
vSphere DRS, HA, and Metro Volume
vSphere DRS, HA, and Metro Volume
-
VMware Distributed Resource Scheduler (DRS) is a cluster-centric configuration that uses VMware vSphere vMotion to automatically move virtual-machine compute resources to other hosts in a vSphere cluster. This action is performed without local, metro, or stretched-site awareness. Also, vSphere is unaware of storage virtualization that occurs in Metro Volume. When Metro Volume is configured with vSphere, consider placing tier 1 or business-critical virtual machines on the preferred Metro Volume if there could be an unplanned synchronous replication link outage.
If DRS is enabled on a vSphere cluster, DRS could automatically move virtual machines around. This situation could be a problem in a non-uniform storage presentation design. DRS host groups and VM groups can be used to apply rules resulting in boundaries for virtual machine mobility.
- VM groups: Virtual machines can be placed into VM groups. VM groups can be pinned to hosts in a Host group where the VMs should run.
Host groups: Hosts that share a common preferred or non-preferred Metro Volume can be placed into Host groups. Once the host groups are configured, they can represent locality for the preferred or non-preferred Metro Volume.
You can assign VM groups to host groups using the vSphere Client. This practice ensures virtual machines follow predictable placement rules on vSphere hosts backed by Metro Volumes. You can also design the infrastructure with separate DRS-enabled clusters existing at both sites, keeping automatic migration of virtual machines within the respective site where the preferred or non-preferred Metro Volume resides.
vSphere Availability (HA) is also a cluster-centric configuration. If there is a host or storage failure, HA attempts to restart virtual machines on a host candidate within the same cluster that still has access to the Metro Volume. In a non-uniform storage presentation, if an outage impacts non-preferred Metro Volume availability, you can configure vSphere HA to restart impacted virtual machines on the preferred Metro Volume.
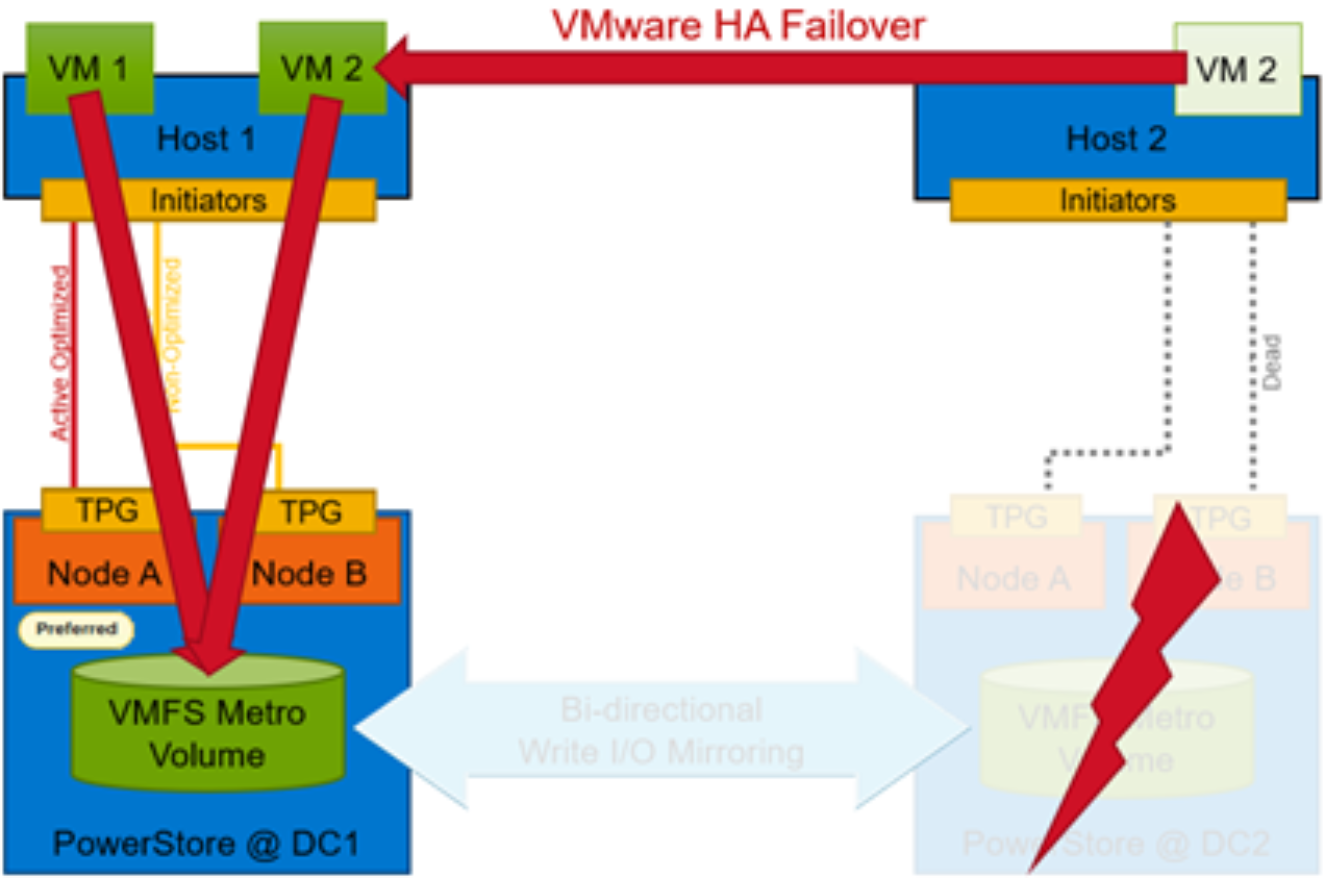
Figure 38. Failure of non-preferred role in non-uniform storage presentation
The following vSphere advanced tuning should be configured for non-uniform stretched cluster configurations. This tuning allows HA to power off and migrate virtual machines to the preferred Metro Volume if the non-preferred Metro Volume becomes unavailable.
