
SmartDedupe monitoring and reporting
SmartDedupe monitoring and reporting
-
Deduplication efficiency reporting
OneFS provides several command-line and WebUI tools to help assess the benefits of deduplication across a cluster:
- The amount of disk space saved by SmartDedupe can be determined by viewing the cluster capacity usage chart and deduplication reports summary table in the WebUI. The cluster capacity chart and deduplication reports can be found by browsing to File System Management > Deduplication > Summary.
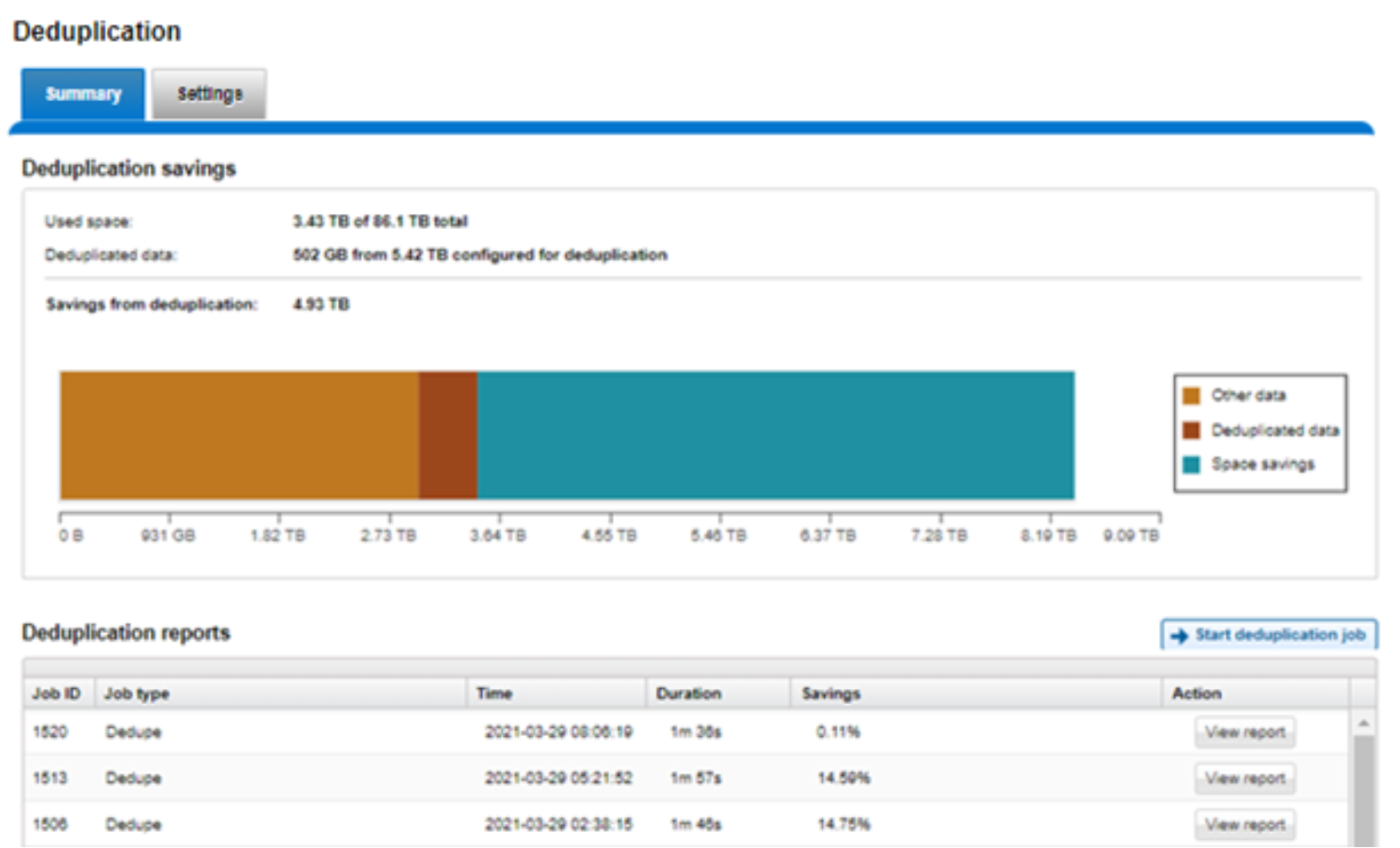
Figure 36. SmartDedupe cluster capacity savings WebUI chart
- In addition to the bar chart and accompanying statistics (above), which graphically represents the data set and space efficiency in actual capacity terms, the dedupe job report overview field also displays the SmartDedupe savings as a percentage.
SmartDedupe space efficiency metrics are also provided by the ‘isi dedupe stats’ CLI command:
# isi dedupe stats
Cluster Physical Size: 86.14T
Cluster Used Size: 3.43T
Logical Size Deduplicated: 4.01T
Logical Saving: 3.65T
Estimated Size Deduplicated: 5.42T
Estimated Physical Saving: 4.93T
Figure 37. SmartDedupe Efficiency Statistics from the CLI
- The most comprehensive of the data reduction reporting CLI utilities is the ‘isi statistics data-reduction’ command, which reports deduplication capacity savings and the deduplication ratio. For example:
# isi statistics data-reduction
Recent Writes Cluster Data Reduction
(5 mins)
--------------------- ------------- ----------------------
Logical data 6.18M 6.02T
Zero-removal saved 0 -
Deduplication saved 56.00k 3.65T
Compression saved 4.16M 1.96G
Preprotected physical 1.96M 2.37T
Protection overhead 5.86M 910.76G
Protected physical 7.82M 3.40T
Zero removal ratio 1.00 : 1 -
Deduplication ratio 1.01 : 1 2.54 : 1
Compression ratio 3.12 : 1 1.02 : 1
Data reduction ratio 3.15 : 1 2.54 : 1
Efficiency ratio 0.79 : 1 1.77 : 1
--------------------- ------------- ----------------------
The ‘recent writes’ data to the left of the output provides precise statistics for the five-minute period prior to running the command. By contrast, the ‘cluster data reduction’ metrics on the right of the output are slightly less real-time but reflect the overall data and efficiencies across the cluster.
- In OneFS 8.2.1 and later, SmartQuotas has been enhanced to report the capacity saving from deduplication, and data reduction in general, as a storage efficiency ratio. SmartQuotas reports efficiency as a ratio across the desired data set as specified in the quota path field. The efficiency ratio is for the full quota directory and its contents, including any overhead, and reflects the net efficiency of compression and deduplication. On a cluster with licensed and configured SmartQuotas, this efficiency ratio can be easily viewed from the WebUI by browsing to ‘File System > SmartQuotas > Quotas and Usage’.
