
Analytics project
Analytics project
-
The Streaming Data Platform provides analytic compute capabilities in the form of a managed Apache Flink or Apache Spark environments. In SDP, each Flink or Spark environments are tied to an analytics project. An analytics project is an isolated environment for streaming or analytic processing. The provisioning process of an analytic project creates the following components:
- Security credentials for the project
- A Pravega Scope (with the same name as the project) secured by the project credentials
- Storage for project analytic components (backed by NFS or ECS S3)
- Integrated metrics for monitoring
- A Kubernetes namespace (with the same name as the project) containing common infrastructure components:
- A Zookeeper cluster (three nodes by default).
- A secure Project artifact repository (accessible from outside the cluster with a dedicated DNS name). SDP supports Maven coordinates for or file path.
- Kubernetes secrets containing the project credentials.
SDP (1.3 and later versions) takes advantage of graphics processing units (GPUs) for image and video processing, stream processing, and machine learning. The GPU-accelerated workload adds support for both Apache Flink and Apache Spark applications, which enables data scientists to use machine learning on analytic workloads. For the moment, only NVIDIA’s GPUs are supported.
Note: Beginning with SDP 1.3, SDP supports MQTT and REST-based ingest gateway. Any application that can use these protocols can directly ingest the data into SDP without integrating with the Pravega client.
Apache Fink
Flink clusters can be easily deployed into analytics projects, with SDP automatically configuring Flink clusters with Pravega access credentials, storage, and HA configuration. The Flink application life cycle is also managed by SDP, providing an easy way to deploy, stop, start, and migrate Flink applications onto Flink clusters.
SDP 1.3 ships with images for Flink 1.10.x, 1.11.x, and 2.12.
Once the analytics project has been created, the user can create one or more Flink clusters depending on their needs. By default, a Flink cluster is composed of one job manager and n task managers. The number of task managers within the cluster can be scaled at any time. SDP automatically configures Flink clusters with the correct Pravega credentials, storage and high availability configuration reducing the burden on administrators. The following figure shows a Flink cluster within an analytics project.
