
Inline data reduction and workflows
Inline data reduction and workflows
-
Below are some examples of typical space reclamation levels that have been achieved with OneFS inline data efficiency.
Note: These data efficiency space savings values are provided solely as rough guidance. Because no two data sets are alike (unless they are replicated), actual results can and will vary considerably from these examples.
Table 9. Typical workload space savings with inline data reduction
Workflow/data type
Typical efficiency ratio
Typical space savings
Home Directories / File Shares
1.3:1
25%
Engineering Source Code
1.4:1
30%
EDA Data
2:1
50%
Genomics data
2.2:1
55%
Oil and gas
1.4:1
30%
Pre-compressed data
N/A
No savings
Note: Tests of various datasets have demonstrated that data efficiency ratios can easily range from 1:1 (no reduction) to over 3:1.
Inline compression estimation with Live Optics Dossier
The Dell Live Optics Dossier utility can be used to estimate the potential benefits of OneFS’ inline data reduction on a data set. Dossier is available for Windows and has no dependency on a Dell PowerScale cluster. This makes it useful for analyzing and estimating efficiency across real data in place, without the need for copying data onto a cluster.
Dossier operates in three phases:
Table 10. Live Optics Dossier phases
Dossier phase
Description
Discovery
Users manually browse and select root folders on the local host to analyze.
Collection
Once the paths to folders have been selected, Dossier will begin walking the file system trees for the target folders. This process will likely take up to several hours for large file systems. Walking the filesystem has a similar impact to a malware/anti-virus scan in terms of the CPU, memory, and disk resources that will be used during the collection. A series of customizable options allows the user to deselect more invasive operations and governs the CPU and memory resources allocated to the Dossier collector.
Reporting
Users upload the resulting ‘.dossier’ file to create a PowerPoint report.
To obtain a Live Optics Dossier report, first download, extract, and run the Dossier collector. Local and remote UNC paths can be added for scanning. Ensure that you are authenticated to the desired UNC path before adding it to Dossier’s ‘custom paths’ configuration.
Note: The Dossier compression option only processes the first 64KB of each file to determine its compressibility. Also, the default configuration samples only 5% of the dataset, but this is configurable with a slider. Increasing this value improves the accuracy of the estimation report, albeit at the expense of extended job execution time.
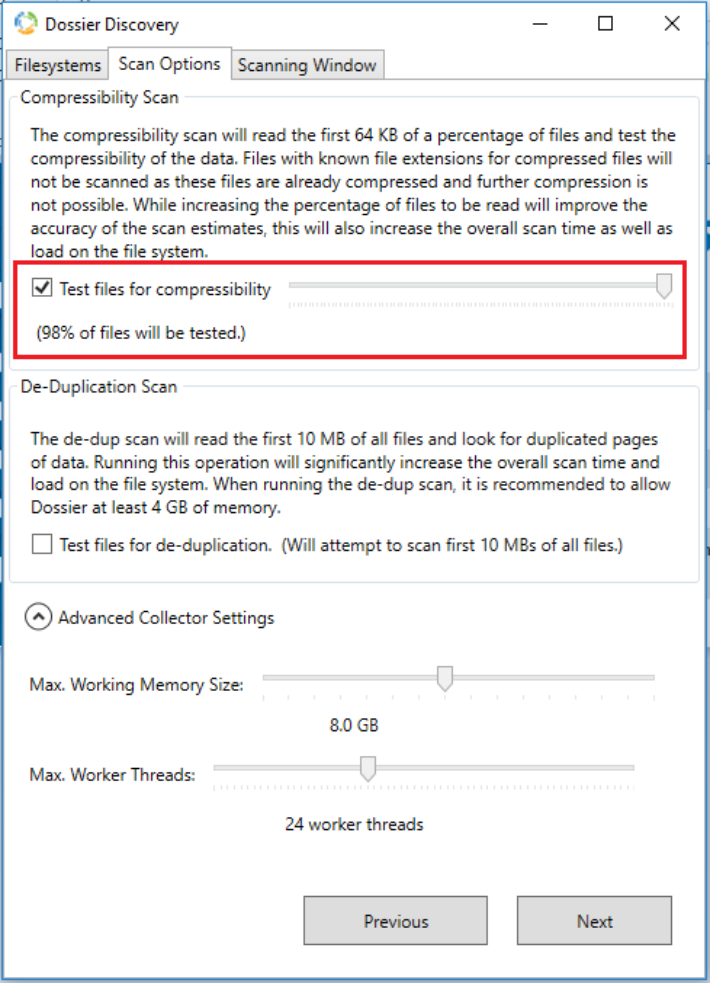
Figure 22. Dossier discovery configuration
The compressibility scan executes rapidly, with minimal CPU and memory resource consumption. It also provides thread and memory usage controls, progress reporting, and a scheduling option to allow throttling of scanning during heavy usage windows.
