
SmartDedupe management
SmartDedupe management
-
There are two principal elements to managing deduplication in OneFS. The first is the configuration of the SmartDedupe process itself. The second involves the scheduling and execution of the Dedupe job. These are both described below.
Configuring SmartDedupe
SmartDedupe works on data sets which are configured at the directory level, targeting all files and directories under each specified root directory. Multiple directory paths can be specified as part of the overall deduplication job configuration and scheduling.
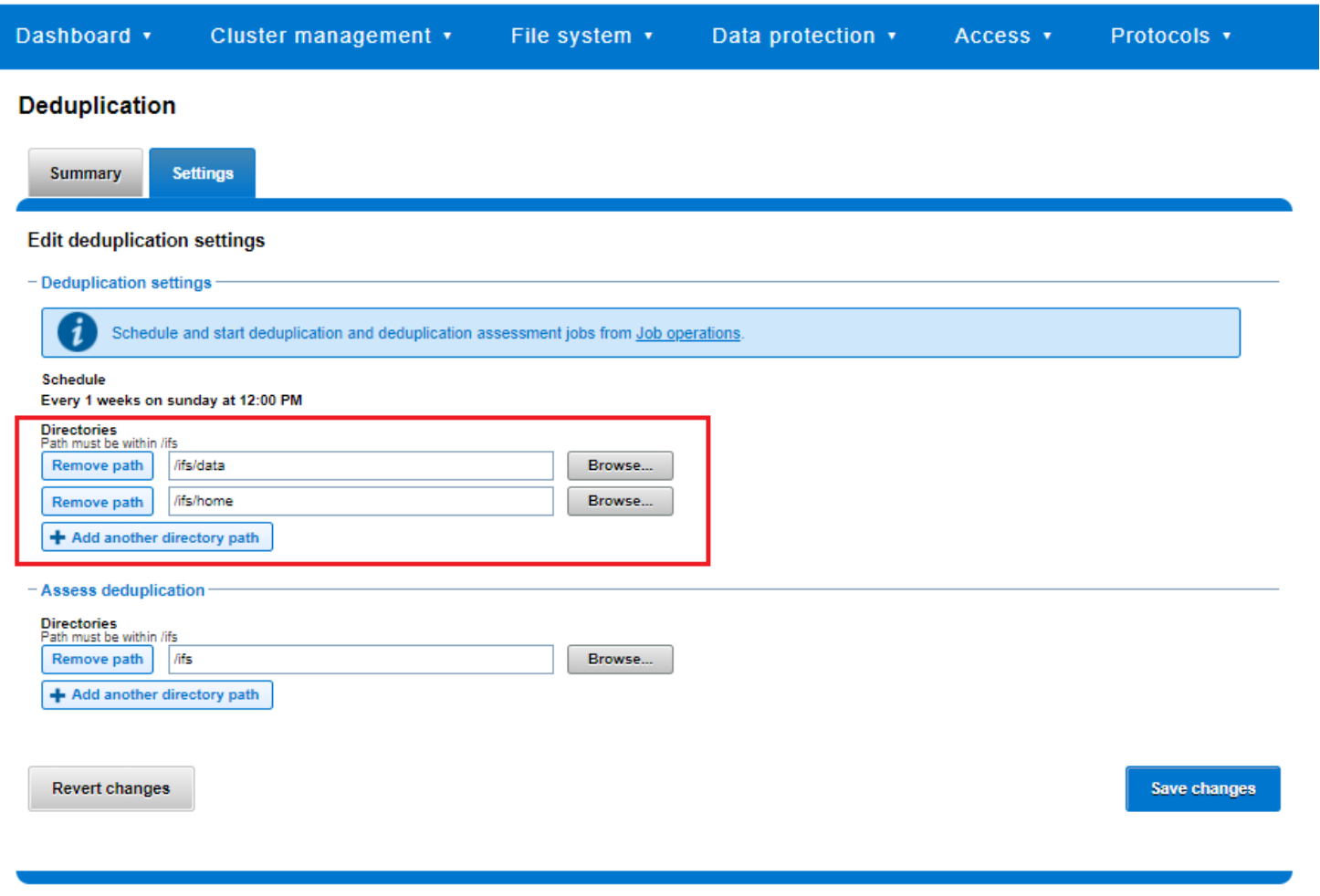
Figure 34. SmartDedupe configuration using the OneFS WebUI
Note: The permissions required to configure and modify deduplication settings are separate from those needed to run a deduplication job. For example, a user’s role must have job engine privileges to run a deduplication job. However, to configure and modify dedupe configuration settings, they must have the deduplication role privileges.
