
ESXi path selection policies (PSP)
ESXi path selection policies (PSP)
-
vSphere ships with three MPIO path selection policies (PSP): Most Recently Used (MRU), Round Robin (RR), and Fixed. MRU is the default policy for most active-passive storage devices and is not used with PowerStore.
When the host connectivity feature is configured correctly, the best path selection policy to choose with Metro Volume is Round Robin. Round Robin is the easiest PSP to configure and provides both optimal I/O performance and a balance of the storage fabric in uniform or non-uniform storage presentation. Also, it provides an automatic failover capability to non-optimal paths and an automatic failback capability to recovered optimal paths.
For the ESXi host, the working path state is available in Configure > Storage Device.
The following figure shows how vCenter displays the paths for a uniform host configuration with the settings of Co-Located with Local (target ending with …fnm102135) and Co-Located with Remote (target ending with …fnm102139). The number of total paths shown in the vSphere UI is determined by multiplying the number of host initiators by the number of target port groups on PowerStore.
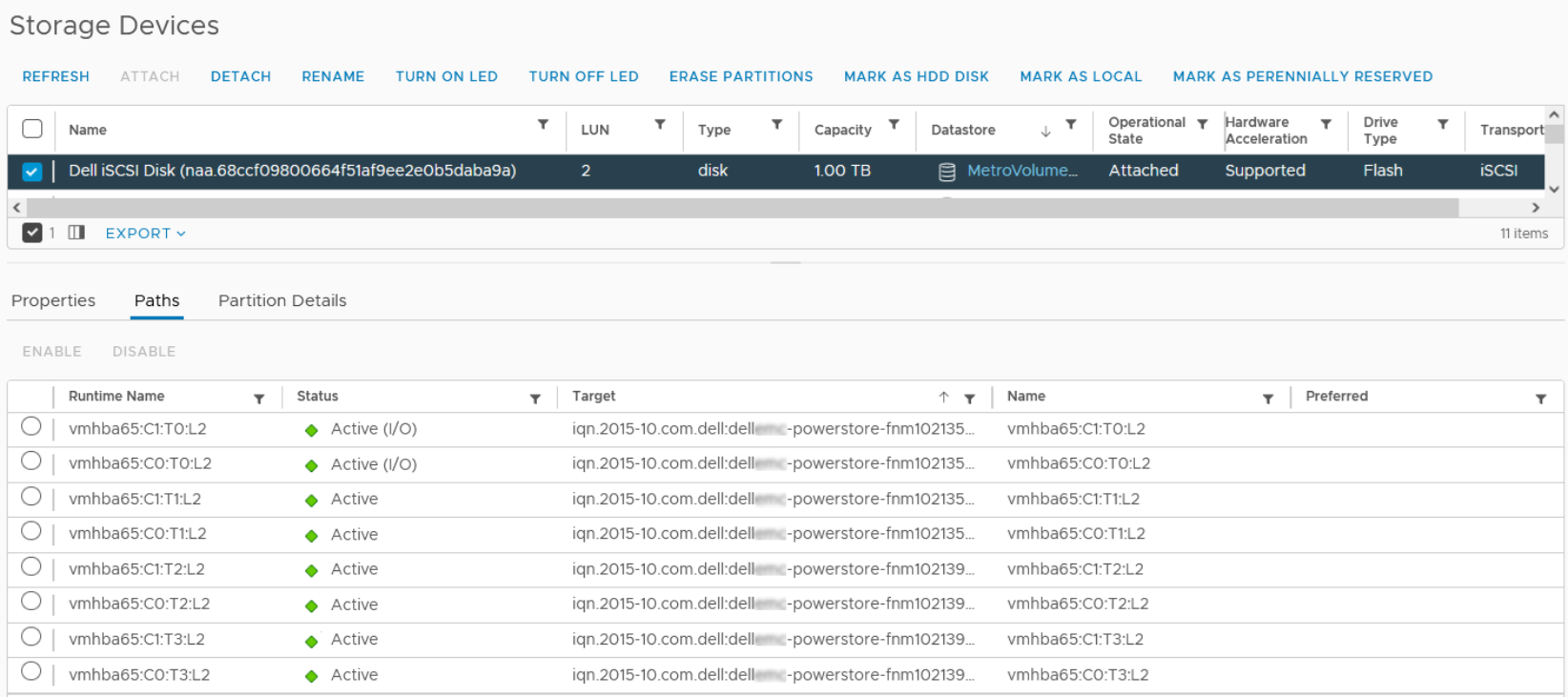
Figure 10. vCenter > Storage Devices > Paths view
VMware NMP chooses the working path and indicates the status in vCenter. The NMP selected working path may not always be the Active-Optimized path. Possible path states in vCenter are described in the table below.
