
Pravega
Pravega
-
Pravega is deployed as a distributed system, it forms the Pravega cluster inside Kubernetes.
The Pravega architecture presents a software-defined storage (SDS) architecture that is formed by Controller instances (control plane) and Pravega Servers (data plane) also known as Pravega Segment Store. The following figure illustrates an overview of the default architecture. Most of the components—such as the volume size or number of replicas per stateful set or replica set—can be customized.
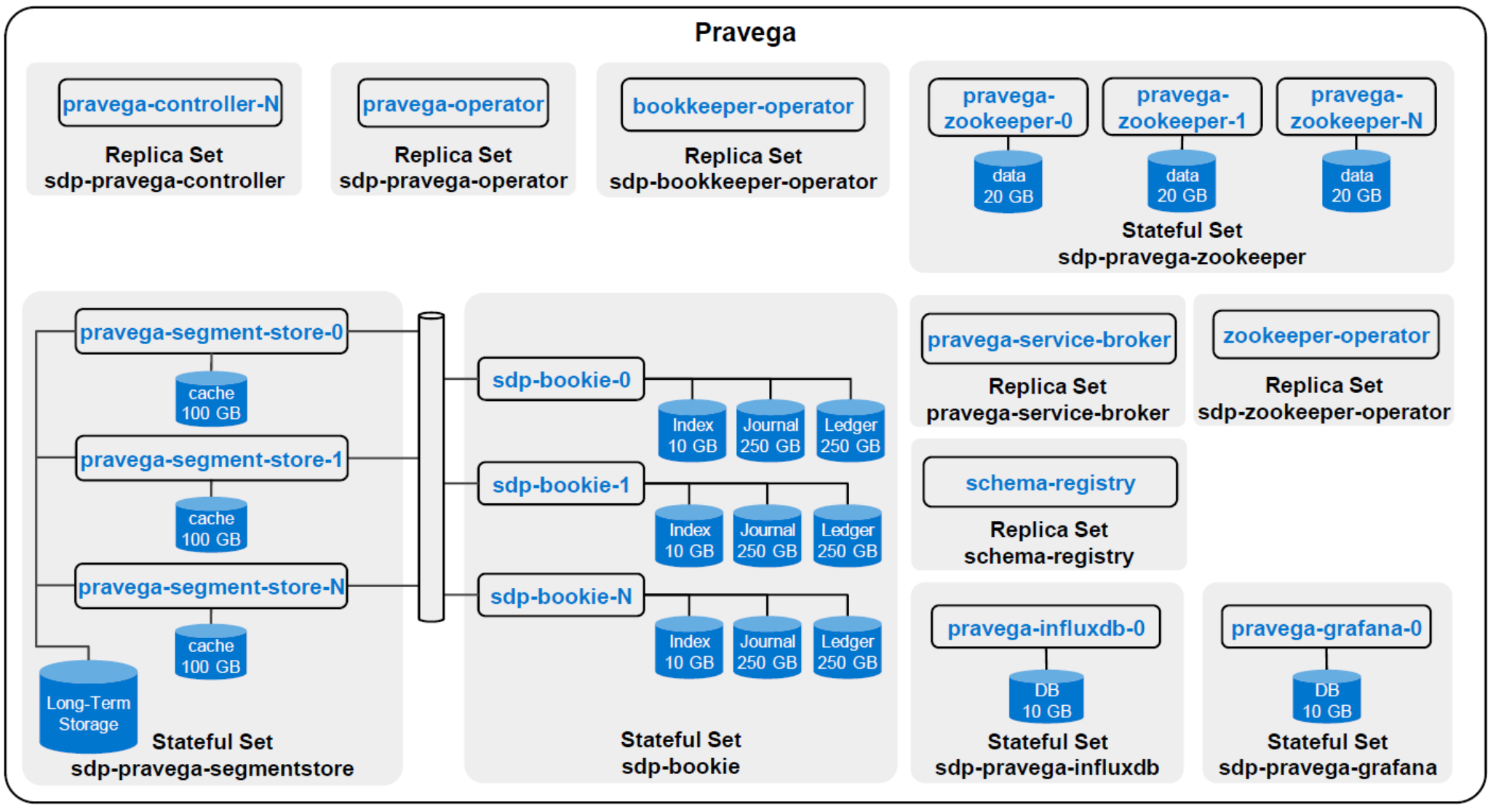
Figure 5. Pravega architecture diagram
Pravega Operator
The Pravega Operator is a software extension to Kubernetes. It manages Pravega clusters and automates tasks such as creation, deletion, or resizing of a Pravega cluster. Only one Pravega operator is required per instance of the Streaming Data Platforms. For more details about Kubernetes operators, see the Kubernetes page Operator pattern.
Bookkeeper Operator
The Bookkeeper Operator manages Bookkeeper clusters deployed to Kubernetes. It automates tasks related to operating a Bookkeeper cluster, such as create and destroy a Bookkeeper cluster, resize cluster, and rolling upgrades.
Zookeeper Operator
The Zookeeper Operator manages the deployment of Zookeeper clusters in Kubernetes.
