
Architecture
Architecture
-
The Streaming Data Platform architecture contains the following key components:
- Pravega: Pravega is an open-source streaming storage system that implements streams and acts as first-class primitive for storing or serving continuous and unbounded data. This open-source project is driven and designed by Dell Technologies. For more information, see the Pravega website.
- Unified Analytics: SDP includes the following embedded analytic engines for processing data stream.
- Apache Flink: Flink is a distributed computing engine to process large-scale unbounded and bounded data in real time. Flink is the main component to perform streaming analytics in the Streaming Data Platform. Flink is an open-source project from the Apache Software Foundation.
- Apache Spark is a unified analytics engine for large-scale data processing. SDP ships with images for Apache Spark.
- Pravega Search (PSearch) provides search functionality against Pravega streams.
- GStreamer is a pipeline-based multimedia framework that links together a wide variety of media processing systems to complete complex workflows. GStreamer supports a wide variety of media-handling components, including simple video playback, recording, streaming, and editing. Integrated with SDP, GStreamer can record video from supported network-connected cameras to Pravega and perform real-time GPU-accelerated object detection inference on the recorded video.
- Kubernetes: Kubernetes (K8s) is an open-source platform for container orchestration. K8s is distributed through Kubespray for Edge deployment and OpenShift by RedHat for Core deployment.
- Management platform: The management platform is proprietary software from Dell Technologies. It integrates the other components and adds security, performance, configuration, and monitoring features. It includes a web-based user interface for administrators, application developers, and end users.