When the scan is complete, a ‘*.dossier’ file is generated. This file is then uploaded to the Live Optics website:
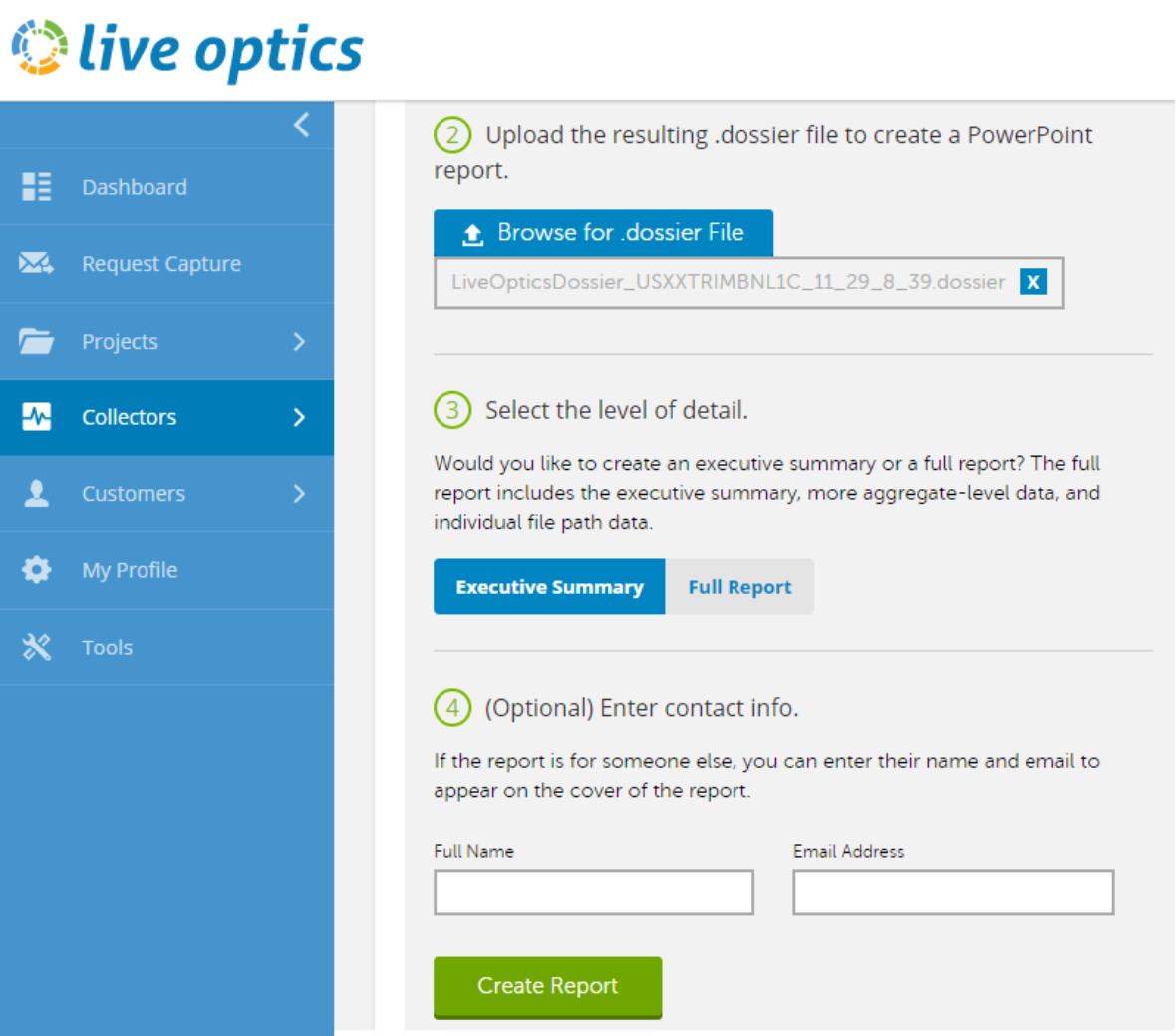
Figure 23. Live Optics Dossier data upload
Once uploaded and processed, a PowerPoint report is generated in real time and delivered by email.