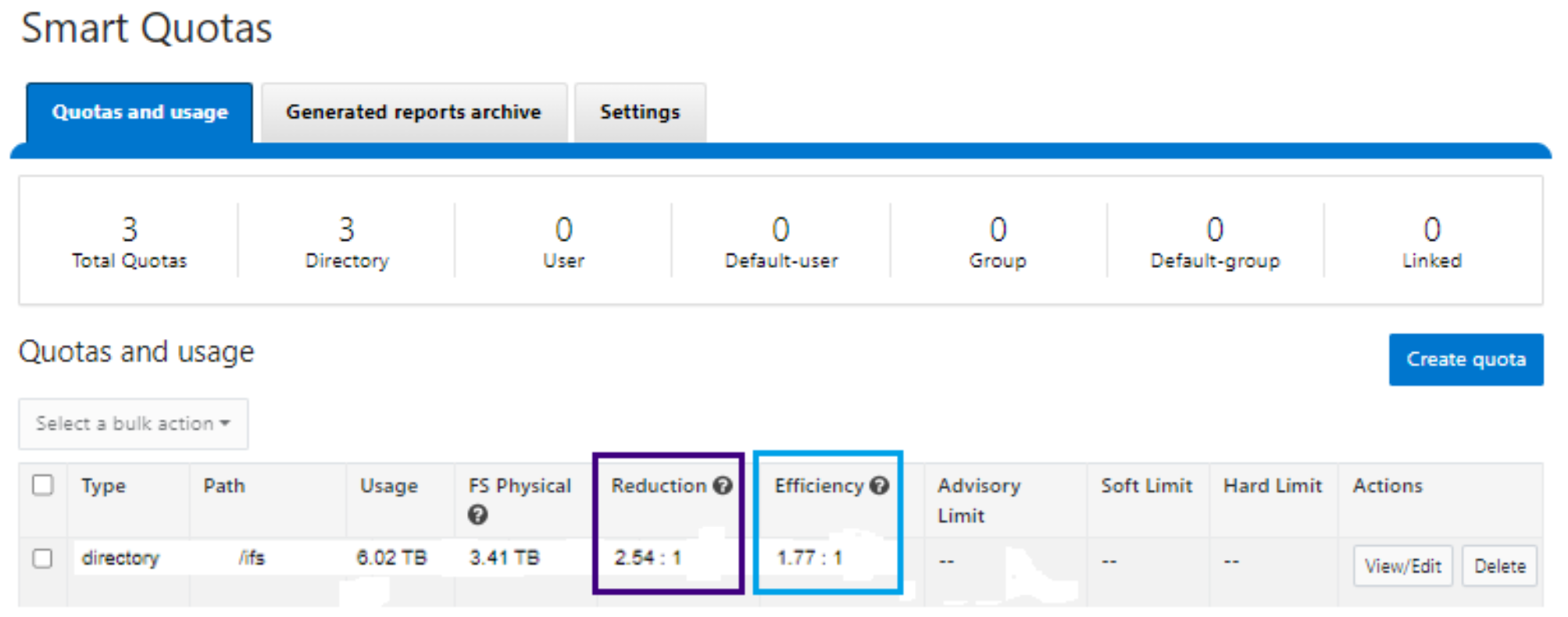
Figure 38. OneFS WebUI SmartQuotas quotas and usage status detailing efficiency and data reduction ratio
- Similarly, the same data can be accessed from the OneFS command line by the ‘isi quota quotas list’ CLI command. For example:

- Example output from the ‘isi quota quotas list’ CLI command.More detail, including both the physical (raw) and logical (effective) data capacities, is also available using the ‘isi quota quotas view <path> <type>’ CLI command. For example:
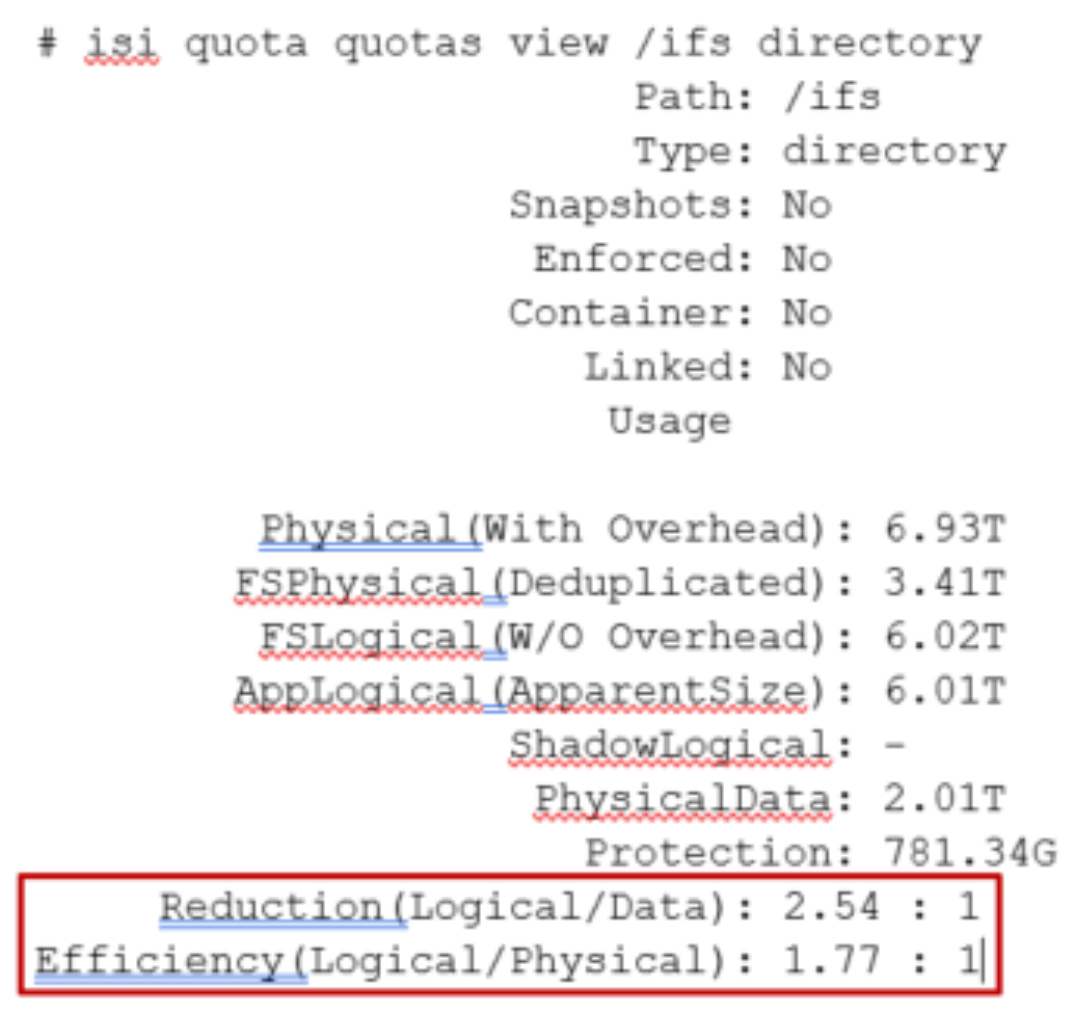
Figure 39. Example output from the ‘isi quota quotas view’ CLI command
To configure SmartQuotas for data efficiency reporting, create a directory quota at the top-level file system directory of interest, for example /ifs. Creating and configuring a directory quota is a simple procedure and can be performed from the WebUI, as follows:
Browse ‘File System > SmartQuotas > Quotas and Usage’ and select ‘Create a Quota’. In the create pane, field, set the Quota type to ‘Directory quota’, add the preferred top-level path to report on, select ‘File system logical size’ for Quota Accounting, and set the Quota Limits to ‘Track storage without specifying a storage limit’. Finally, select the ‘Create Quota’ button to confirm the configuration and activate the new directory quota.