The Streaming Data Platform supports the following deployment options, which allow customers to stream data from the edge to the core:
- SDP Edge is a small footprint deployment. Deploying SDP at the edge, where the data is generated, has the advantage of local ingestion. In addition, SDP Edge can process, filter, or enrich the collected data at the edge, as opposed to sending all data upstream to the core. SDP Edge can be deployed on a single physical node for edge sites that do not require high availability (HA) or on three physical nodes for edge sites that require HA.
- SDP Micro is a lightweight version of SDP Edge that can ingest low-volume data from sensors without gateways. SDP Micro comes with limited analytics capabilities and can only be installed on a single virtual or physical node.
- SDP Core provides all the advantages of on-premises data collection, processing, and storage. It provides real-time data ingestion and also accepts data collected by SDP Edge and streamed up to the core. Deployments can start with a minimum of 3 nodes and expand out up to 12 nodes, with integrated scaling of added resources.
The following figure shows a high-level overview of the Streaming Data Platform architecture streaming data from the edge to the core.
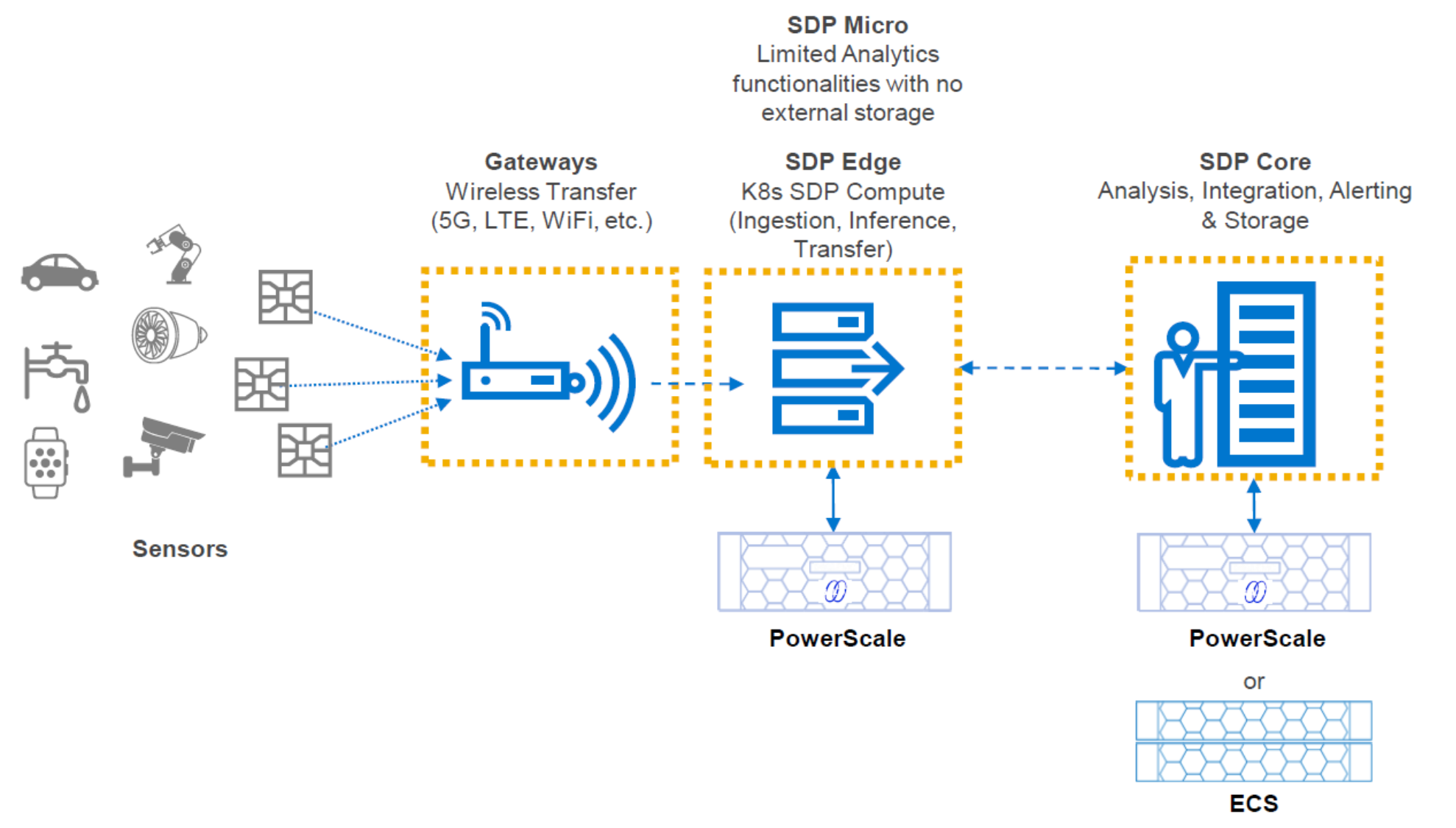
Figure 1. High-level architecture overview
SDP Edge architecture overview
The following figure shows a high-level depiction of the Streaming Data Platform architecture at the edge.
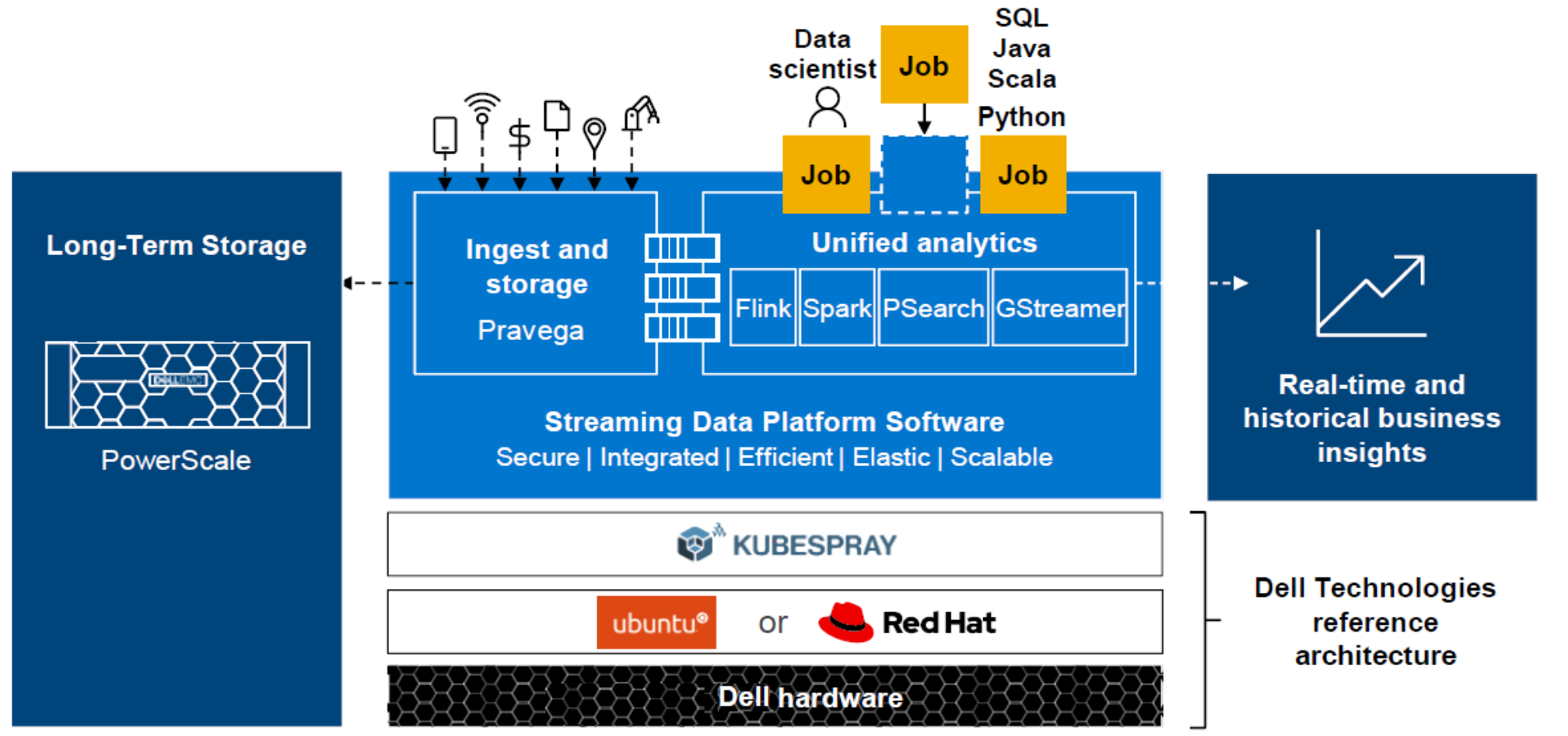
Figure 2. Streaming Data Platform architecture overview at the edge
Note: SDP Edge only supports Dell PowerScale systems for Long-Term Storage (LTS).
