
Data Model Training
Data Model Training
-
The ability to train neural network data models with many hidden layers, as well as the ability to train them with large datasets in a short amount of time at scale is critical to ADAS/AD development. To assure safety and reliability, the neural networks designed for driving operations will utilize many permutations of parameters which will generate more compute-intensive requirements for the underlying systems and hardware architecture. In distributed DL platforms, the model needs to be synchronized across all nodes. It also requires the careful management and distributed coordination of computation and communication across all nodes.
Here are some key considerations for designing scalable neural networks:
- Data parallelism vs model parallelism: Data parallelism, as shown below, is generally easier to implement. Each device works with a different part of the overall dataset and the devices collectively update a shared model. These devices can be located on a single machine or across multiple machines.
Data Parallelism:
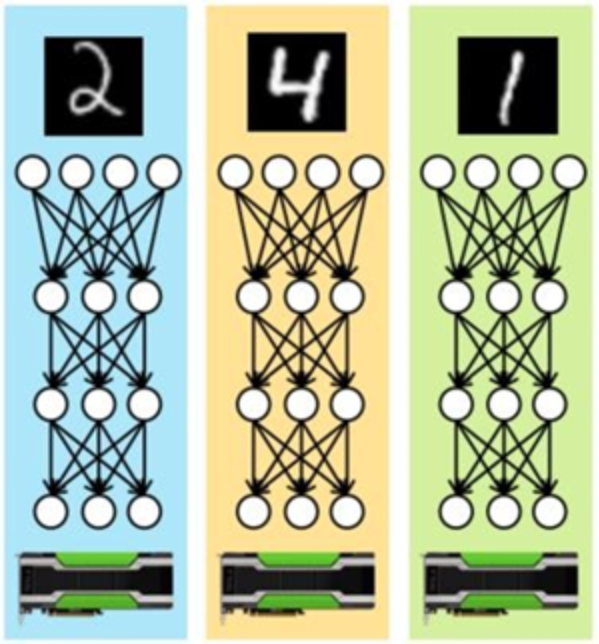
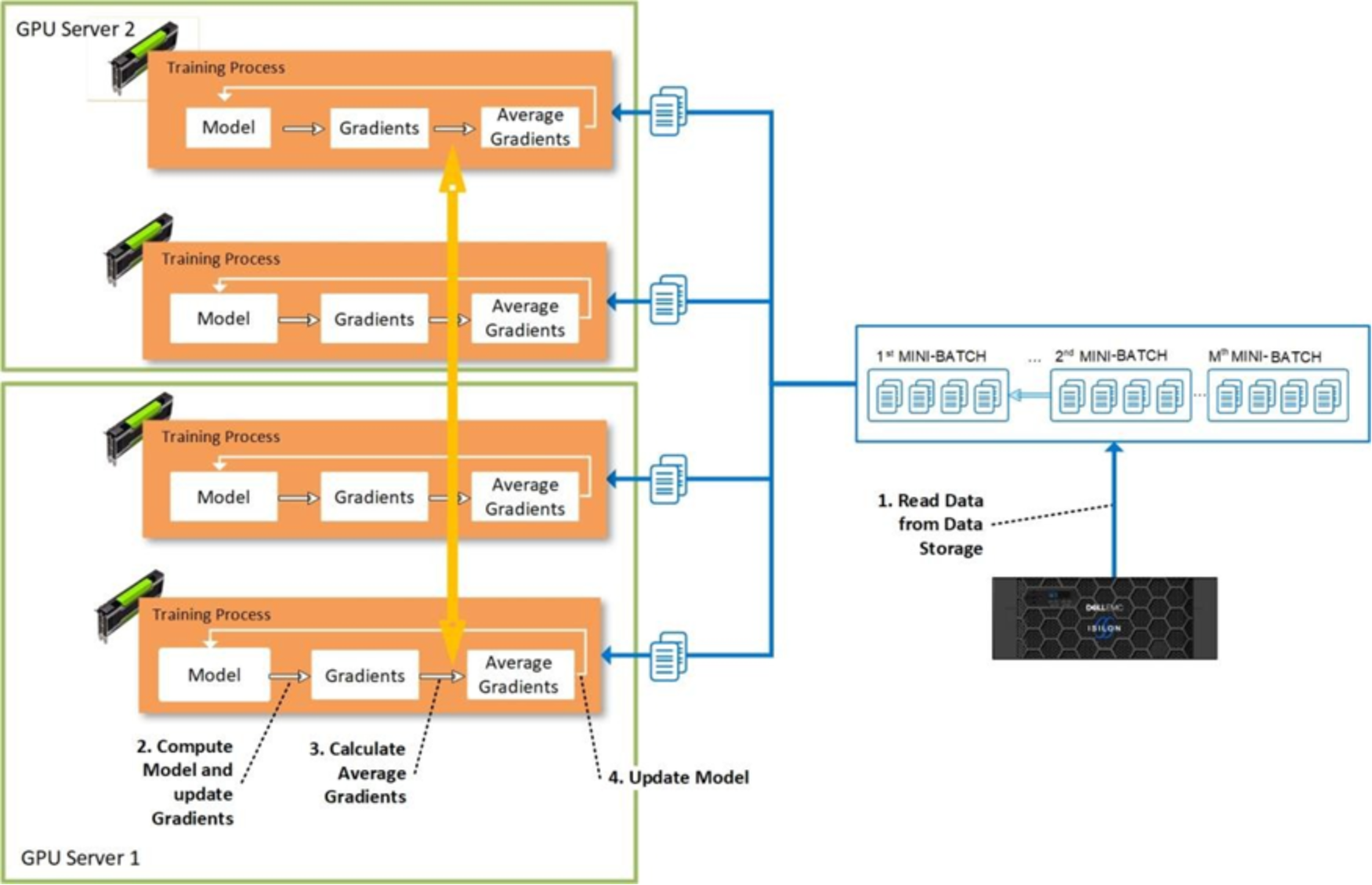
Most DL frameworks use data parallelism to partition the workload over multiple devices. Following picture shows the detail process of data parallelism approach to distribute training processes across the multiple GPU servers and devices. Data parallelism also requires less communication between nodes as it benefit from high amount of computations per weight. Assume for example, there are n devices, where each device receives a copy of the complete model and train it with 1/nth of the data. The results such as gradients and the updated model itself are communicated across these devices.