Running SmartDedupe
SmartDedupe can be run either on-demand (started manually) or according to a predefined schedule. This is configured in the cluster management ‘Job Operations’ section of the WebUI.
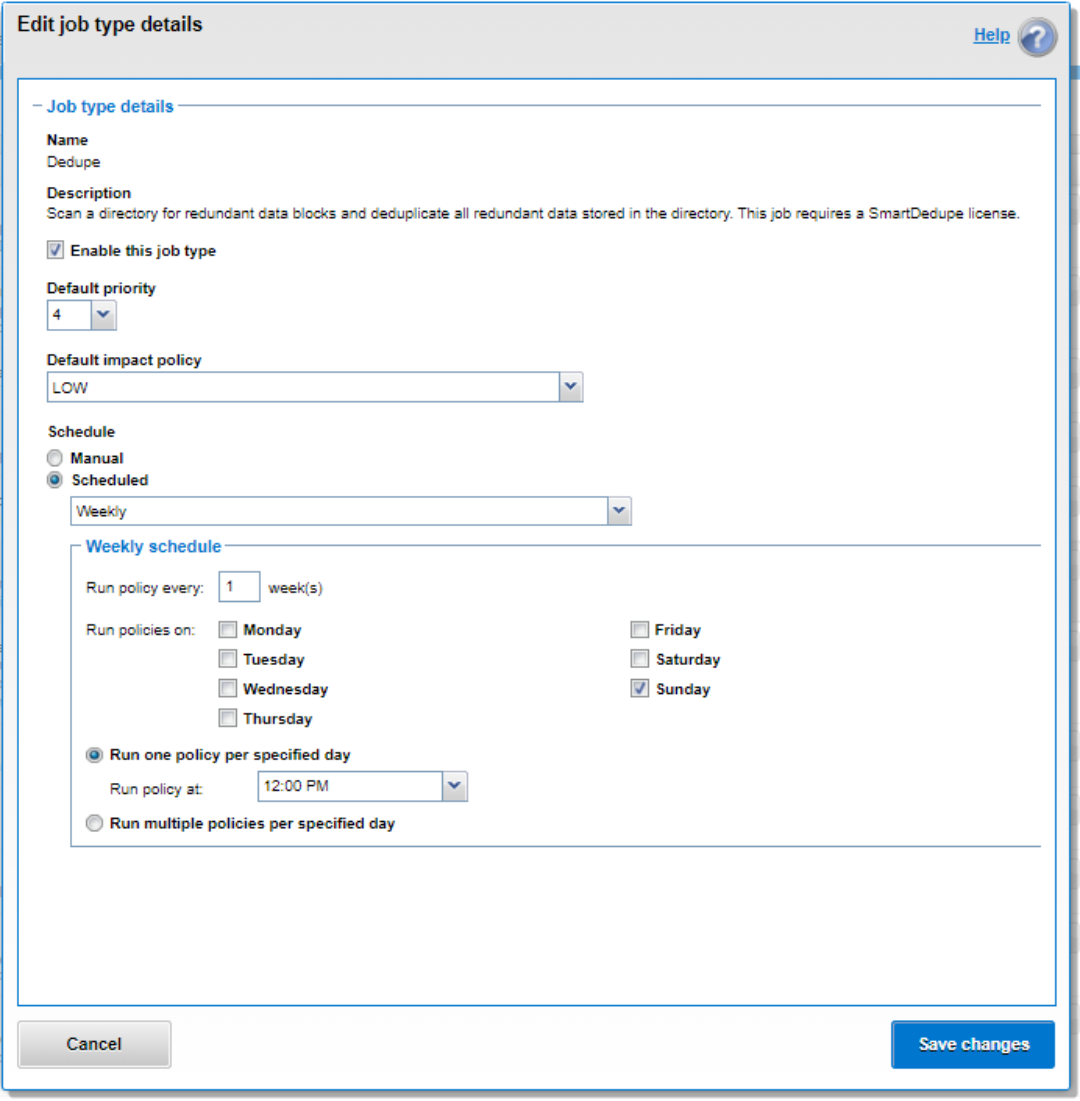
Figure 35. SmartDedupe job configuration and scheduling using the OneFS WebUI
Dell Technologies recommends scheduling and running deduplication during off-hours, when the rate of data change on the cluster is low. If clients are continually writing to files, the amount of space saved by deduplication will be minimal because the deduplicated blocks are constantly being removed from the shadow store.
For most clusters, after the initial deduplication job has completed, the recommendation is to run an incremental deduplication job once every two weeks.