Figure 24. Dossier compressibility report
Compression reports are easy to comprehend. If multiple SMB shares or paths are scanned, a summary is generated at the beginning of the report, followed by the details of each individually selected path.
Live Optics Dossier can be found at URL https://app.liveoptics.com/tools/dossier.
Documentation is at: https://support.liveoptics.com/hc/en-us/articles/229590207-Dossier-User-Guide
When running the Live Optics Dossier tool, please keep the following considerations in mind:
- Does not provide the same algorithm as the OneFS hardware inline compression.
- Dossier looks at the software compression, not the hardware compression. So actual results will generally be better than Dossier report.
- There will be some data for which dossier overestimates compression, for example with files whose first blocks are significantly more compressible than later blocks.
- Intended to be run against any SMB shares on any storage array or DAS. No NFS export support.
- Dossier tool can take a significant amount of time to run against a large data set.
- By default, it only samples a portion (first 64KB) of the data, so results can be inaccurate.
- Dossier does not attempt to compress files with certain known extensions that are uncompressible.
- Dossier assessment tool only provides the size of the uncompressed and compressed data. It does not provide performance estimates of different compression algorithms.
Inline deduplication efficiency estimation
A dry run Dedupe Assessment job is provided to help estimate the amount of space savings that will be seen on a dataset. Run against a specific directory or set of directories on a cluster, the dedupe assessment job reports a total potential space savings. The assessment job uses a separate configuration. It also does not require a product license and can be run prior to purchasing F910, F900, F810, F710, F600, F210, F200, F700/7000, H5600, and A300/3000 hardware to determine whether deduplication is appropriate for a particular data set or environment.