Pravega service broker
The Pravega service broker creates and deletes Pravega Scopes. It also registers them as protected resources in Keycloak along with related authorization policies.
Pravega Controller
The Pravega Controller is a core component in Pravega that implements the Pravega control plane. It acts as central coordinator and manager for various operations that are performed in the Pravega cluster such as actions to create, update, seal, scale, and delete streams. It is also responsible for distributing the load across the different Segment Store instances. The set of Controller instances form the control plane of Pravega. They extend the functionality to retrieve information about the Streams, monitor the health of the Pravega cluster, gather metrics, and perform other tasks. Typically, there are multiple Controller instances (at least three instances are recommended) running in a cluster for high availability.
Pravega Segment Store
The Segment Store implements the Pravega data plane. It is the main access point for managing Stream Segments, which enables creating and deleting content. The Pravega client communicates with the Pravega Stream Controller to identify which Segment Store must be used. Pravega Servers provide the API to read and write data in Streams. Data storage includes two tiers:
- Tier 1: This tier provides short-term, low-latency data storage, guaranteeing the durability of data written to Streams. Pravega uses Apache Bookkeeper to implement tier 1 storage. Tier 1 storage typically runs within the Pravega cluster.
- Long-Term Storage (LTS): This tier provides long-term storage for Stream data. The Streaming Data Platform supports Dell Isilon and Dell ECS to implement Long-Term Storage. LTS is commonly deployed outside the Pravega cluster.
The number of Segment Stores is customizable and can be scaled depending on the workload.
Pravega Zookeeper
Pravega uses Apache Zookeeper to coordinate with the components in the Pravega cluster. By default, three Zookeeper servers are installed.
Pravega InfluxDB
The Pravega InfluxDB is used to store Pravega metrics.
Pravega Grafana
Pravega Grafana dashboards show metrics about the operation and efficiency of Pravega.
Pravega Schema Registry
Pravega Schema Registry is the latest service offering from Pravega family. The registry service is designed to store and manage schemas for the unstructured data stored in Pravega streams. The service is designed to not be limited to the data stored in Pravega and can serve as a general-purpose management solution for storing and evolving schemas in wide variety of streaming and nonstreaming use cases. Schema Registry provides RESTful interface to store and manage schemas under schema groups. Users can safely evolve their schemas within the context of the schema group based on desired schema compatibility policy configured at a group level. For more details about Schema Registry, see Pravega Schema Registry Repository on GitHub.
Pravega Bookkeeper
Pravega uses Apache Bookkeeper. It provides short-term, low-latency data storage, guaranteeing the durability of data written to Streams. In deployment, use at least five bookkeepers (bookies): three bookies for a quorum plus two bookies for fault-tolerance. By default, three replicas of the data must be kept in Bookkeeper to ensure durability.
Table 1 describes the four parameters in Bookkeeper that are configured during the Streaming Data Platform installation. For more details, see the Streaming Data Platform Installation and Administration Guide.
Table 1. Bookkeeper parameters
Parameter name
Description
bookkeeper replicas
The number of bookies needed in the cluster
bkEnsembleSize
The number of nodes the ledger is stored on.
bkEnsembleSize = bookkeeper replicas - F
F represents the number of bookie failures tolerated. For instance, wanting to tolerate two failures, at least three copies of the data are needed (bkEnsembleSize = 3). To enable two faulty bookies to be replaced, instantiate two additional bookies, with a total of five bookkeeper replicas.
bkWriteQuorumSize
This parameter corresponds to the number of replicas of the data to ensure durability.
bkAckQuorumSize
By default, the following is true:
bkWriteQuorumSize == bkAckQuorumSize
The platform waits for the acknowledgment of all bookies on a write to go to the next write.
Pravega data flow
The following steps and diagrams outline the processes for write and read data flows.
Write data flow (Figure 6):
- The Client contacts the Controller to identify where to perform the write.
- The Controller returns the segment and the Segment Store URL where to write the data.
- The Client writes to the Segment Store.
- The data is written to Tier-1 in Apache Bookkeeper.
- The Client receives an acknowledgment from Pravega confirming that the data has been written. In parallel, the data is stored in the Segment Store cache volume.
- Asynchronously, the data is copied to long-term storage.