Table 4. Path states in vSphere Client
State in vCenter
Description
Active (I/O)
Indicates the working path for a volume. It might be the
Active-Optimized path, or another active path selected by NMPActive
Indicates an active path for a volume.
Dead
Path is not available for host I/O to the volume.
esxcli provides more detail for the paths used for a device. For a particular device mapped to an ESXi host, you can use the following command to show the path details. The device id (naa.68ccf…) is available either in the PowerStore Manager volume overview, in vSphere, or by using esxcli. The following figure shows two commands how to access the information. While device list gives a comprehensive overview of paths for the device, the option path list shows details for all paths to a volume and includes the runtime name as used in vCenter UI.
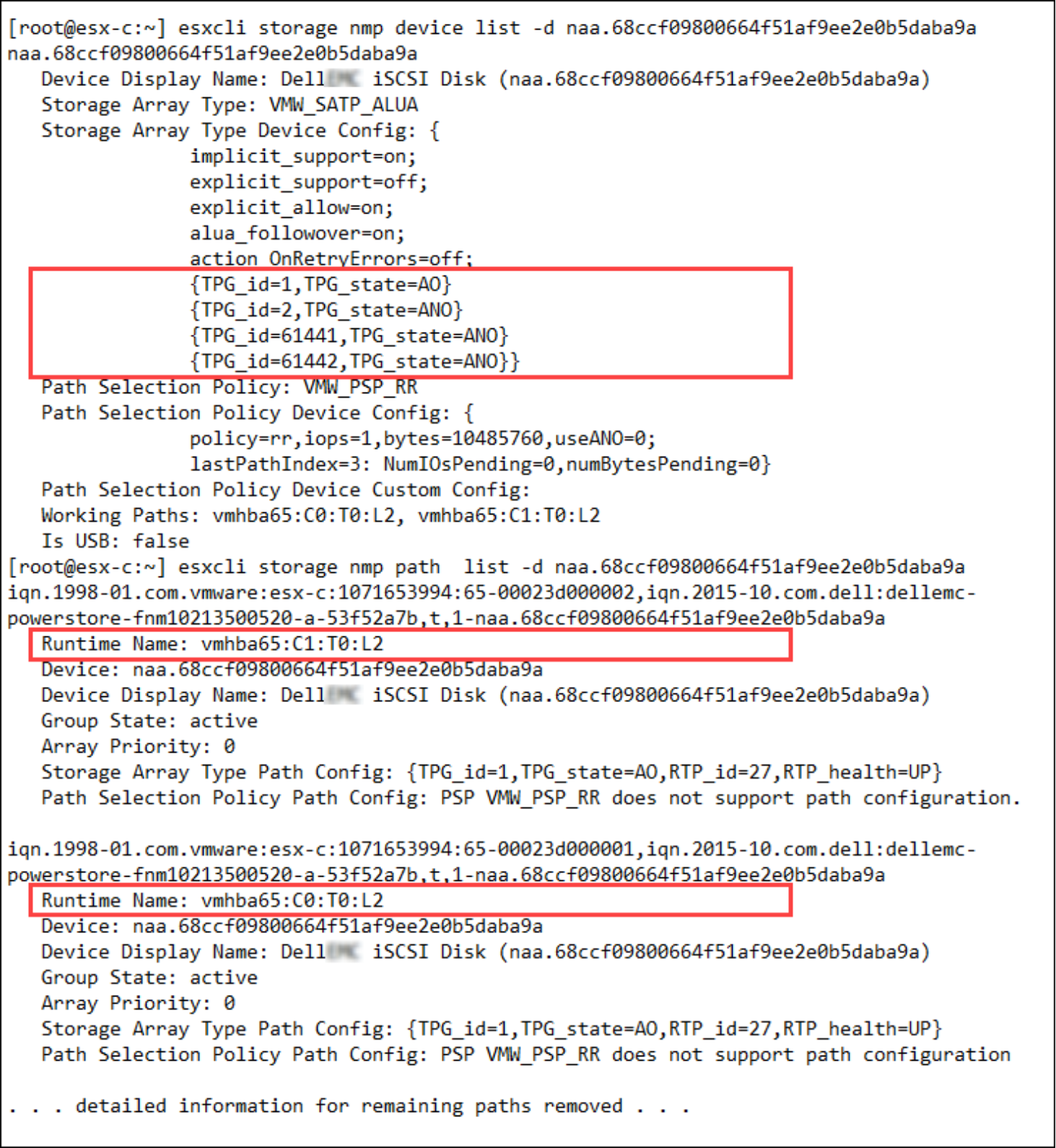
Figure 11. esxcli mapping TPG_id to Runtime Name