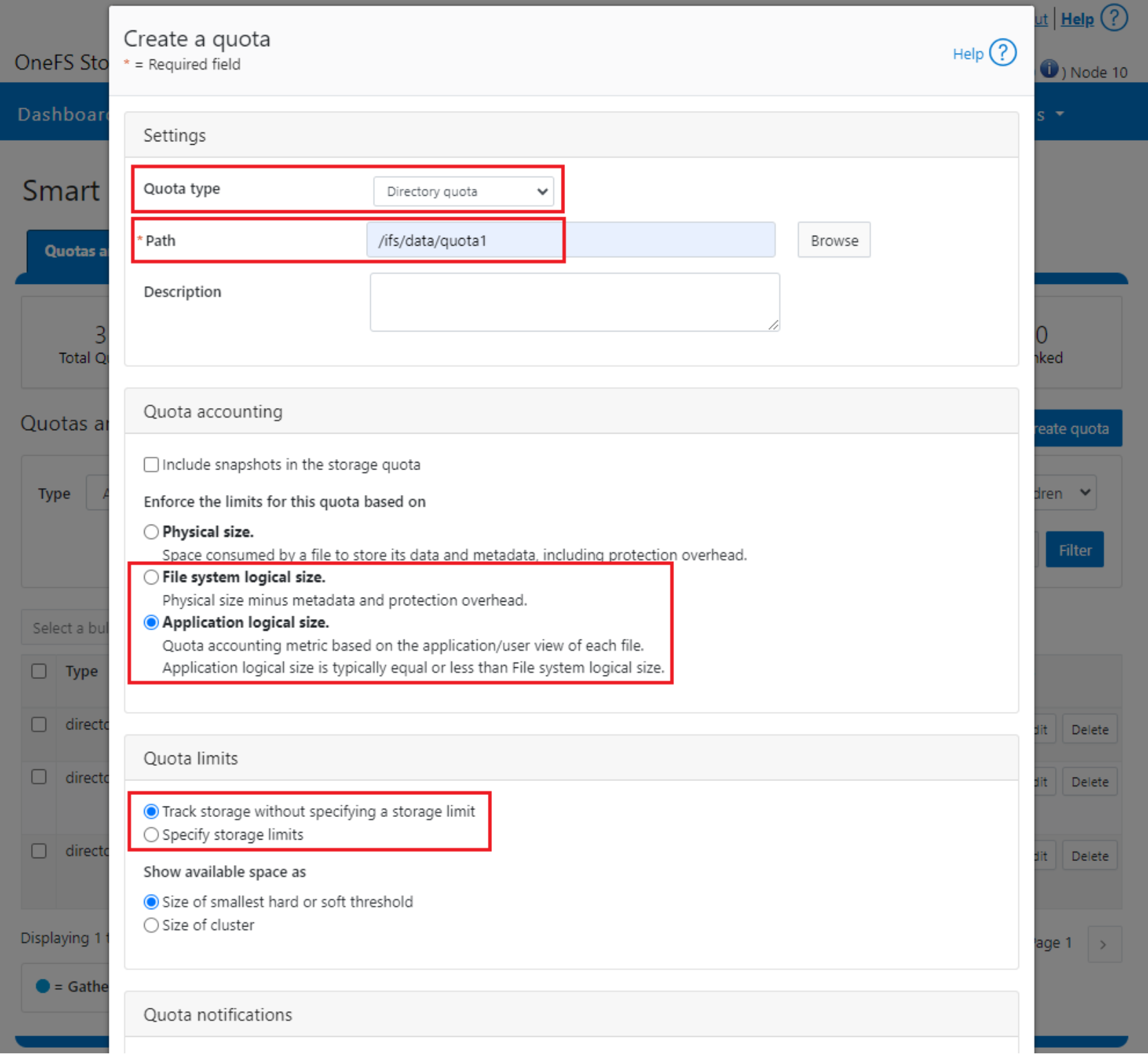
Figure 40. OneFS WebUI SmartQuotas directory quota configuration
The efficiency ratio is a single, current-in time efficiency metric that is calculated per quota directory and includes the sum of SmartDedupe plus inline data reduction. This is in contrast to a history of stats over time, as reported in the ‘isi statistics data-reduction’ CLI command output, described above. As such, the efficiency ratio for the entire quota directory will reflect what is there.
- The OneFS WebUI cluster dashboard also now displays a storage efficiency tile, which shows physical and logical space utilization histograms and reports the capacity saving from inline data reduction as a storage efficiency ratio. This dashboard view is displayed by default when opening the OneFS WebUI in a browser and can be easily accessed by browsing to ‘File System > Dashboard > Cluster Overview’.
