
PowerStore deduplication and compression
PowerStore deduplication and compression
-
Deduplication and compression within a PowerStore appliance occur as data is copied from the appliance’s DRAM memory-based write cache to the data drives within the system. During this process, data is stored within the back-end storage in full stripe writes, which are created with the data remaining after it is passed through the deduplication and compression process. Figure 5 outlines this process at a high level for each PowerStore model.
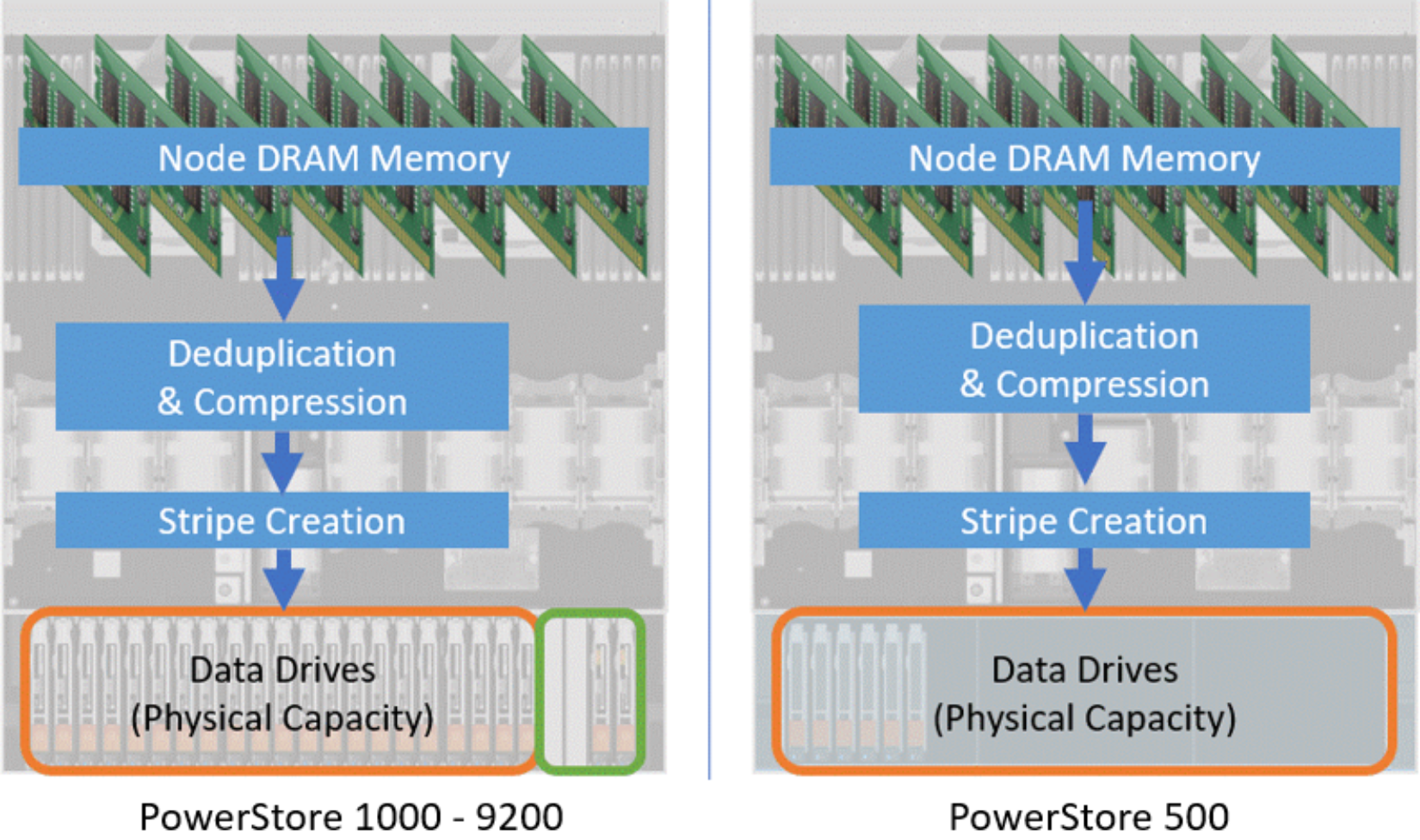
Figure 5. Data being stored in the data drives
All writes to the system pass through deduplication and compression logic to ensure the data is stored as efficiently as possible. These software features are part of PowerStore data path operations and cannot be disabled by the user. In releases prior to the PowerStoreOS 2.0 release, deduplication and compression are always engaged inline and cannot be bypassed. In the PowerStoreOS 2.0 release and later, PowerStore will dynamically prioritize workload performance and defer deduplication operations to a period in time with a less extreme I/O demand. If this occurs, compression remains enabled and continues to achieve space savings. Once deduplication is resumed, blocks that were skipped are passed through the deduplication algorithm to determine if deduplication can occur. Used space is recovered if deduplication can be achieved.
When data is passed through the deduplication and compression logic, it first passes through common pattern detection, reviewing the data for all zeros or ones. If one of these patterns is matched, deduplication occurs and the metadata within the resource is updated to state what data pattern was found in that location. The metadata for a resource tells the system how it can re-create or locate data for an address within a storage resource. For example, if 4 KB of zeros were deduplicated, starting at a particular address within the resource, the metadata would have information to provide zeros as a response for that address if it is requested.