SDP Micro architecture overview
The following figure shows a high-level depiction of the Streaming Data Platform Micro architecture.
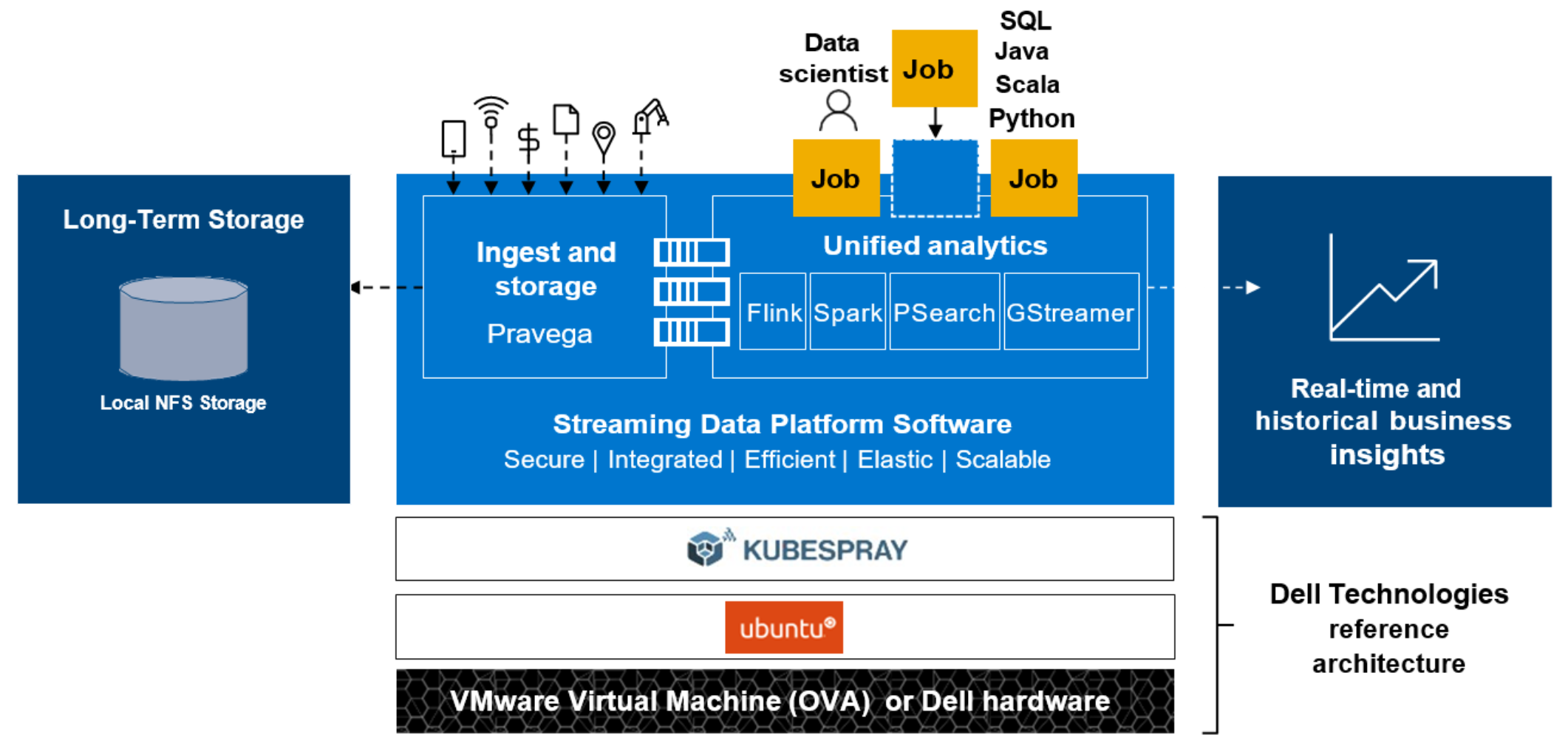
Figure 3. SDP Micro architecture overview
SDP Core architecture overview
The following figure shows a high-level depiction of the Streaming Data Platform architecture at the core. SDP Core architecture is based on Dell Ready Stack for Red Hat OpenShift Container Platform 4.6.