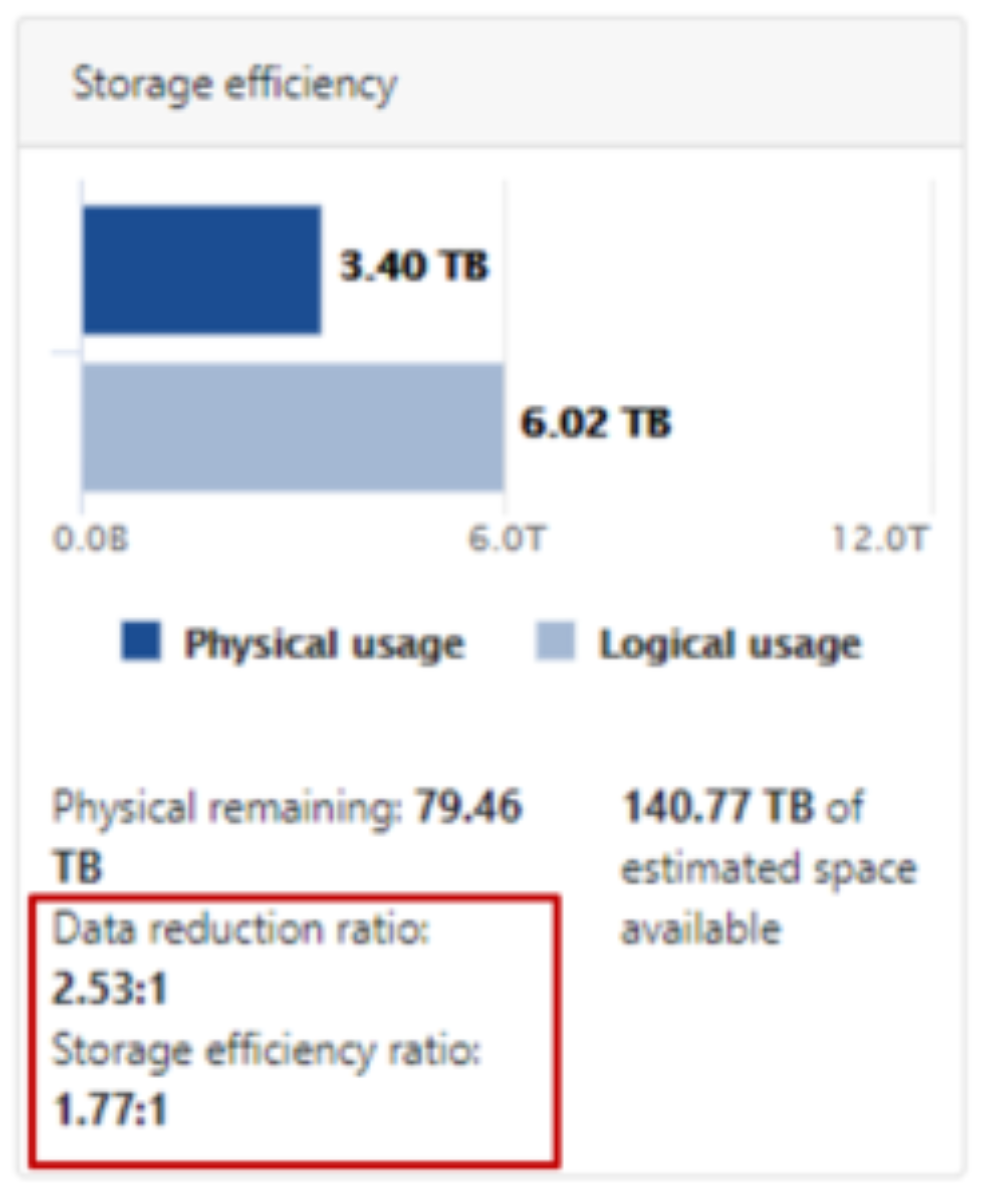
Figure 41. OneFS WebUI cluster status dashboard – storage efficiency summary tile
- Similarly, the ‘isi status’ CLI command output includes a ‘Data Reduction’ field:
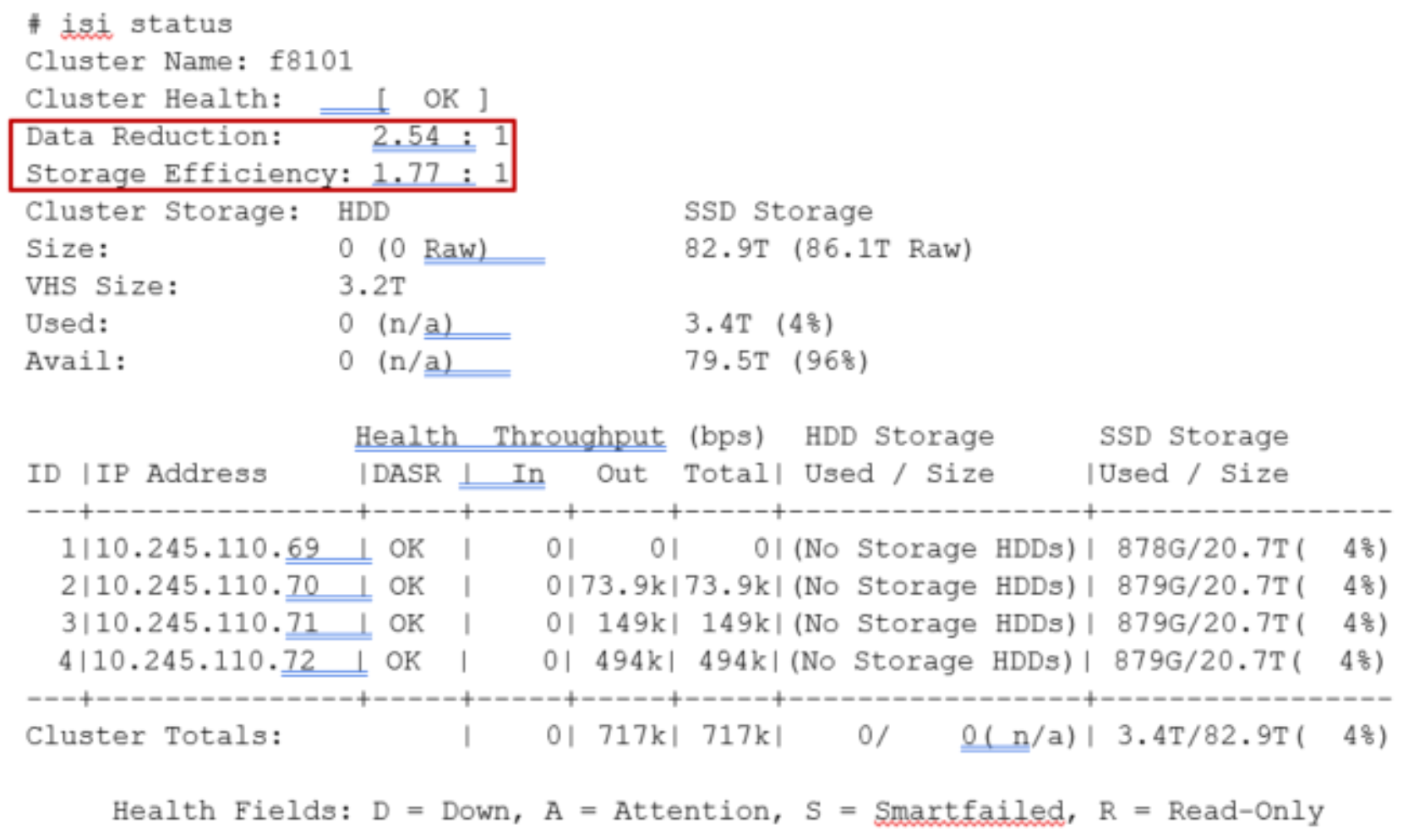
Figure 42. Example output from the ‘isi status’ CLI command showing data reduction and storage efficiency ratios.
