
Deduplication job and infrastructure
Deduplication job and infrastructure
-
Deduplication is performed in parallel across the cluster by the OneFS Job Engine using a dedicated deduplication job, which distributes worker threads across all nodes. This distributed work allocation model allows SmartDedupe to scale linearly as a cluster grows and additional nodes are added.
The control, impact management, monitoring and reporting of the deduplication job is performed by the Job Engine in a similar manner to other storage management and maintenance jobs on the cluster.
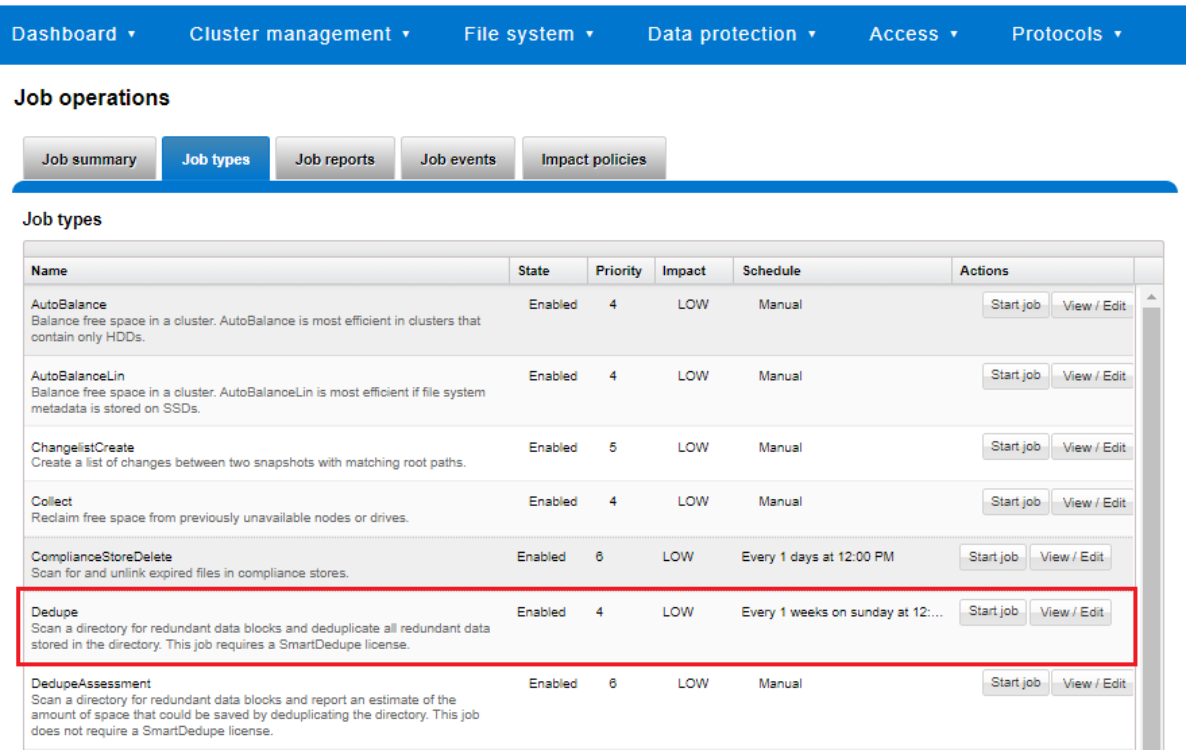
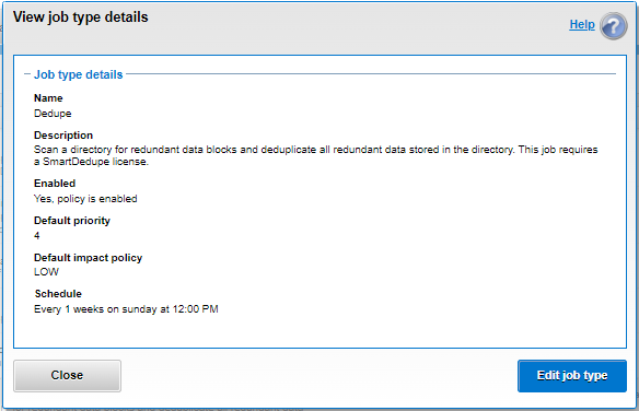
Figure 30. SmartDedupe job control using the OneFS WebUI
While deduplication can run concurrently with other cluster jobs, only a single instance of the deduplication job, albeit with multiple workers, can run at any one time. Although the overall performance impact on a cluster is relatively small, the deduplication job does consume CPU and memory resources.
The primary user facing component of SmartDedupe is the deduplication job. This job performs a file system tree-walk of the configured directory, or multiple directories, hierarchy.
Note: The deduplication job will automatically ignore (not deduplicate) the reserved cluster configuration information located under the /ifs/.ifsvar/ directory, and also any file system snapshots.