Note: TPG state identifies the active-optimal and active-non-optimal ALUA state for each target port group. PowerStore has one target port group per node. Working Paths identifies each active-optimal path in use as derived from the target port groups. Working Paths corresponds with Active (I/O) in the vSphere Client UI.
The following table shows the different possible TPG_states which also represent the PowerStore-provided ALUA path information.
Table 5. esxcli path states
TPG_state
in esxcliALUA path state
Description
AO
Active-optimized
Indicates the optimized path for
host I/O to the volume and can be controlled with Volume Node-Affinity setting in PowerStore CLI or REST API.ANO
Active-non-optimized
Path is available, but not optimized for host I/O to the volume.
UNAVAIL
Unavailable
Path is not available for host I/O to the volume.
If there is a single-node failure, PowerStore does not switch the Active-Optimized path to the remaining node. With the default iops-based NMP, NMP round-robin selects all remaining active-non-optimized as working path (see below).
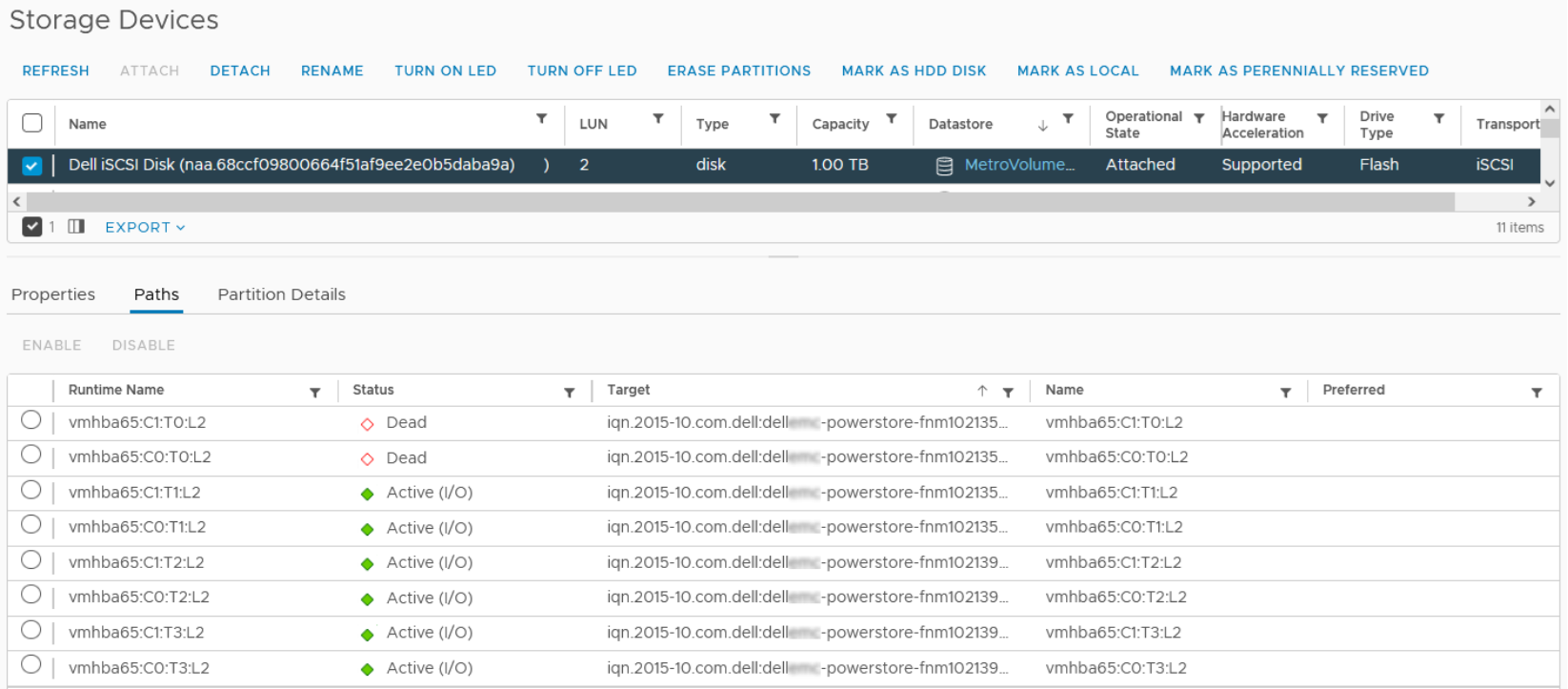
Figure 12. vCenter path states during a node failure
This scenario could lead to a performance impact because there is probability that NMP chose the remote PowerStore cluster with higher latency for I/O. For mitigation, you can change the device configuration to NMP round-robin with the latency mechanism. The commands in the figure below show an example of the commands to check (deviceconfig get) and change (deviceconfig set) the NMP round-robin mechanism to latency-based round-robin.
Note: The below command is applied per-host and per-device.
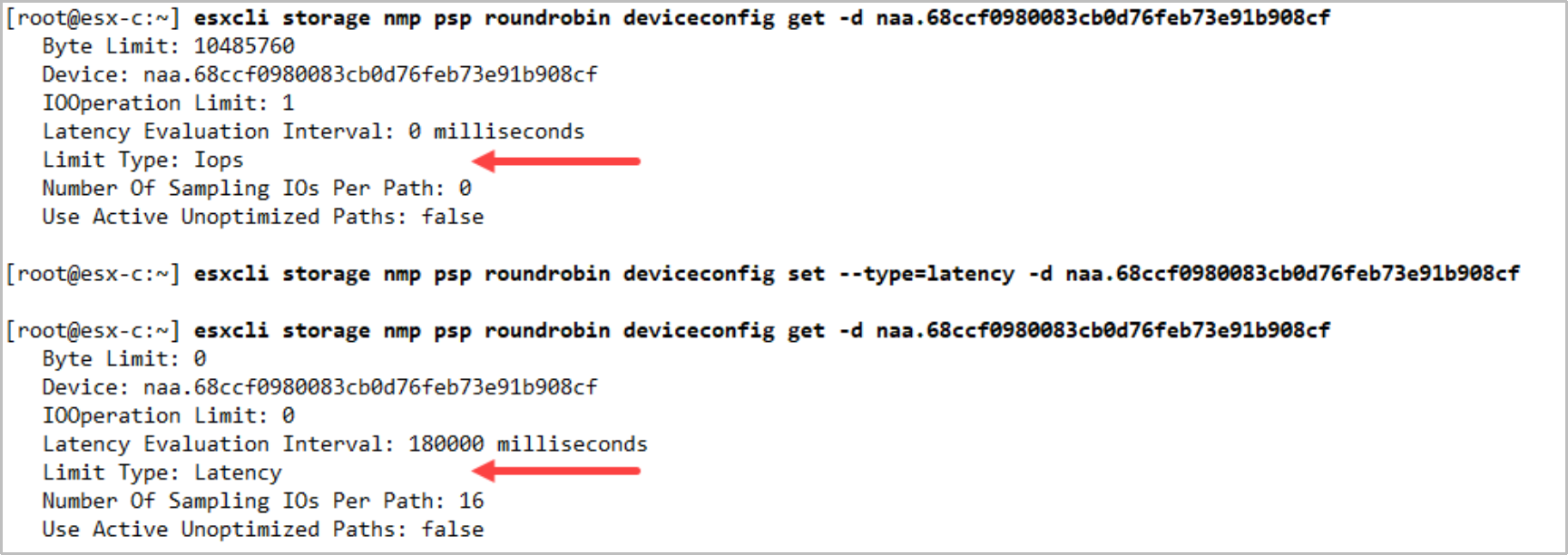
Figure 13. Change NMP round-robin to latency mechanism
You can use a claim rule to implement the latency policy for PowerStore devices. You must add this claim rule to each ESXi host. After you apply the claim rule, each newly discovered device has the claim rules applied to it (devices already discovered before the claim rule is applied will not).
