
Inline data reduction in a mixed cluster
Inline data reduction in a mixed cluster
-
A mixed, or heterogeneous, cluster is one that consists of two or more different types or node. For compression, there are two main concepts in play in a mixed cluster:
- Reading compressed data to return the logical data (for client traffic, NDMP, or otherwise).
- Writing a previously compressed file to disk in uncompressed format (because the target tier does not support compression).
The former happens in L1 memory and not on-disk. As such, only F910, F900, F810, F710, F600, F210, F200, F700/7000, H5600, and A300/3000 storage pools may contain compressed data.
In general, OneFS does not allow deduplication across different disk pool policies. For inline dedupe, a deduplicated file that is moved to another tier will retain the shadow references to the shadow store on the original disk pool. While this behavior violates the rule for deduping across different disk pool policies, it is preferred to do this than rehydrate files that are moved. Further deduplication activity on that file will no longer be allowed to reference any blocks in the original shadow store. The file will need to be deduped against other files in its new node pool.
Writes to a mixed F810 cluster
Figure 10 depicts a file write in a mixed cluster environment. A client connects to an H400 node and writes a file with a path-based file pool policy that directs the file to an F810 nodepool. In this scenario, the H400 node first scans the incoming data for zero block removal and/or deduplication opportunities.
Note: Zero block elimination and inline dedupe will only be enabled on nodes that have local drives in a disk pool with the data reduce flag set.
The data reduce flag will only be set on F910, F900, F810, F710, F600, F210, F200, H700/7000, H5600, and A300/3000 disk pools and therefore zero block elimination and inline dedupe will only be performed on those platforms. When found, any zero blocks are stripped out and any matching blocks are deduplicated.