Architecturally, the duplication job, and supporting dedupe infrastructure, consist of the following four phases:
- Sampling
- Duplicate Detection
- Block Sharing
- Index Update
These four phases are described in more detail below.
Because the SmartDedupe job is typically long running, each of the phases is executed for a set time period, performing as much work as possible before yielding to the next phase. When all four phases have been run, the job returns to the first phase and continues from where it left off. Incremental dedupe job progress tracking is available from the OneFS Job Engine reporting infrastructure.
Sampling phase
In the sampling phase, SmartDedupe performs a tree-walk of the configured data set in order to collect deduplication candidates for each file.
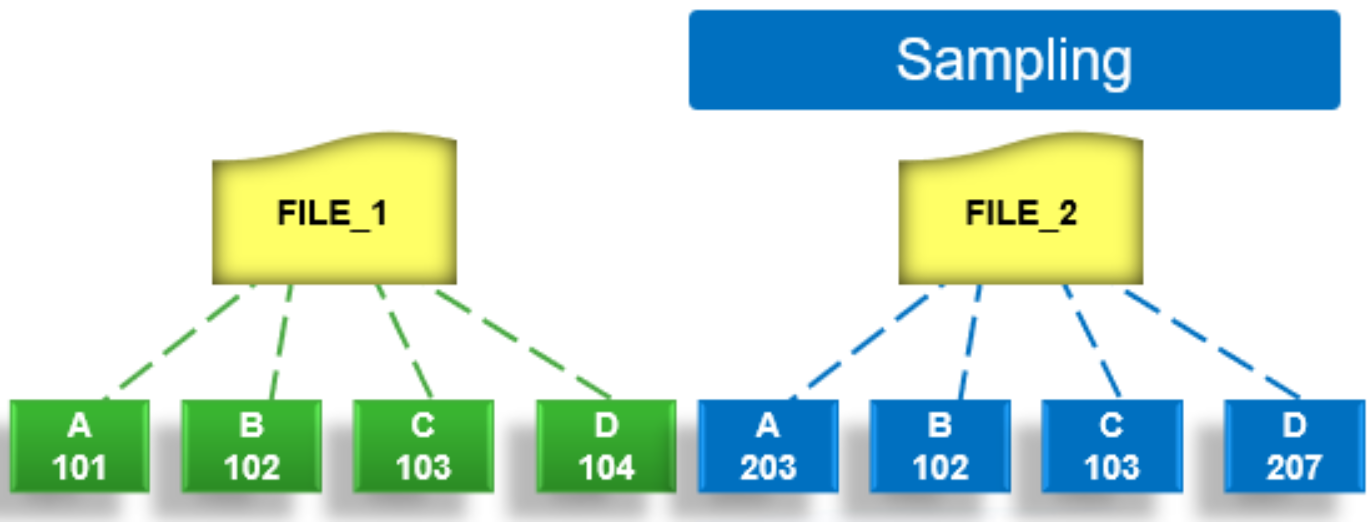
Figure 31. SmartDedupe job sampling phase
The rationale is that a large percentage of shared blocks can be detected with only a smaller sample of data blocks represented in the index table. By default, the sampling phase selects one block from every sixteen blocks of a file as a deduplication candidate. For each candidate, a key/value pair consisting of the block’s fingerprint (SHA-1 hash) and file system location (logical inode number and byte offset) is inserted into the index. Once a file has been sampled, the file is flagged and will not be re-scanned until it has been modified. This drastically improves the performance of subsequent deduplication jobs.
Duplicate detection phase
During the duplicate, or commonality, detection phase, the dedupe job scans the index table for fingerprints (or hashes) that match those of the candidate blocks.