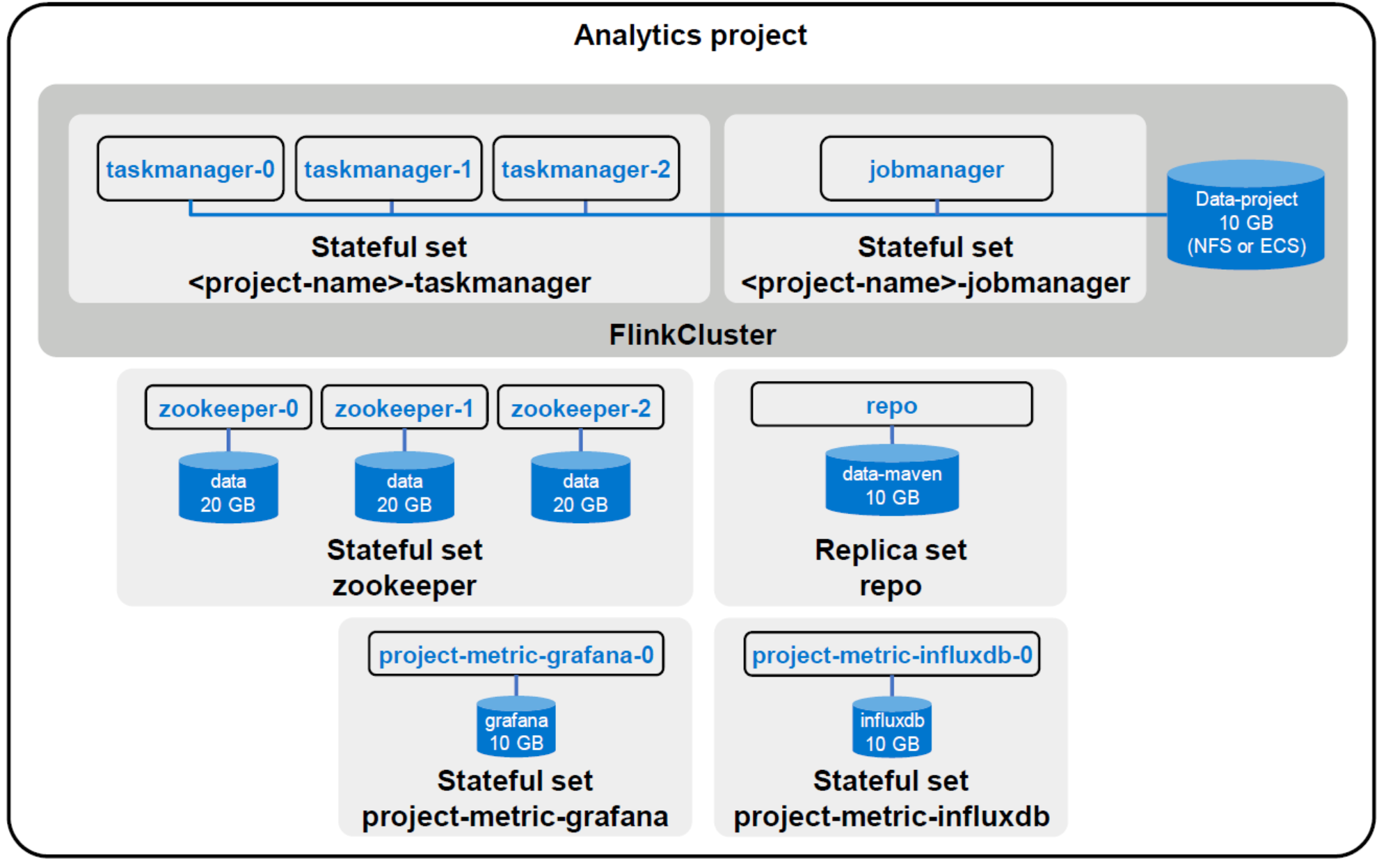
Figure 8. Flink analytics project diagram
Apache Spark
Spark applications can be easily deployed into analytics projects with SDP automatically configuring Spark stacks with Pravega access credentials, storage, and HA configuration. The Spark application life cycle is also managed by SDP providing an easy way to deploy, stop, start, and migrate Spark applications.
SDP 1.3 ships with images for Spark 2.4.7 and 3.0.1. Java, Scala, and Python are the supported programming languages.
The main difference is that the Spark cluster is the application. With Spark, there is no concept of a session cluster as there is with Flink. The Spark cluster is split into the driver and the executors. The driver runs the main application and manages the scheduling of tasks. The executors are workers that perform tasks.
When you deploy a Spark application within SDP, SDP will automatically create the Driver pod, which contains the SparkContext, also known as the cluster manager. The SparkContext is responsible for communicating with Kubernetes to create executor pods. Application actions are split into tasks and scheduled on executors. The following figure shows a Spark application within an analytics project.
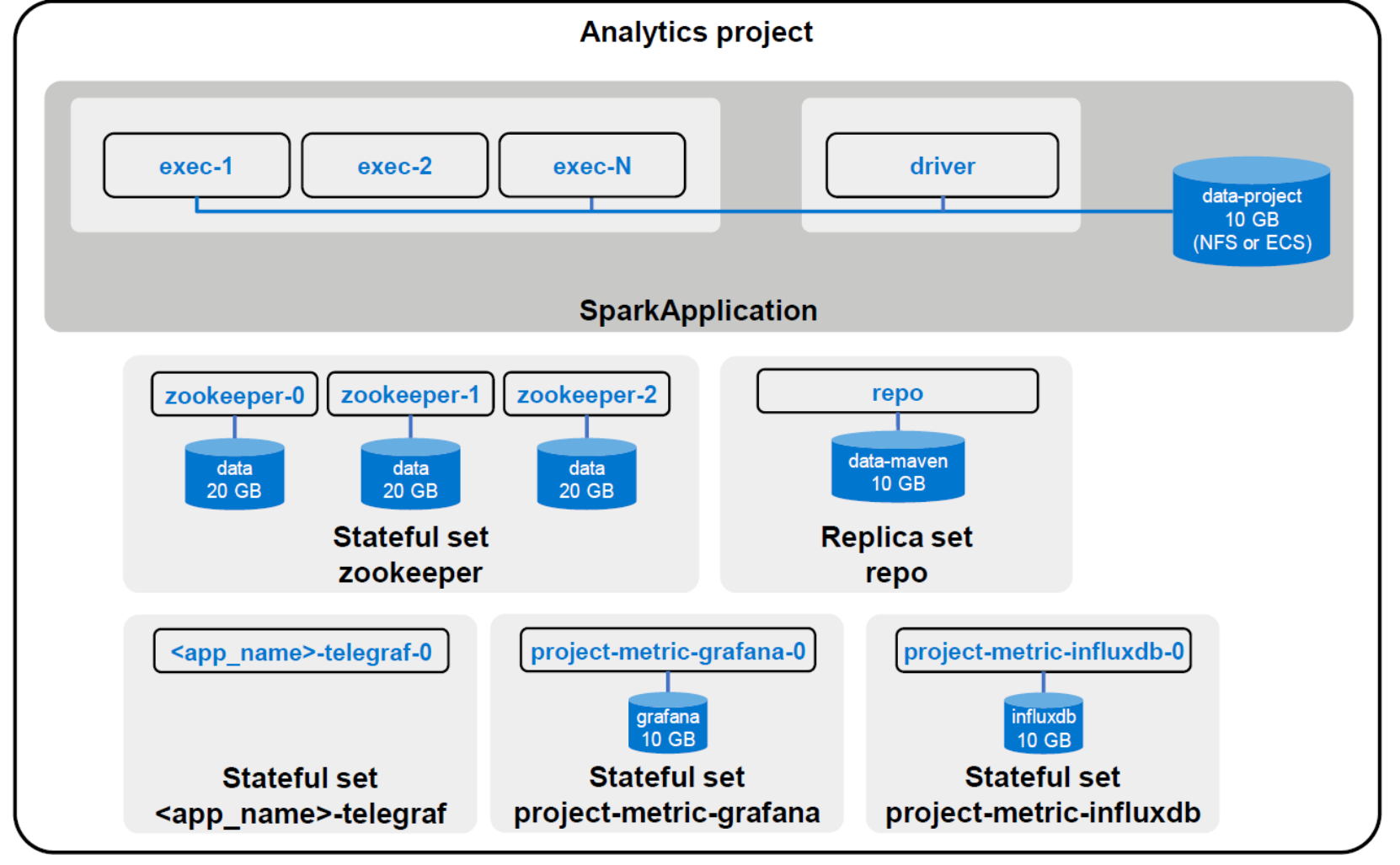
Figure 9. Spark analytics project diagram
Pravega Search (PSearch)
Pravega Search (PSearch) provides search functionality against Pravega streams. Pravega Search is available only as part of SDP. It is not available with Open Source Pravega. SDP provides all Pravega Search functionality in addition to comprehensive deployment, management, security, and access to the PSearch REST API. Pravega Search is implemented in the context of an SDP project. It runs in its own cluster associated with a project. A project has only one PSearch cluster. Search can be enabled or disabled at any time in the stream life cycle.
Access to a PSearch cluster is based on project membership. Only project members and SDP Administrators can make streams searchable, submit queries, and view query results. Applications using the Pravega Search REST API must obtain project credentials.
With Pravega Search deployed in its own separated clusters, the stream indexing and query processing do not affect the efficiency of other stream processing functions. Each PSearch cluster has its own CPU and memory resources. The resources used for stream ingestion, stream storage, and analytic operations are not affected by the volume or timing of indexing and querying.