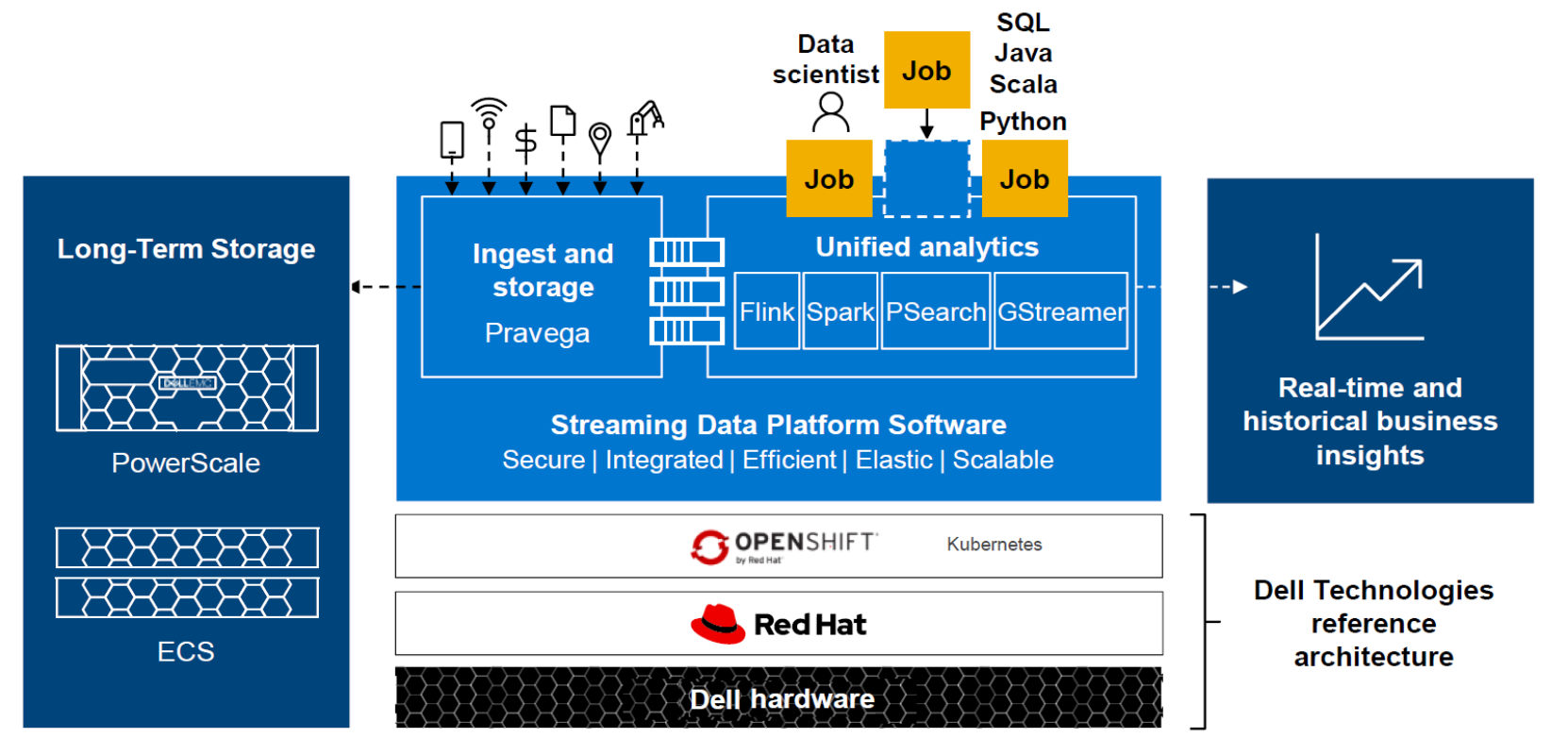
Figure 4. Streaming Data Platform architecture overview at the core