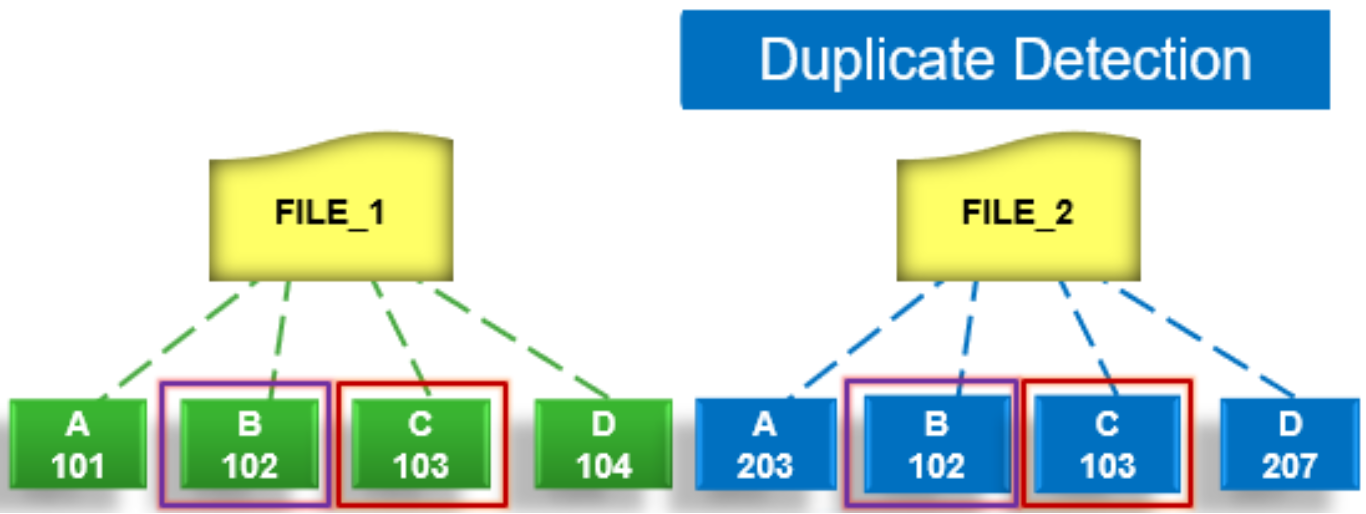
Figure 32. SmartDedupe job duplicate detection phase
If the index entries of two files match, a request entry is generated. In order to improve deduplication efficiency, a request entry also contains pre and post limit information. This information contains the number of blocks in front of and behind the matching block which the block sharing phase should search for a larger matching data chunk, and typically aligns to a OneFS protection group’s boundaries.
Block sharing phase
During the block sharing phase, the deduplication job calls into the shadow store library and dedupe infrastructure to perform the sharing of the blocks.
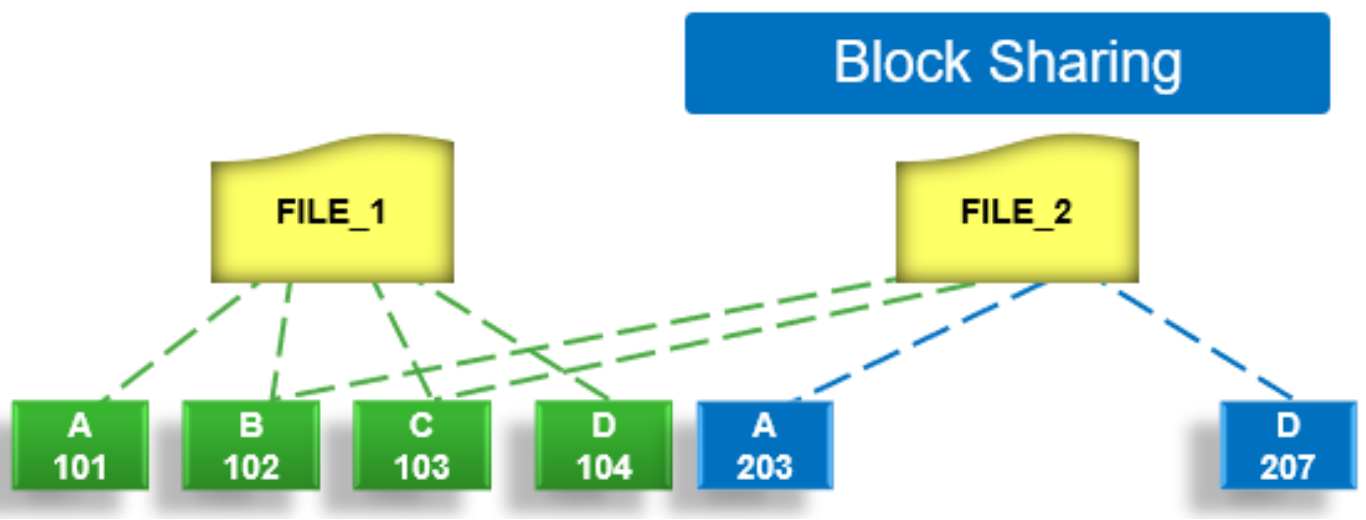
Figure 33. SmartDedupe job block sharing phase
Multiple request entries are consolidated into a single sharing request which is processed by the block sharing phase and ultimately results in the deduplication of the common blocks. The file system searches for contiguous matching regions before and after the matching blocks in the sharing request; if any such regions are found, they too will be shared. Blocks are shared by writing the matching data to a common shadow store and creating references from the original files to this shadow store.
Index update phase
This phase populates the index table with the sampled and matching block information gathered during the previous three phases. After a file has been scanned by the dedupe job, OneFS may not find any matching blocks in other files on the cluster. Once a number of other files have been scanned, if a file continues to not share any blocks with other files on the cluster, OneFS will remove the index entries for that file. This helps prevent OneFS from wasting cluster resources searching for unlikely matches. SmartDedupe scans each file in the specified data set once, after which the file is marked, preventing subsequent dedupe jobs from rescanning the file until it has been modified.