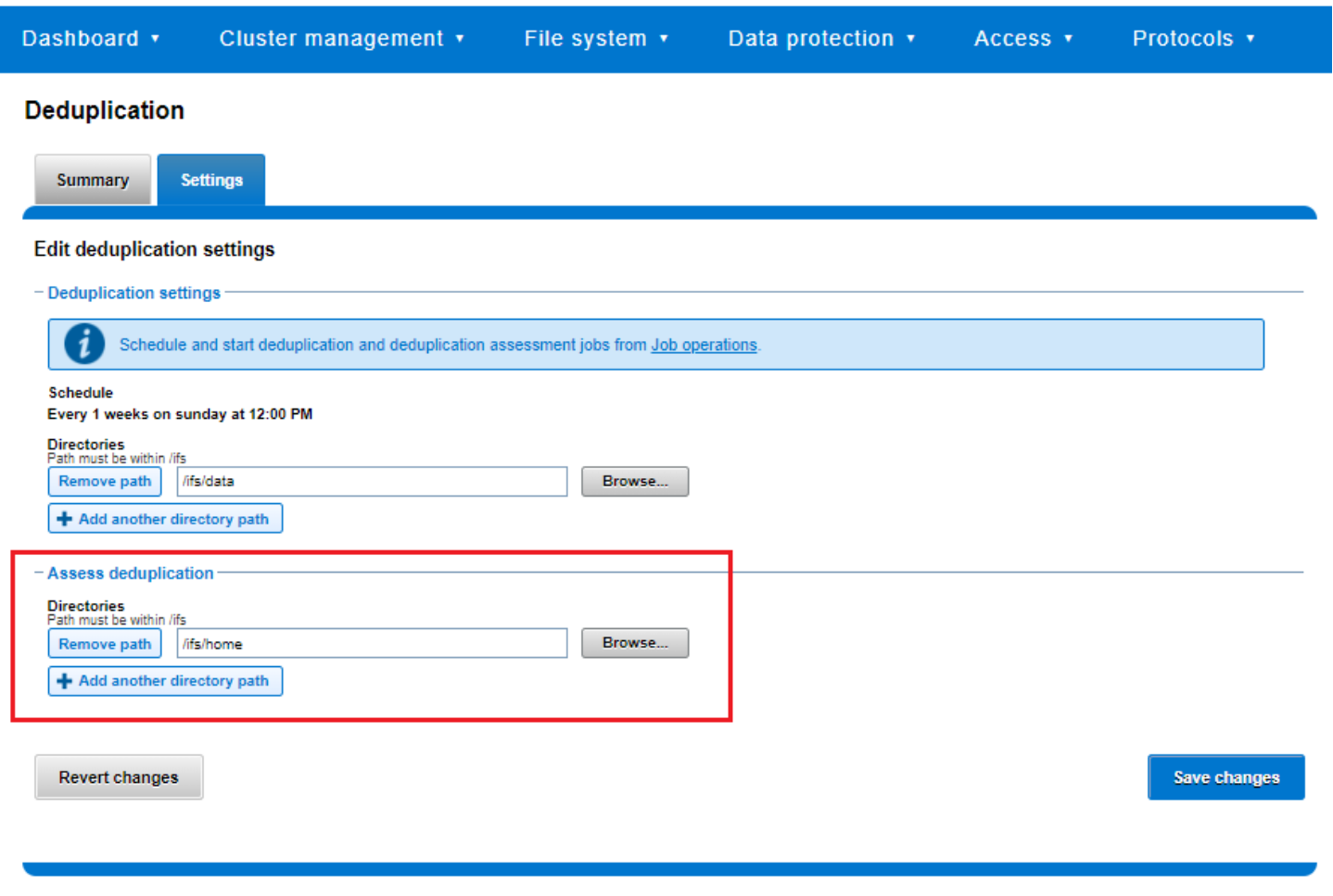
Figure 25. Deduplication assessment job configuration
The dedupe assessment job uses a separate index table to both inline dedupe and SmartDedupe. For efficiency, the assessment job also samples fewer candidate blocks and does not actually perform deduplication. Using the sampling and consolidation statistics, the job provides a report which estimates the total dedupe space savings in bytes.
