
Infrastructure
Infrastructure
-
Here are some key design considerations on designing infrastructure for distributed DL:
- Build high network bandwidth between nodes: Distributed DL is a very compute-intensive task. To accelerate computation, training can be distributed across multiple machines connected by a network. During the training, constant synchronization between GPUs within and across the servers is required. Limited network bandwidth is one of the key bottlenecks towards the scalability of distributed DNN training. Most important metrics for the interconnection network are low latency and high bandwidth. It is recommended to use InfiniBand or 100Gbps Ethernet Network to maximum the network bandwidth between nodes. With enough network bandwidth, GPU utilization across nodes performs similar of single GPU configurations.
- Choose high throughput, scale-out centralized storage: With scalable distributed DL, the distribution of the training data (batches) to the worker nodes is crucial. It is inefficient and expansive to store training data in the local disks or Non-volatile random-access memory (NVRAM) on every worker node and copy terabytes of data across each worker node before the actual training can be started. Using a centralized storage for the training data, like a high throughput, scale-out storage offers a more convenient and effective solution for ADAS / AD DL training.
GPU servers can have 20-30k cores and each one request its own read thread. Most file systems max out at between 2,000 – 6,0000 open read threads, but PowerScale OneFS operating system doesn’t have performance limit on open threads. Meanwhile, DL workloads require high throughput random read during the training and data processing, and sequential write during data ingest. With distributed DL on multiple GPUs, to full utilize GPUs a steady flow of data from centralized storage into multiple GPUs jobs is critical for obtaining optimal and timely results. Data preprocessing (CPU) and model execution of a training step (GPU) run in parallel during the training require high throughput data read from storage.
An ADAS high performance DL system requires equally high-performance storage with scalability to multiple petabyte within a single file system. For a typical SAE level 3 project, this requirement ranges between 50 to 100 PB of data. The storage scalability is crucial for ADAS DL project with high performance to meet different business requirement.
Dell PowerScale all-flash storage platforms, powered by the PowerScale OneFS operating system, provide a powerful yet simple scale-out storage architecture up to 33 petabytes per cluster. It allows DL workload to access massive amounts of unstructured data with high performance, while dramatically reducing cost and complexity.
- Use Bright Cluster Manager (BCM) to provide cluster management and monitoring: Dell and Bright Computing have had a long track record of working together with both companies’ missions aligning to speed customer time-to-value, discovery, and generating data-based insights. BCM will enable the deployment of complete clusters over bare metal and manage them effectively. It will provide the management for the entire compute cluster, including the hardware, operating system, and users. It also has the capability to manage select applications within the HPC and AI environments such as Hadoop, Spark, and other big data software elements. BCM is making DL more accessible by providing software that makes it easy to deploy and manage the tools and supporting infrastructure required to get the job done. Bright for DL provides a complete platform to scale DL across an AD/ADAS environment with confidence. For more information, refer to Bright Computing DL website.
- Use Slurm Scheduler for DL training jobs across HPC nodes: To use resources on multiple nodes, the user can use Slurm job scheduler. The Slurm scheduler is used to manage the resource allocation and job submissions for all users in a cluster. To use Slurm, the user needs to submit a script on the cluster head node that specifies what resources are required and what job should be executed on those resources once allocated.
- Leverage NVIDIA Container Toolkits on NVIDIA GPUs: NVIDIA offers ready-to-run GPU- accelerated containers with the top DL frameworks. NVIDIA also offers a variety of pre-built containers which allow users to build and run GPU accelerated Docker containers quickly. To deploy DL applications at scale, it is very easy to leverage containers encapsulating an application’s dependencies to provide reliable execution of application and services even without the overhead of a full virtual machine. For more detail information, refer to the NVIDIA Container Toolkit page.
- Use Kubernetes to manage containers for distributed DL: Kubernetes is an increasingly popular option for training deep neural networks at scale, as it offers flexibility to use different ML frameworks via containers as well as the agility to scale on demand. It allows researchers to automate and accelerate DL training with their own Kubernetes GPU cluster. For more information, refer to article How to automate DL training with Kubernetes GPU-cluster.