SmartDedupe job progress
The Job Engine parallel execution framework provides comprehensive run time and completion reporting for the deduplication job.
While SmartDedupe is underway, job status is available at a glance in the progress column in the active jobs table. This information includes the number of files, directories, and blocks that have been scanned, skipped, and sampled, and any errors that may have been encountered.
Additional progress information is provided in an Active Job Details status update, which includes an estimated completion percentage based on the number of logical inodes (LINs) that have been counted and processed.
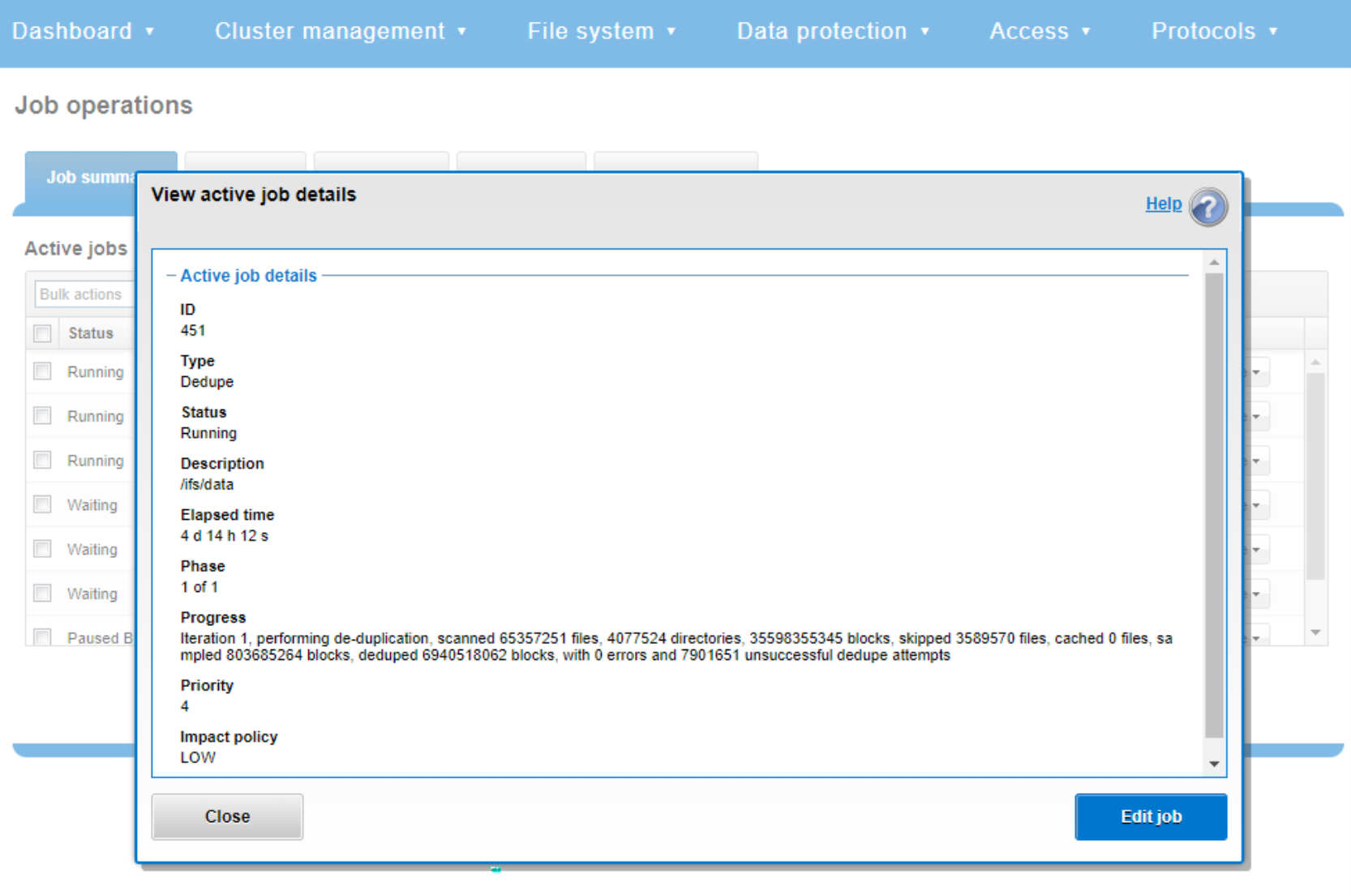
Figure 43. Example of active job status update
SmartDedupe job reports
After the SmartDedupe job has run to completion, or has been terminated, a full dedupe job report is available. This can be accessed from the WebUI by browsing to Cluster Management > Job Operations > Job Reports and selecting ‘View Details’ action button on the desired Dedupe job line item.