If a pattern was not found, the data is passed through the deduplication algorithm. This algorithm first creates a fingerprint for each 4 KB block of data within the resource using a hashing algorithm. Once created, the fingerprint is compared to other fingerprints which represent data within the PowerStore single deduplication domain. The deduplication domain allows data for any resource within the appliance to deduplicate. If a match is found, the physical storage is single-instanced. If a match is not found, the data is compressed and placed into a full stripe write to be written to the system. In PowerStoreOS 4.0, the compression algorithm has been enhanced to allow multiple blocks of data to be compressed together. This change potentially allows for higher savings in blocks that otherwise would not see it.
In releases prior to PowerStoreOS 2.0, the fingerprint cache is fixed in size and resides in system memory. Due to the fixed size, older fingerprints may be replaced with newer fingerprints, potentially reducing the ability to achieve deduplication to previously written data. In PowerStoreOS 2.0 and higher, the fingerprint cache can expand into the data drives, consuming space as needed to store fingerprints. This allows the system to retain all fingerprints created on the appliance, potentially allowing for larger deduplication savings than in previous releases. The entire fingerprint cache is also mirrored within the data drives in the 2.0 release, protecting it against unforeseen issues.
Figure 6 shows an example of the result of the deduplication and compression logic within the PowerStore system. In this example, Resource 1 and Resource 2 have written four blocks of data each, and they are stored within the system. Deduplication within the PowerStore system allows blocks from different resources to deduplicate, reducing the amount of space consumed by duplicate data within the system. In this example, Block A is unique to Resource 1, and it is only referenced by Resource 1. Block E is present in both resources, and has deduplicated within the system, thus saving space. Further savings can be achieved if the data is compressible, as the resources can both reference a compressed block.
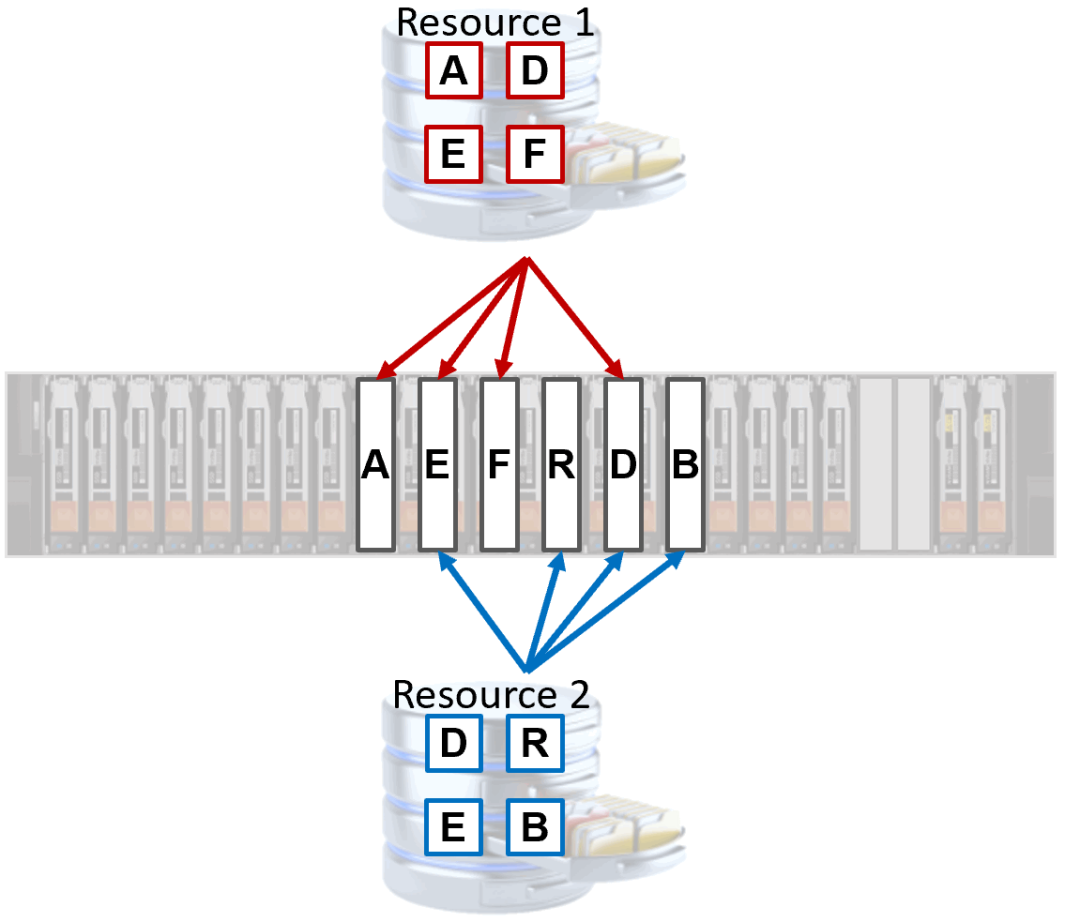
Figure 6. Deduplication example in PowerStore