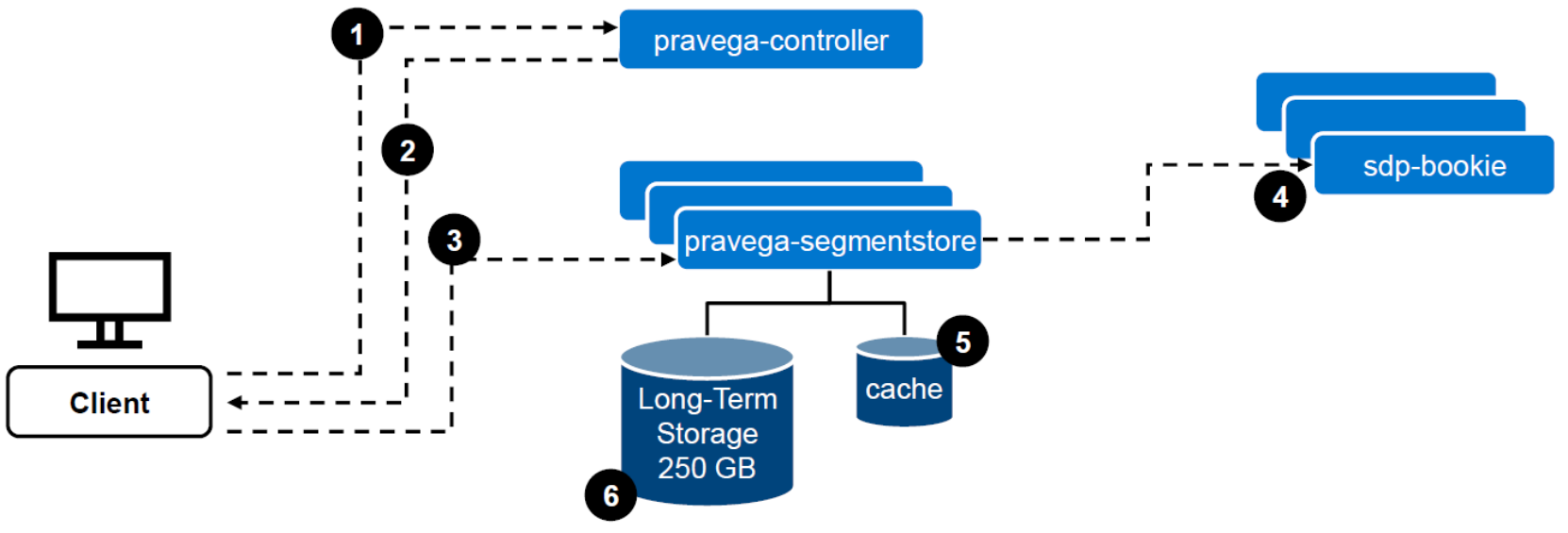
Figure 6. Write data flow
Read data flow (Figure 7):
- The client contacts the Controller to identify where to perform the read.
- The Controller returns the segment and the Segment Store URL where to read the data.
- Data is requested to the Segment Store.
- The Segment Store reads from cache or Long-Term Storage, depending on where the data is stored. This information is hidden from the client point of view.
- The data is returned to the client.
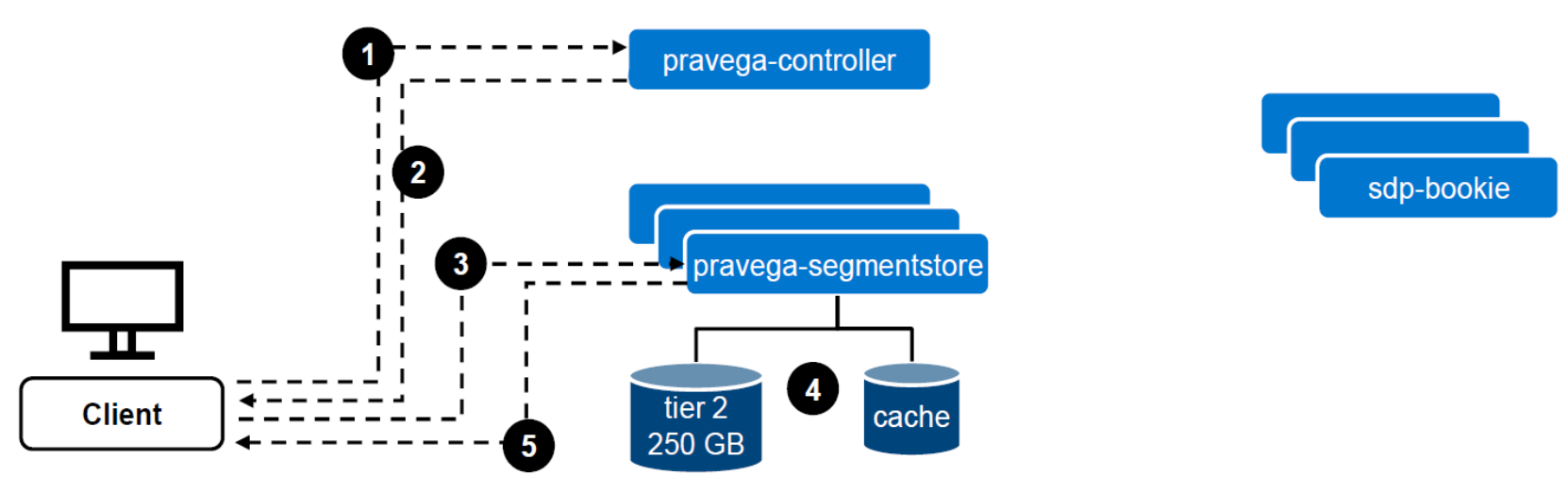
Figure 7. Read data flow
Note: Apache Bookkeeper is not used in a “read data flow” scenario. The data that is stored in Apache Bookkeeper is used only for recovery purposes.