Note: The following commands are for vSphere 7/8 ESXi hosts. ESXi 6.7 hosts should also include the disable_action_OnRetryErrors option. See the PowerStore Host Configuration Guide for more information.
esxcli storage nmp satp rule add -c tpgs_on -e "PowerStore" -M PowerStore -P VMW_PSP_RR -O "policy=latency" -s VMW_SATP_ALUA -t vendor -V DellEMC
You can also add the claim rule to ESXi hosts using the PowerCLI.
# Add or remove a claim rule on each vSphere host
$esxlist | ForEach-Object {
$esxcli = Get-EsxCli -VMHost $_ -V2
# Fill the hash table (optional params are not required)
$sRule = @{
satp = 'VMW_SATP_ALUA' #esxcli: -s
psp = 'VMW_PSP_RR' #esxcli: -P
pspoption = 'policy=latency' #esxcli: -O
claimoption = 'tpgs_on' #esxcli: -c
#option = 'disable_action_OnRetryErrors' #esxcli: -o
vendor = 'DellEMC' #esxcli: -V
model = 'PowerStore' #esxcli: -M
description = 'PowerStore' #esxcli: -e
}
# Call the esxcli command to add/remove the rule
Write-Host $selection "rule on" $_
$esxcli.storage.nmp.satp.rule.$selection.Invoke($sRule)
The Fixed PSP may be desirable when a preferred path on the storage fabric should be used. As shown in the figure below, you should set the MPIO policy on the vSphere host to Fixed with the preferred path leading to vmhba3:C0:T1:L3. Using the Fixed PSP generally requires more administrative effort to implement, maintain, and document.
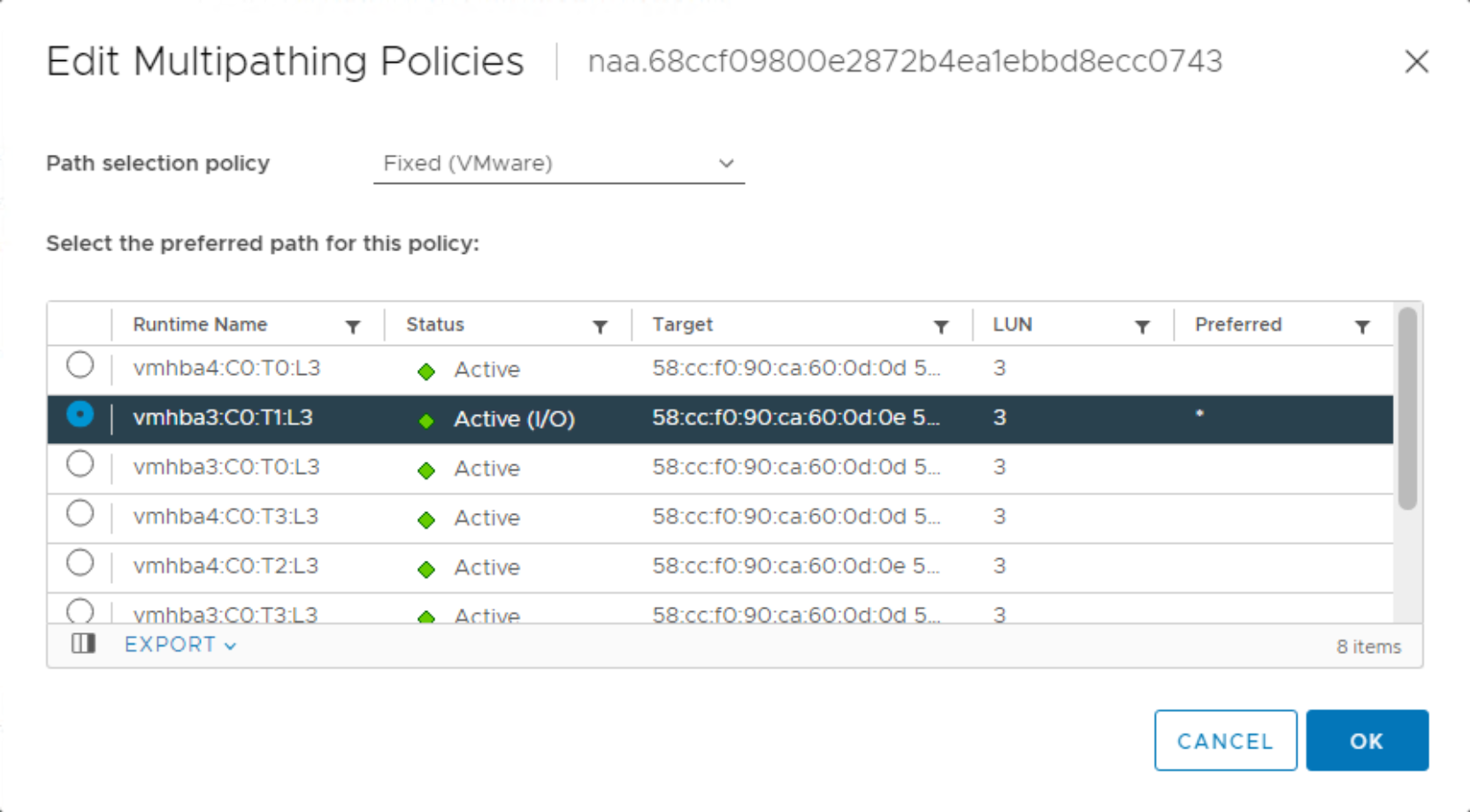
Figure 14. Fixed path selection policy
If host connectivity is modified to a new value, causing I/O to be sent down an active/non-optimal path, PowerStore is designed to report the ALUA path state changes to the vSphere host using the following process:
- Host connectivity is modified to a new value causing I/O to be sent down an active-non-optimal path.
- The vSphere hosts send Round Robin I/O to an active/non-optimal path.
- PowerStore fails the I/O with a Unit Attention Check condition.
- The vSphere host requests Report Target Port Groups.
- PowerStore responds with new ALUA state changes.
- vSphere begins Round Robin I/O over new optimal paths.
Note: You can view the Unit Attention Check Condition in /var/log/vmkernel.log in the following example. For more information, see the VMware KB article, Interpreting SCSI sense codes in VMware ESXi and ESX (289902).
2022-04-28T01:53:52.332Z cpu11:2097789)NMP: nmp_ThrottleLogForDevice:3867: Cmd 0x89 (0x45b8c3883988, 2097177) to dev "naa.68ccf0980080631b71144f5e582abe31" on path "vmhba3:C0:T0:L2" Failed:
2022-04-28T01:53:52.332Z cpu11:2097789)NMP: nmp_ThrottleLogForDevice:3875: H:0x0 D:0x2 P:0x0 Valid sense data: 0x6 0x2a 0x6. Act:FAILOVER. cmdId.initiator=0x430541297ec0 CmdSN 0x1b191
In previous testing, we discovered that vSphere did not consistently or reliably begin using the new optimal paths immediately after an ALUA state changed had occurred. Instead, up to five minutes elapsed before vSphere recognized the ALUA path state change. This means that vSphere may continue to follow the Round Robin policy over non-optimal paths for up to five minutes.
If you observe this condition and are concerned about this behavior occurring in your environments, there are two workarounds:
- After a known ALUA state change, perform a vSphere storage rescan.