- Use NVIDIA DL GPU Training System™ (DIGITS) for user interface: DIGITS is a wrapper for NVCaffe™ and TensorFlow™ which provides a graphical web interface to those frameworks in Figure 9 rather than dealing with them directly on the command-line. DIGITS simplify common DL tasks such as managing data, designing and training neural networks on multi-GPU systems, monitoring performance in real time with advanced visualizations, and selecting the best performing model from the results browser for deployment. DIGITS is completely interactive so that data scientists can focus on designing and training networks rather than programming and debugging.
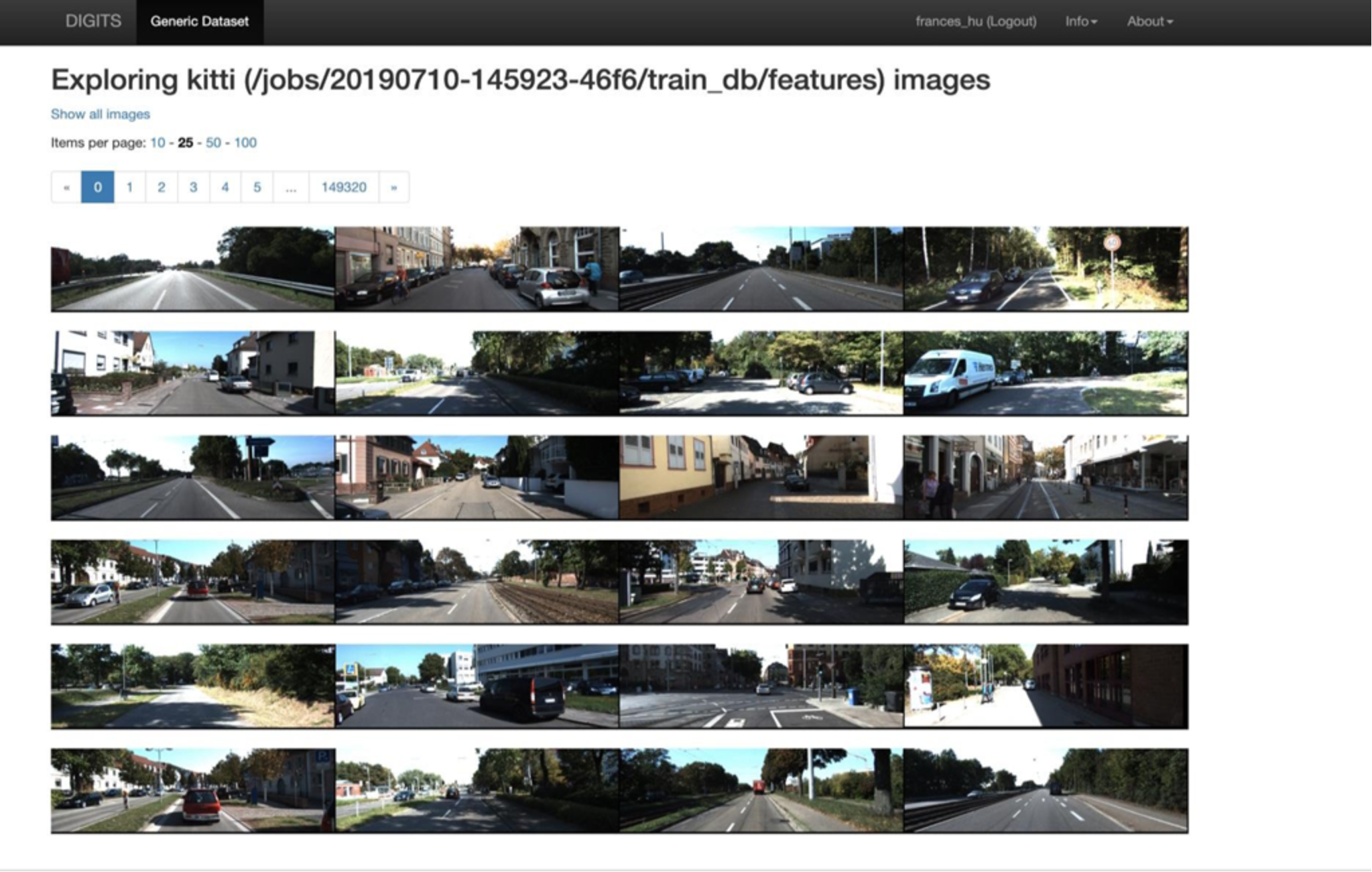
Figure 9. NVIDIA DIGITS for DL user interface platform