Next, the data is divided into 128KB compression chunks as usual. However, since the H400 node does not have an FPGA offload card, it instead performs compression on the chunks in software.
Note: Unlike inline dedupe, compression does not require the initiator node to be a member of a disk pool with the data reduce flag set. If the target disk pool for the write has data reduce set and the cluster has inline compression enabled, compression will be performed.
A different compression algorithm is used to help minimize the performance impact. Each compressed chunk is then FEC protected, and the H400 uses its write plan to place blocks on the participant nodes. The chunks are written in compressed form over the back-end network to the appropriate F810 nodes.
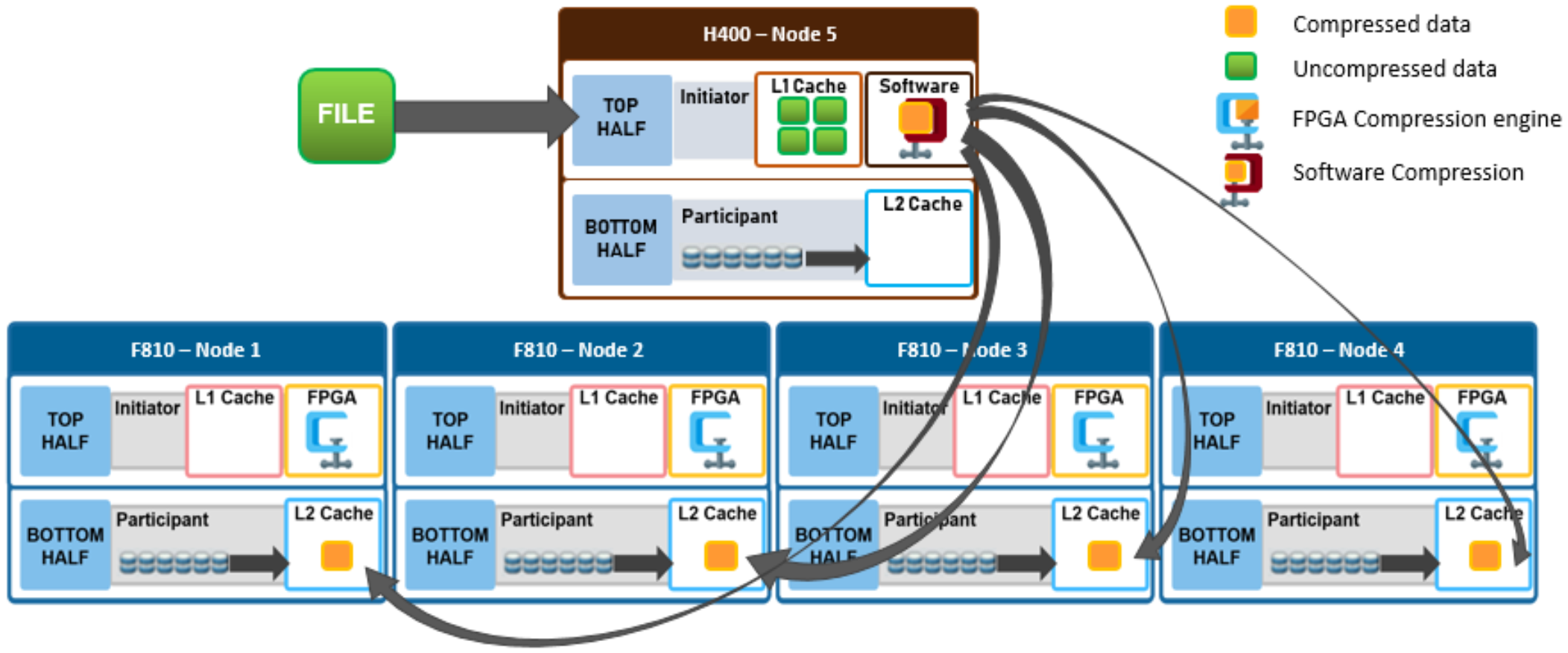
Figure 10. File write in a mixed cluster with software compression
Reading from a mixed F810 cluster
In the following mixed cluster scenario, a client connects to an H400 node and issues a read request for a compressed file housed on an F810 nodepool. The H400 retrieves all the compressed chunks from the pertinent F810 nodes over the backend network. Since the H400 has no FPGA offload card, the decompression of the chunks is performed in software. Software compression uses a different DEFLATE-compatible algorithm to help minimize the performance impact of non-offloaded decompression. Once the chunks have been decompressed, the file is then reassembled and sent over Ethernet in uncompressed form to the requesting client.
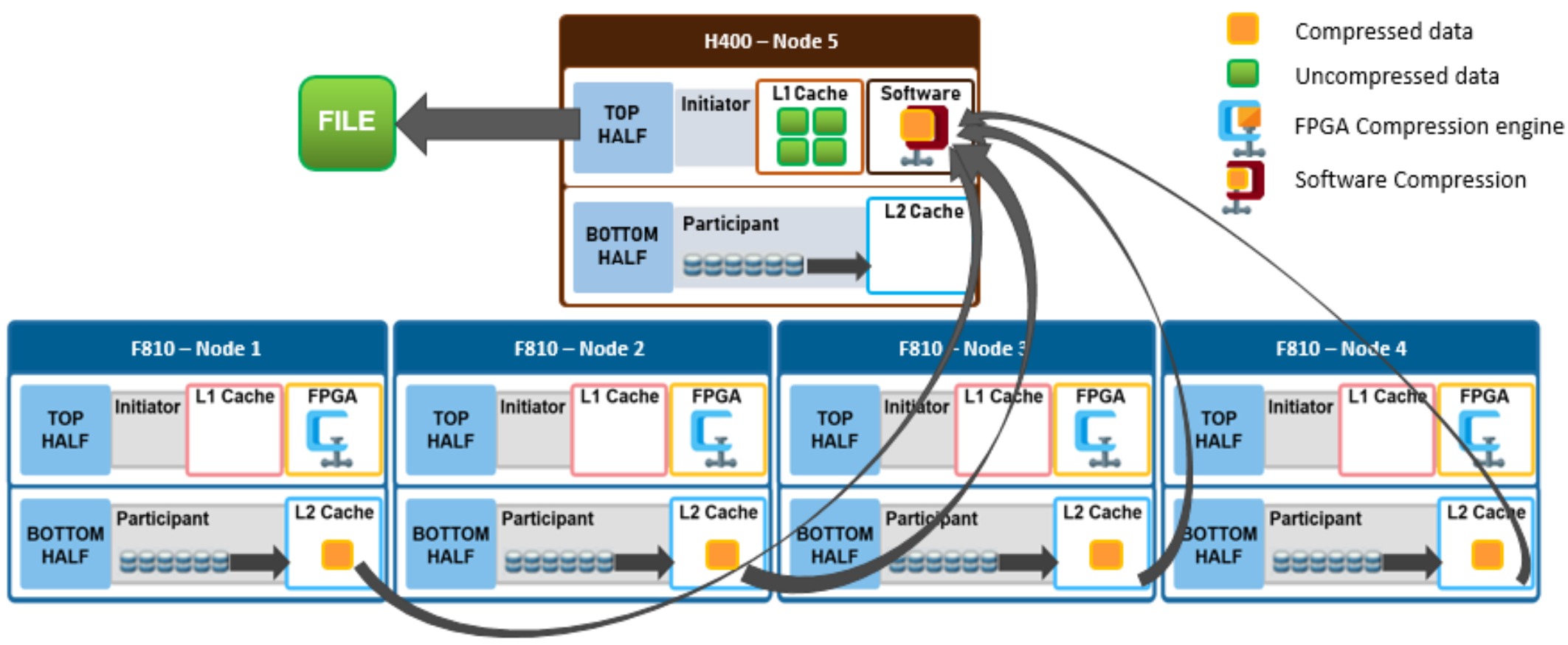
Figure 11. File read in a mixed cluster with software compression
Data reduction and tiering in a mixed cluster