To ensure the efficient training, the network bandwidth across the nodes cannot become a bottleneck. Also note, it is inefficient – and bad practice - to store training data on the local disks of every worker node – this forces the copying of terabytes of data to each worker node before the actual training can be started.
parallelism approach to distribute training processes:
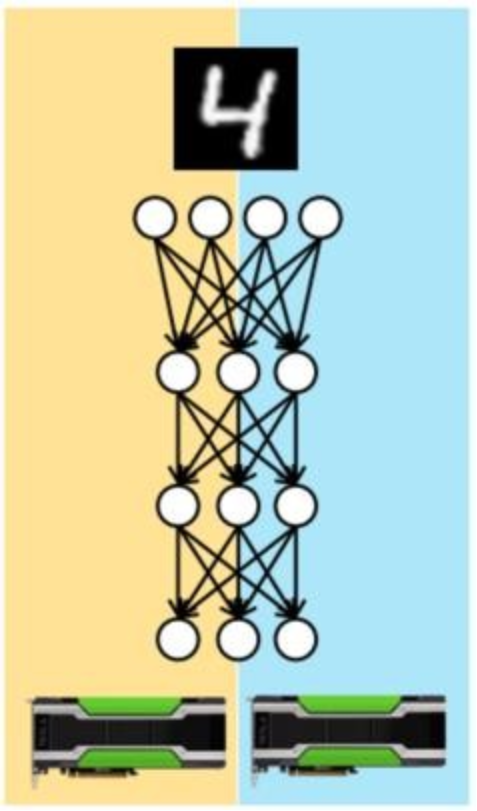
When models are so large that they don’t fit into device memory, then an alternative, called model parallelism shown as below. Different devices are assigned the task of learning different parts of the model. Model parallelism requires more careful consideration of dependences between the model parameters. Model parallelism may work well for GPUs in a single server that share a high-speed bus. It can be used with larger models as hardware constraints per node are no more a limitation.
Model Parallelism:
- Leverage open source DL toolkit like Horovod: Horovod is a distributed training framework for TensorFlow, Keras, PyTorch, and MXNet. The goal of Horovod is to make distributed DL fast and easy to use. Horovod use Message Passing Interface (MPI) model to be much more straightforward and require far less code changes than the Distributed TensorFlow with parameter servers. Horovod currently supports models that fit into one server but may span multiple GPUs.
- Use the latest DL framework: Leverage the latest DL framework and toolkit to avoid potential performance issue or bugs, and compatible cuDNN and NVIDIA Collective Communications Library (NCCL). The newer version always delivers great performance improvements and bug fixes.