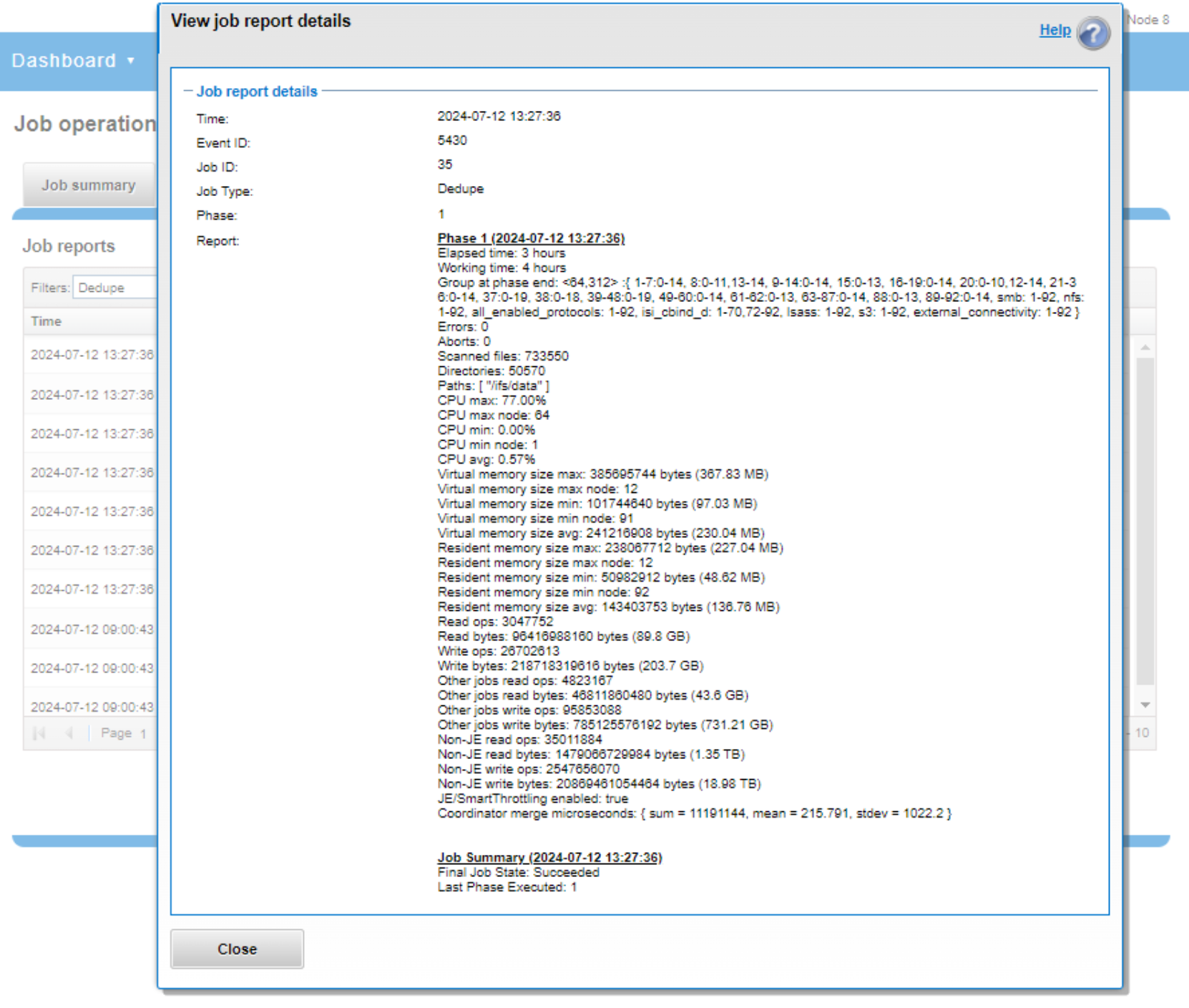
Figure 44. Example of WebUI dedupe job report
The job report contains the following relevant dedupe metrics.
Table 12. Dedupe job report statistics
Report field
Description of metric
Start time
When the dedupe job started.
End time
When the dedupe job finished.
Scanned blocks
Total number of blocks scanned under configured path(s).
Sampled blocks
Number of blocks that OneFS created index entries for.
Created dedupe requests
Total number of dedupe requests created. A dedupe request gets created for each matching pair of data blocks. For example, three data blocks all match, two requests are created: One request to pair file1 and file2 together, the other request to pair file2 and file3 together.
Successful dedupe requests
Number of dedupe requests that completed successfully.
Failed dedupe requests
Number of dedupe requests that failed. If a dedupe request fails, it does not mean that the also job failed. A deduplication request can fail for any number of reasons. For example, the file might have been modified since it was sampled.
Skipped files
Number of files that were not scanned by the deduplication job. The primary reason is that the file has already been scanned and has not been modified since. Another reason for a file to be skipped is if it is less than 32KB in size. Such files are considered too small and do not provide enough space saving benefit to offset the fragmentation they will cause.
Index entries
Number of entries that exist in the index.
Index lookup attempts
Cumulative total number of lookups that have been done by prior and current deduplication jobs. A lookup is when the deduplication job attempts to match a block that has been indexed with a block that hasn’t been indexed.
Index lookup hits
Total number of lookup hits that have been done by earlier deduplication jobs plus the number of lookup hits done by this deduplication job. A hit is a match of a sampled block with a block in index.
Dedupe job reports are also available from the CLI by the isi job reports view <job_id> command.
Note: From an execution and reporting stance, the Job Engine considers the ‘dedupe’ job to contain a single process or phase. The Job Engine events list will report that Dedupe Phase1 has ended and succeeded. This indicates that an entire SmartDedupe job, including all four internal dedupe phases (sampling, duplicate detection, block sharing, and index update), has successfully completed.
For example:
# isi job events list --job-type dedupe
Time Message
------------------------------------------------------
2020-02-01T13:39:32 Dedupe[1955] Running
2020-02-01T13:39:32 Dedupe[1955] Phase 1: begin dedupe
2020-02-01T14:20:32 Dedupe[1955] Phase 1: end dedupe
2020-02-01T14:20:32 Dedupe[1955] Phase 1: end dedupe
2020-02-01T14:20:32 Dedupe[1955] Succeeded
Figure 45. Example of command line (CLI) dedupe job events list
For deduplication reporting across multiple OneFS clusters, SmartDedupe is also integrated with InsightIQ cluster reporting and analysis product. A report detailing the space savings delivered by deduplication is available from InsightIQ’s File Systems Analytics module.