Pravega Search maintains index metadata in an infinitely expanding series of index documents, stored in system-level Pravega streams. SDP manages the index documents and all the indexing worker threads that perform the indexing and query processing. Autoscaling for Pravega Search resources is built into SDP.
For more details about PSearch, see the Streaming Data Platform Developer's Guide.
Video analytics with GStreamer
The Streaming Data Platform can record video from supported network-connected cameras to Pravega and perform real-time GPU-accelerated object detection inference on the recorded video. Object detection is a type of deep learning inference that can identify the coordinates (left, top, width, height) and class objects (for example, car, bike, person) in an image. Object detection is a core requirement for many advanced video intelligence tasks, such as counting the number of people, measuring automobile traffic flow rates, and reading street signs.
SDP (1.3 and later) provides a web UI, which allows users to specify the connectivity parameters for network-connected cameras, such as IP addresses and login credentials, using Real-Time Streaming Protocol (RTSP). RTSP cameras often support both TCP and UDP transport modes of Real-Time Protocol (RTP). SDP only supports the TCP transport mode because it is more reliable and can easily travel through firewalls.
Retention policies can be applied to video streams, enabling automatic deletion of older videos based on bytes used or age.
Both camera recording and object detection processes use the GStreamer multimedia framework, which allows developers to build flexible and high-performance video processing pipelines.
To provide object detection, SDP developers can use the NVIDIA DeepStream SDK. The SDK provides GPU-acceleration of common video processing tasks, such as video decoding and object detection. NVIDIA DeepStream SDK delivers a complete streaming analytics toolkit for AI-based multi-sensor processing, video, and image understanding. It is built around the open-source GStreamer framework and provides GStreamer plug-ins, such as GPU accelerated H.264 video encoding and decoding, and deep learning inference. NVIDIA DeepStream requires a NVIDIA GPU.