Configure the following:
- vSphere 6.0+: Disk.AutoremoveOnPDL = 1 (VMware recommended default advanced setting on each host)
- Besides supporting HA restart for Permanent Device Loss (PDL) events, HA restart can also react to All-Paths-Down (APD) events. We recommend configuring VM Component Protection for PDL and APD events. For PDL events, select Power off and restart VMs. For APD events, VMware recommends selecting Power off and restart VMs (conservative). For the advanced APD settings, see the document VMware vSphere Metro Storage Cluster Recommended Practices.
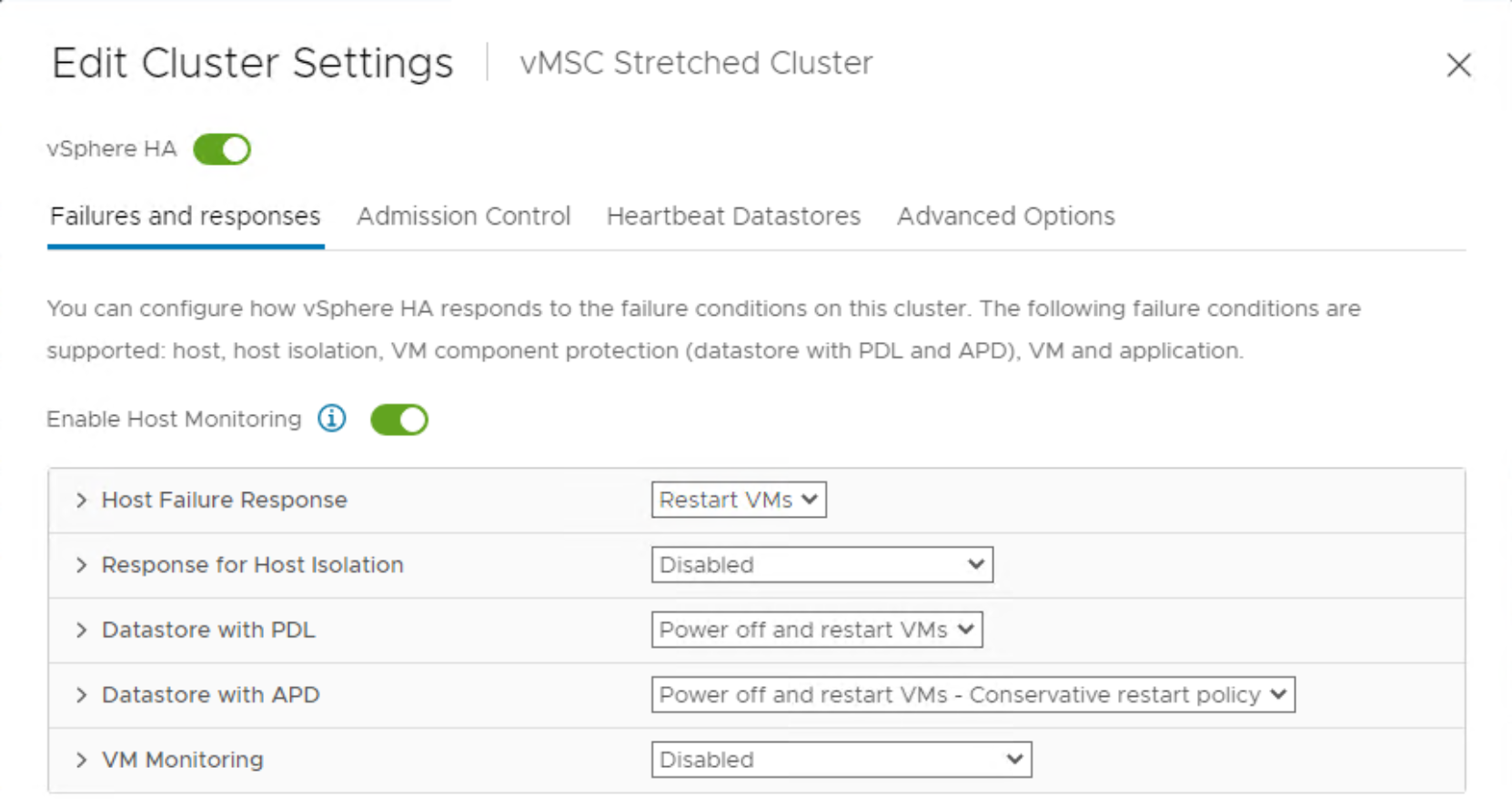
Figure 39. Configuring vSphere HA for PDL and APD conditions
The Disk.AutoremoveOnPDL advanced setting is not configurable in VMCP and should remain at its default value of 1 for each vSphere 6 host in the cluster. For more information about the Disk.AutoremoveOnPDL feature, see the VMware KB article 2059622, PDL AutoRemove feature vSphere 6.x/7.x.
If an unplanned outage impacts the preferred Metro Volume availability, the Metro Volume becomes unavailable. Virtual machines running on this Metro Volume will lose access to storage.
VMware vSphere monitors SCSI sense codes sent by an array to determine if a device is in a PDL state. These SCSI sense codes are outlined in VMware KB article 2004684, Permanent Device Loss (PDL) and All-Paths-Down (APD) in vSphere 6.x and 7.x. PowerStore supports the following SCSI sense codes (see table below) which will be sent to vSphere hosts when a PDL condition is met.
Table 8. SCSI sense codes
SCSI sense code
Description
0x02/0x04/0x0c
ALUA UNAVAILABLE