Space savings estimation with the SmartDedupe assessment job
To complement the actual Dedupe job, a dry run Dedupe Assessment job is also provided to help estimate the amount of space savings that will be seen by running deduplication on a particular directory or set of directories. The dedupe assessment job reports a total potential space savings. The dedupe assessment does not differentiate the case of a fresh run from the case where a previous dedupe job has already done some sharing on the files in that directory. The assessment job does not provide the incremental differences between instances of this job. Dell Technologies recommends that the user should run the assessment job once on a specific directory before starting an actual dedupe job on that directory.
The assessment job runs similarly to the actual dedupe job but uses a separate configuration. It also does not require a product license and can be run prior to purchasing SmartDedupe in order to determine whether deduplication is appropriate for a particular data set or environment.
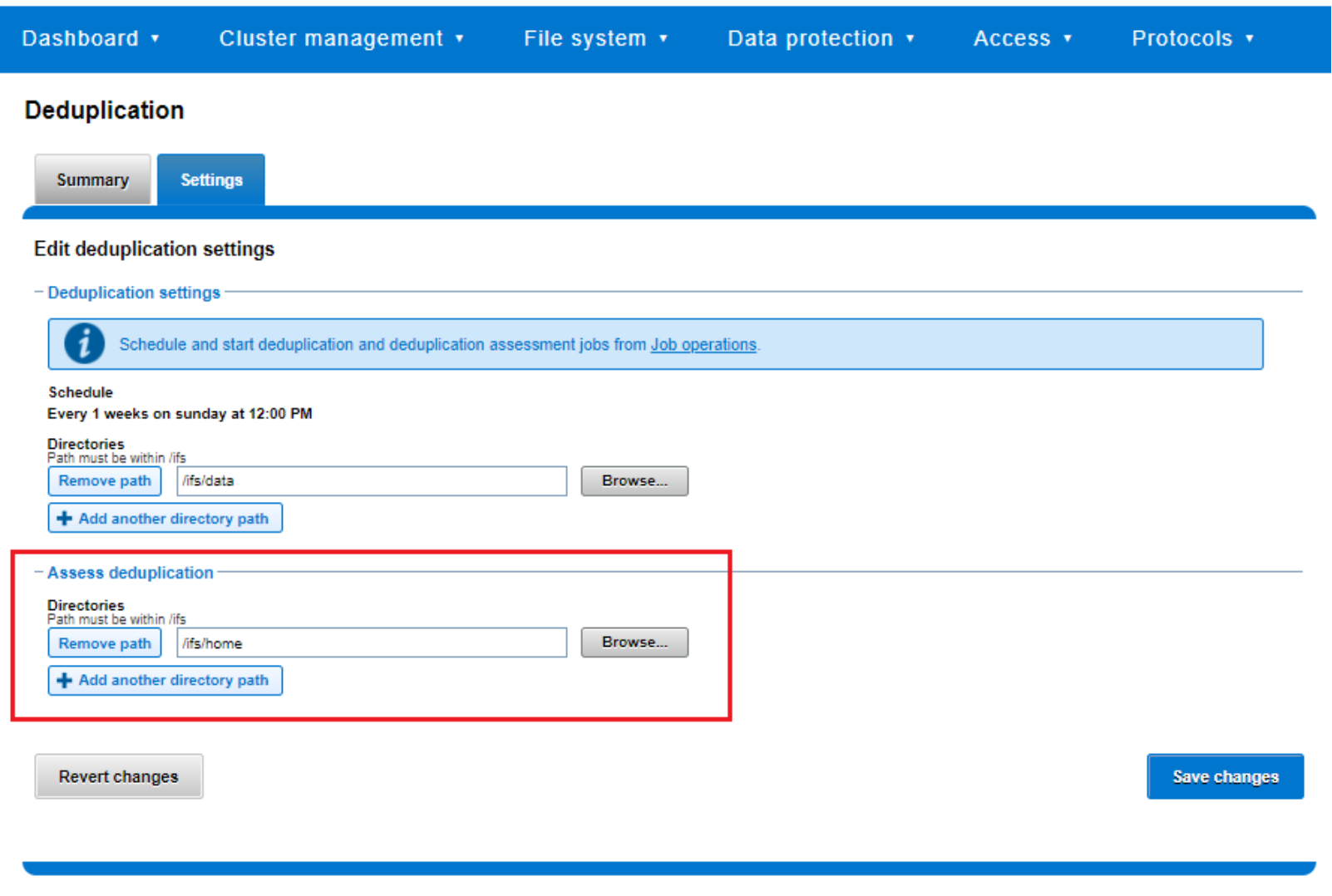
Figure 46. Deduplication assessment job configuration
The dedupe assessment job uses a separate index table. For efficiency, the assessment job also samples fewer candidate blocks than the main dedupe job and does not actually perform deduplication. Using the sampling and consolidation statistics, the job provides a report which estimates the total dedupe space savings in bytes.
