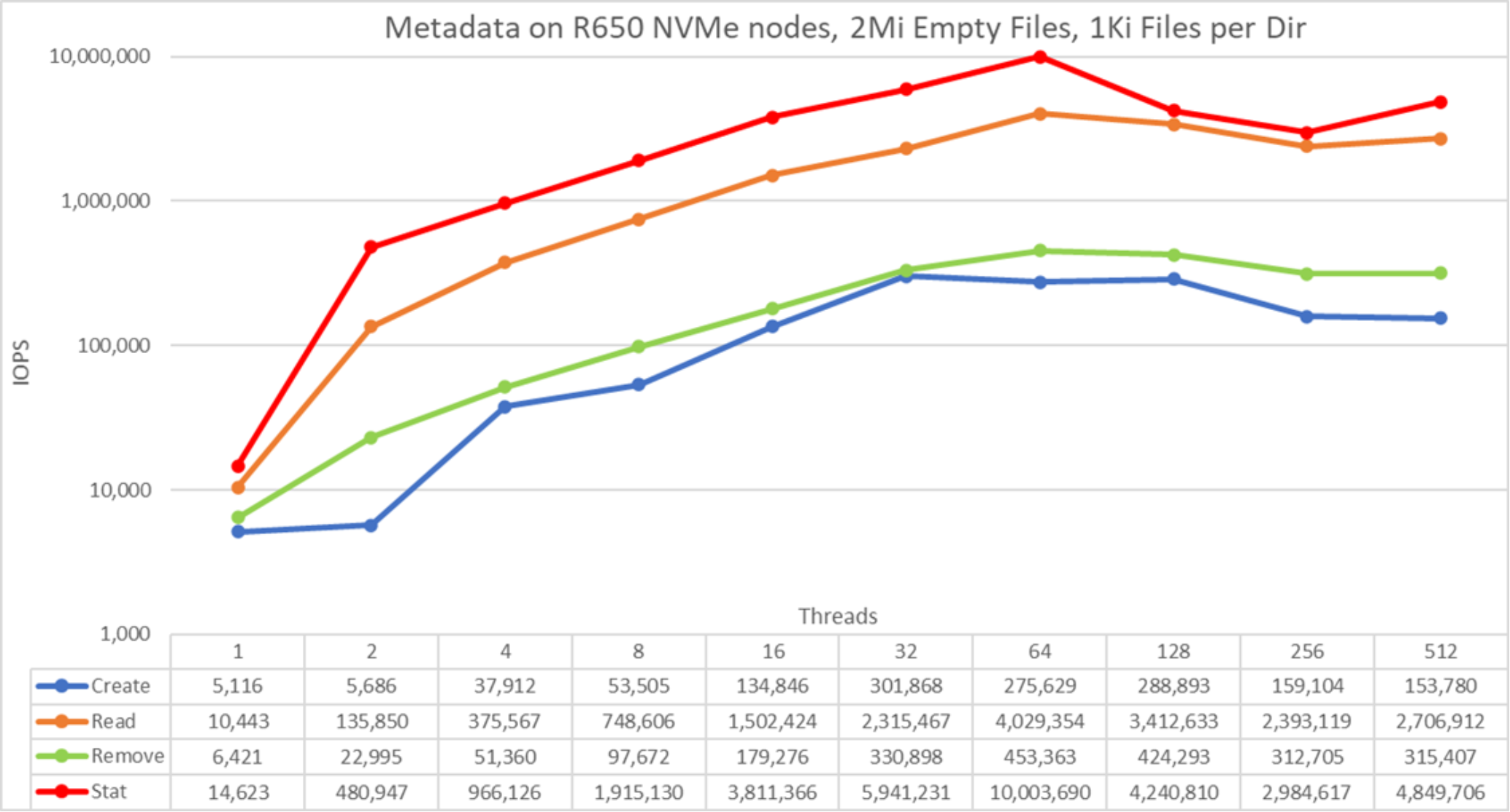
Figure 30. Metadata performance - empty files
Note that the scale chosen was logarithmic with base 10, to allow comparing operations that have differences several orders of magnitude; otherwise, some of the operations appear like a flat line close to 0 on a normal graph. A log graph with base 2 is more appropriate because the number of threads are increased by powers of 2. Such a graph looks similar, but people tend to perceive and remember numbers based on powers of 10 better.
The system provides good results for stat operations reaching their peak value at 64 threads with 10M op/s. Read operations reached a peak of 4M op/s at 64 threads (note that we are reading empty files). Remove operations attained the maximum of 453.4K Op/s and create operations achieved their peak with 301.8K op/s, both at 32 threads. Stat and read operations have more variability, but when they reach their peak value, performance does not drop below 4M op/s for stat operations and 3.2M op/s for read operations. Create and remove operations have less variability. Create operations keep increasing as the number of threads grows, and remove operations slowly decrease after reaching their peak value.
Because these numbers are for a metadata module with a single PowerEdge R650 NVMe metadata pair, performance increases for each additional PowerEdge R650 NVMe pair, however we cannot assume a linear increase for all operations. Unless the whole file fits inside the inode for such a file, data targets on other devices are used to store small files, limiting the performance to some degree.