Consider a mixed cluster that consists of an F810 flash performance tier and an A2000 archive tier. SmartPools is licensed, and a file pool policy is crafted to move data over three months old from the F810 flash tier to the archive tier. Files are stored in a compressed form on the F810 tier.
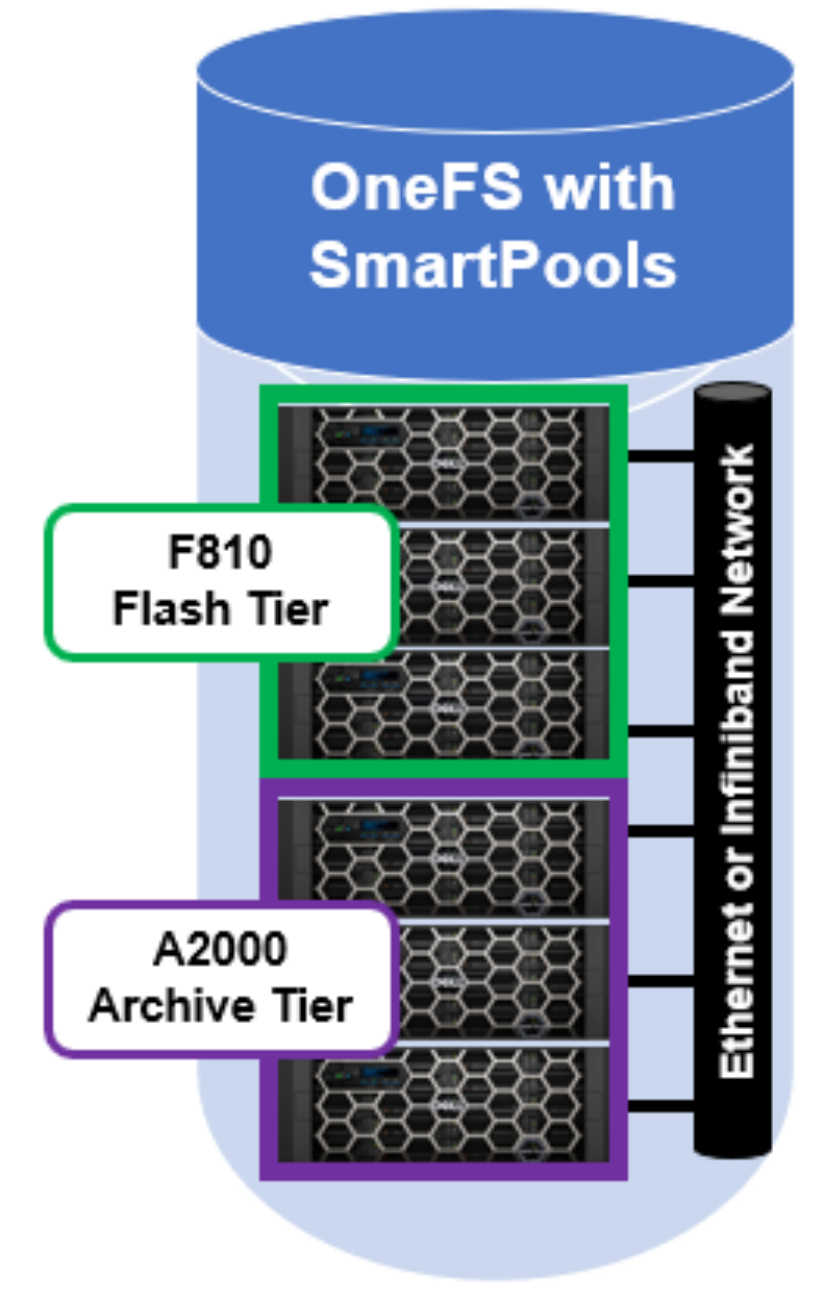
Figure 12. OneFS SmartPools running on a two tier cluster
When SmartPools runs, decompression occurs as the files targeted for down-tiering are restriped from the F810 tier to the A2000 tier inside the SmartPools job. The SmartPools job runs across all the nodes in the cluster - both F810 and A2000 - so whether hardware assisted decompression is available depends on which node(s) are running the job worker threads. Once on the A2000 tier, files will remain uncompressed.
If a file has been deduped, whether by inline or post process deduplication, the deduped state of the file will remain unchanged when tiered. This is true even if the file is moved from a disk pool that supports data reduce to a disk pool that does not.
If another file pool policy is created to up-tier files from the A2000 back up to the F810, the file chunks will be compressed when they are restriped onto the F810 nodes. Once again, all nodes in the cluster will participate in the SmartPools job.
As data moves between tiers in a mixed cluster, it must be rewritten from the old to new drives. If the target tier has a different ‘data-reduce’ setting than the source tier, data is compressed or decompressed as appropriate. The sizing of the F810 pool should be independent of whether it is participating in a mixed cluster or not. However, because up-tiering by the job-engine can run job tasks on the lower tier nodes, the achievable compression ratios may be slightly less efficient when software compression is used.
Data reduction and replication in a mixed cluster