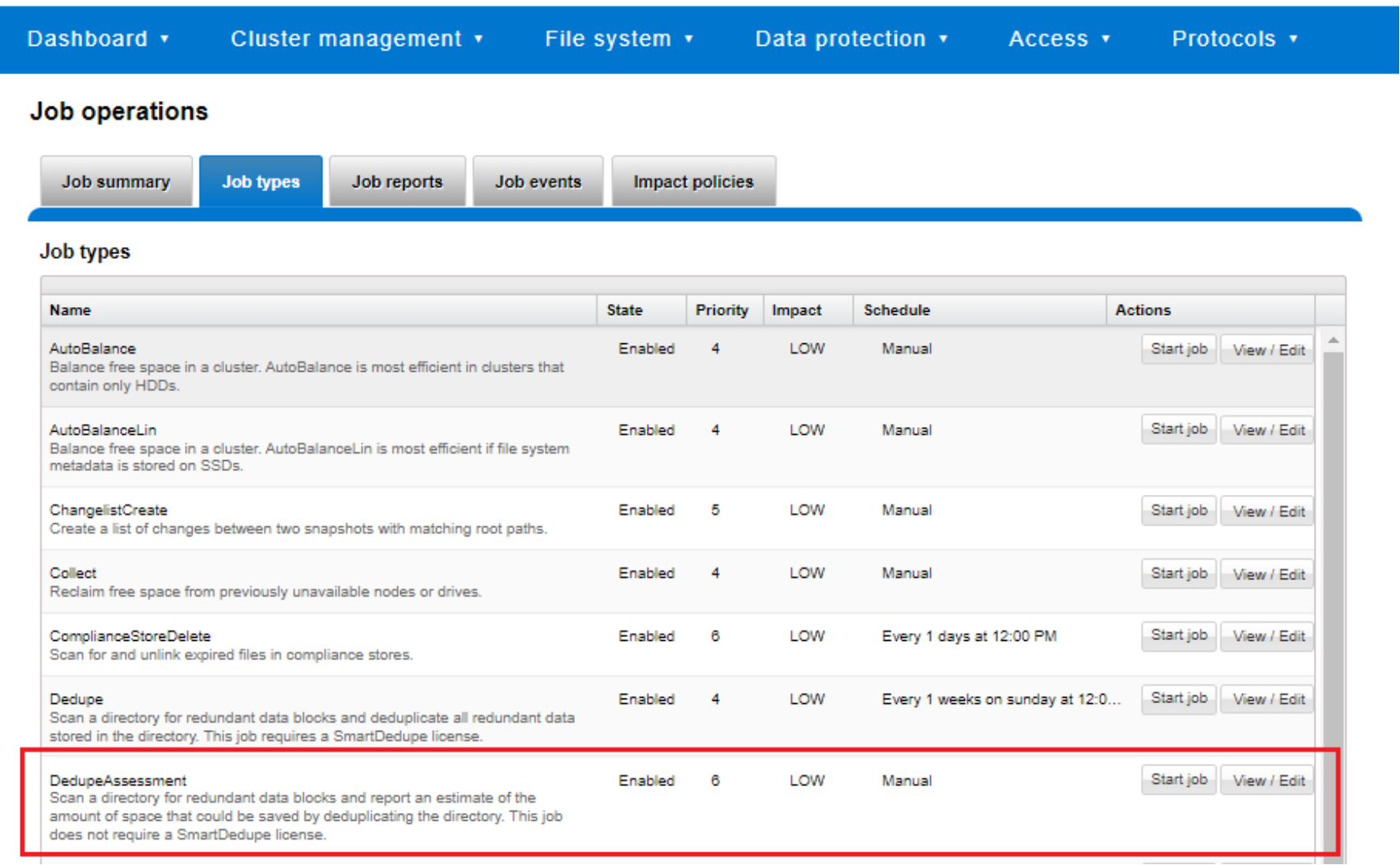
Figure 26. Dedupe assessment job control using the OneFS WebUI
The dedupe assessment job can also be run from the OneFS command line (CLI):
# isi job jobs start DedupeAssessment
Alternatively, inline deduplication can be enabled in assessment mode:
# isi dedupe inline settings modify –mode assess
When the job has finished, review the following three metrics from each node:
# sysctl efs.sfm.inline_dedupe.stats.zero_block
# sysctl efs.sfm.inline_dedupe.stats.dedupe_block
# sysctl efs.sfm.inline_dedupe.stats.write_block
The formula to calculate the estimated dedupe rate from these statistics is:
dedupe_block / write_block * 100 = dedupe%
The dedupe assessment does not differentiate the case of a fresh run from the case where a previous SmartDedupe job has already performed some sharing on the files in that directory. Dell Technologies recommends that the user should run the assessment job once on a specific directory, since it does not provide incremental differences between instances of the job.