Reduce the vSphere host advanced setting Disk.PathEvalTime from the default of 300 seconds down to an acceptable automatic storage rescan interval. If you choose this approach, you must perform this action on each vSphere host where the host connectivity was changed.
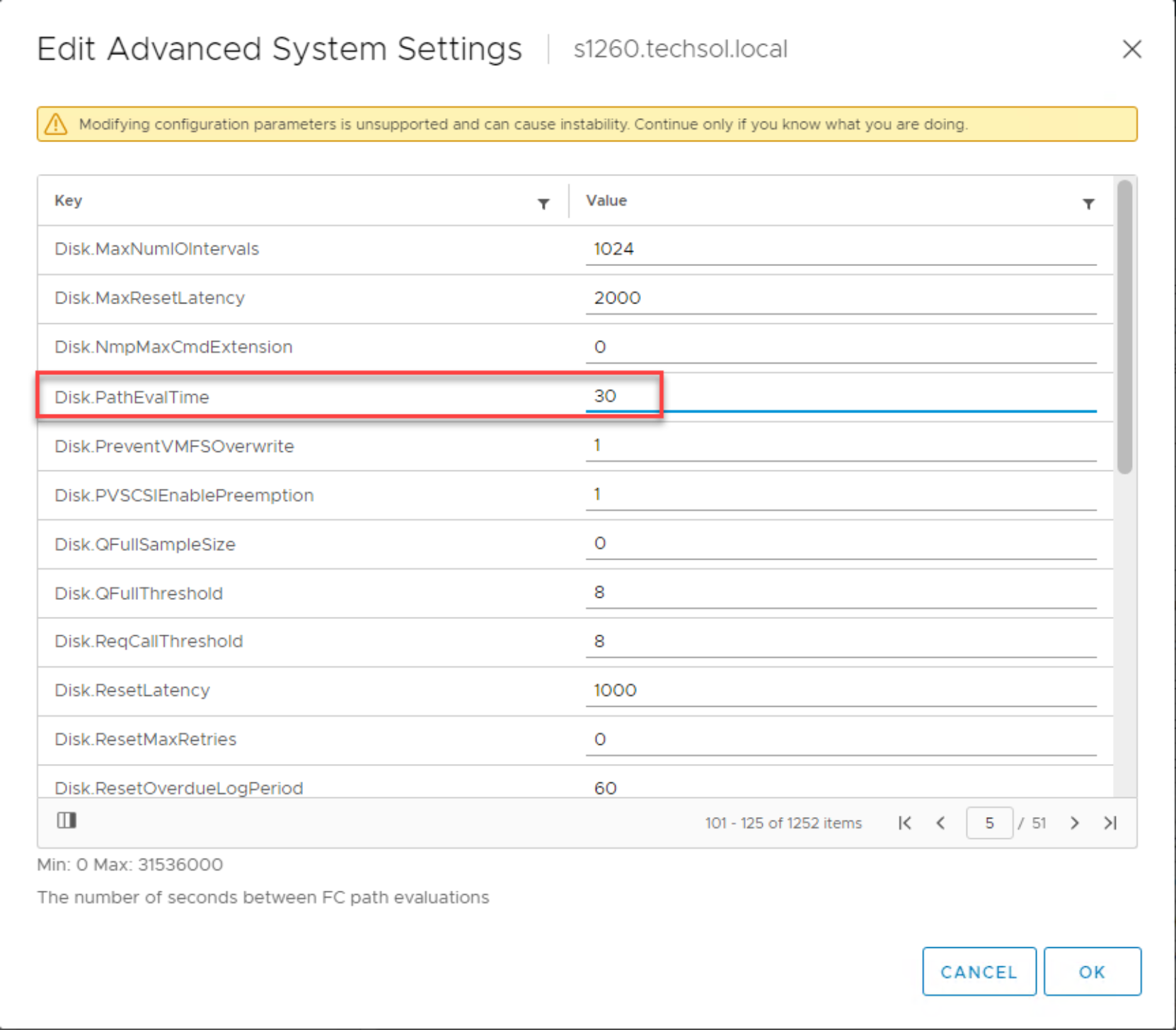
Figure 15. Example: Reducing the Disk.PathEvalTime setting to 30 seconds on a vSphere host