SyncIQ is licensed on a mixed F810 and A2000 cluster and a SyncIQ policy is configured to replicate data to a target cluster. On the source cluster, replication traffic is isolated to just the A2000 nodes. When SyncIQ is run, worker threads on the A2000 nodes gather all the compressed chunks from the F810 nodes over the backend network (RBM). The A2000 nodes then perform decompression of the chunks in software. As discussed previously, software compression uses a different DEFLATE-compatible algorithm from hardware offload to help minimize the performance impact of non-offloaded decompression. Once the chunks have been decompressed, the data is then sent over Ethernet to the target cluster in uncompressed form.
Similarly, deduplicated data is always rehydrated when it exits a cluster. For a data service such as SyncIQ, data is replicated in its entirety and shadow stores and shadow links are not preserved on the target. This means that the target cluster must have sufficient space to house the full size of the replicated data set. If the target cluster happens to also be F810 hardware and inline data reduction is enabled, compression and/or deduplication will be performed as the replication data is ingested by each target node.
Compression and backup in a mixed cluster
A mixed F810 and A2000 cluster is configured for NDMP backup from the A2000 nodes. When a backup job runs, the A2000 nodes retrieve all the compressed chunks from the pertinent F810 nodes over the backend network (RBM). Since the A2000 has no FPGA offload card, the decompression of the chunks is performed in software. Once the chunks have been decompressed, each file is then reassembled and sent over Fibre Channel (2-way NDMP) or Ethernet (3-way NDMP) in uncompressed form to the backup device(s).
With NDMP, deduplicated data is rehydrated when it leaves the cluster, and shadow stores and shadow links are not preserved on the backup. The NDMP tape device or VTL will need to have sufficient space to house the full size of the data set.