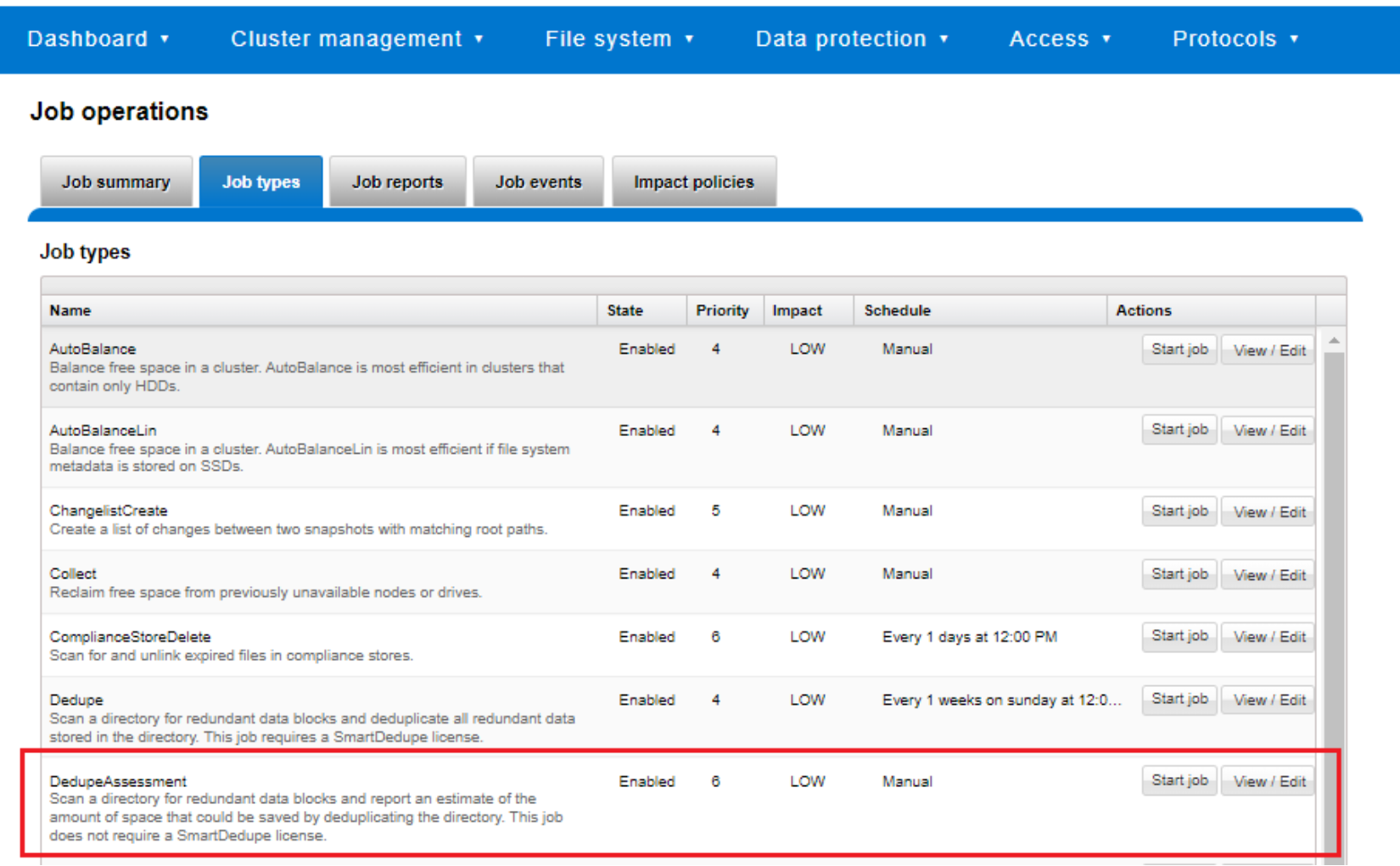
Figure 47. Dedupe assessment job control using the OneFS WebUI
Performance with SmartDedupe
As with most things in life, deduplication is a compromise. In order to gain increased levels of storage efficiency, additional cluster resources (CPU, memory, and disk IO) are used to find and execute the sharing of common data blocks.
Another important performance impact consideration with dedupe is the potential for data fragmentation. After deduplication, files that previously enjoyed contiguous on-disk layout will often have chunks spread across less optimal file system regions. This can lead to slightly increased latencies when accessing these files directly from disk, rather than from cache. To help reduce this risk, SmartDedupe will not share blocks across node pools or data tiers and will not attempt to deduplicate files smaller than 32KB in size. On the other end of the spectrum, the largest contiguous region that will be matched is 4MB.
Because deduplication is a data efficiency product rather than performance enhancing tool, in most cases the consideration will be around cluster impact management. This is from both the client data access performance front, since, by design, multiple files will be sharing common data blocks, and also from the dedupe job execution perspective, as additional cluster resources are consumed to detect and share commonality.
The first deduplication job run will often take a substantial amount of time to run, since it must scan all files under the specified directories to generate the initial index and then create the appropriate shadow stores. However, deduplication job performance will typically improve significantly on the second and subsequent job runs (incrementals), once the initial index and the bulk of the shadow stores have already been created.
If incremental deduplication jobs do take a long time to complete, this is most likely indicative of a data set with a high rate of change. If a deduplication job is paused or interrupted, it will automatically resume the scanning process from where it left off.
As mentioned previously, deduplication is a long running process that involves multiple job phases that are run iteratively. SmartDedupe typically processes around 1TB of data per day, per node.
SmartDedupe licensing
SmartDedupe is included as a core component of OneFS but requires a valid product license key in order to activate. This license key can be purchased through your Dell account team. An unlicensed cluster will show a SmartDedupe warning until a valid product license has been purchased and applied to the cluster.
License keys can be easily added in the ‘Activate License’ section of the OneFS WebUI, accessed by browsing to Cluster Management > Licensing.
The SmartDedupe dry-run estimation job can be run without any licensing requirements, allowing an assessment of the potential space savings that a dataset might yield before making the decision to purchase the full product.
Note: The PowerScale H700/7000 and A300/3000 nodes ship with a zero-cost SmartDedupe license and are supported on OneFS 9.2.1 and later. On addition of an H700/7000 or A300/3000 nodepool to an existing cluster without a SmartDedupe license, SmartDedupe will automatically be available for configuration and use across the entire cluster. An alert will be generated warning of unlicensed nodes, but this can be safely ignored and quiesced.
Deduplication efficiency
Deduplication can significantly increase the storage efficiency of data. However, the actual space savings will vary depending on the specific attributes of the data itself. As mentioned above, the deduplication assessment job can be run to help predict the likely space savings that deduplication would provide on a given data set.
Virtual machines files often contain duplicate data, much of which is rarely modified. Deduplicating similar OS type virtual machine images (such as VMware VMDK files that have been block-aligned) can significantly decrease the amount of storage space consumed. However, as noted previously, the potential for performance degradation as a result of block sharing and fragmentation should be carefully considered first.
SmartDedupe does not deduplicate across files that have different protection settings. For example, if two files share blocks, but file1 is parity protected at +2:1, and file2 has its protection set at +3, SmartDedupe will not attempt to deduplicate them. This ensures that all files and their constituent blocks are protected as configured. Also, SmartDedupe will not deduplicate files that are stored on different SmartPools storage tiers or node-pools. For example, if file1 and file2 are stored on tier 1 and tier 2 respectively, and tier1 and tier2 are both protected at 2:1, OneFS will not deduplicate them. This helps guard against performance asynchronicity, where some of a file’s blocks could live on a different tier, or class of storage, from the others.
Below are some examples of typical space reclamation levels that have been achieved with SmartDedupe.
Note: These dedupe space savings values are provided solely as rough guidance. Since no two data sets are alike (unless they are replicated), actual results can vary considerably from these examples.
Table 13. Typical workload space savings with SmartDedupe
Workflow/data type
Typical space savings
Virtual Machine Data
35%
Home Directories / File Shares
25%
Email Archive
20%
Engineering Source Code
15%
Media Files
10%