
NFS behavior and configuration consideration
NFS behavior and configuration consideration
-
This section explains how the PowerScale OneFS upgrade process can impact the NFS workloads including both NFSv3 and NFSv4.
Note: NFS version 2 is not supported in OneFS 7.2.0 and above. Due to this reason, it is not in this white paper.
Before explaining how the PowerScale OneFS NDU process can impact the NFS workloads, it is important to understand the following three points:
- PowerScale dynamic IP pool for NFS workloads
- NFS recovery or retry mechanism
- Performance impact
Best practices are in the conclusion of this section.
PowerScale dynamic IP pool for NFS workloads
NFSv3 with dynamic IP pool
Dynamic IP pools assign out all the IP addresses within a given range to all the available NICs across the entire PowerScale cluster. Dynamic IP addresses can move from one NIC to another, when a node goes to an unhealthy state. This ensures that dynamic IP addresses are always available during failover and failback. For a stateless protocol like NFSv3, the best practice is to use a dynamic IP pool for business continuity.
During the OneFS NDU process, if the rolling upgrade is selected, it will individually upgrade and restart each node in the PowerScale cluster so that only one node is offline at a time. Once a node is offline, the IP address of this node will move to one of the remaining available nodes by using the dynamic IP pool.
As shown in 0, in a 4 nodes PowerScale cluster, once node 1 is offline, both of the dynamic IPs on node 1 will move to the remaining nodes to ensure the business continuity. If the NFS clients use 192.168.200.241 as the NFS server IP to mount NFS exports, during the node 1 offline, it is actually accessing node 2 in the PowerScale cluster and this is transparent to the NFS clients.
Important: This will introduce a noticeable pause of the NFS workload. Usually, it only takes less than 20 seconds, which is the amount of time that it usually takes the network ARP cache to flush. This NFS workload pause only happens in the clients which connect to the PowerScale node being rebooted. The other clients will not be affected. In this period of time, you will see the throughput between the NFS client and the NFS server is 0. And after that, it will restore automatically.
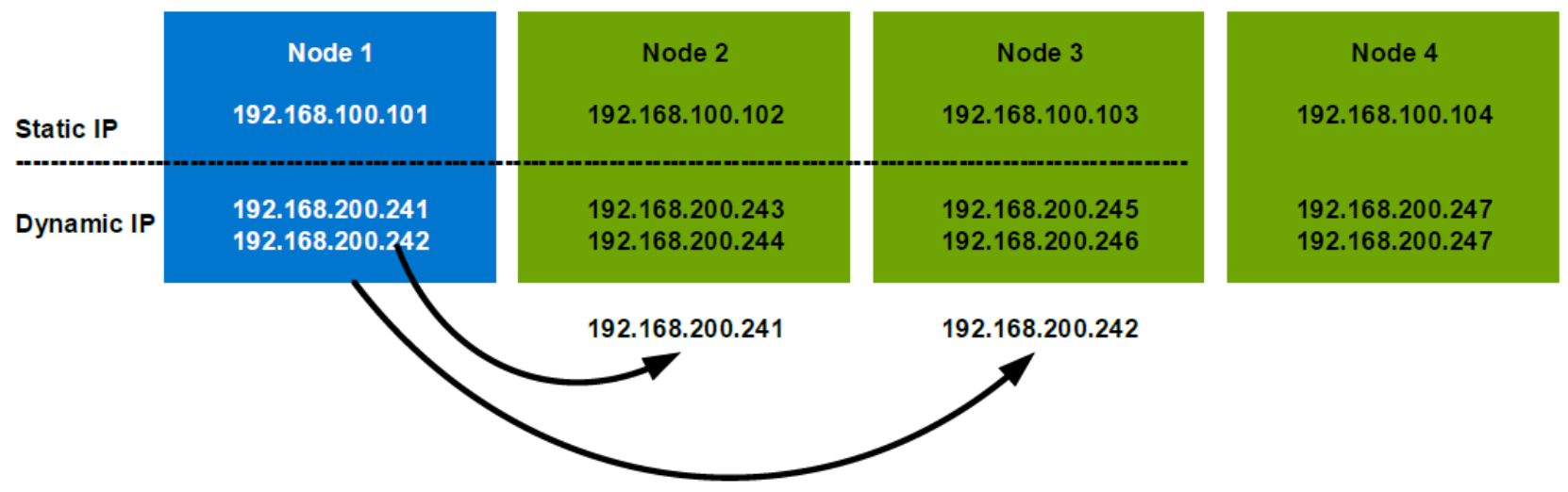
Figure 6. Dynamic IP example
Figure 7 is an example of how it works in the rolling upgrade: NFS is mounted at 192.168.200.241. After initiating the OneFS rolling upgrade, node 1 reboots first and causes the NFS mount IP to move from Node 1 to Node 2, which will introduce a noticeable pause of NFS workload. Then, Node 2 starts to upgrade and follows a reboot. This will introduce another IP reallocation from Node 2 to Node 3 and a second short pause. In this case, during the rolling upgrade process, there will be 4 short pauses in total. This is for a 4 nodes PowerScale cluster. If it is a large cluster, the interruptions will be much more frequent.
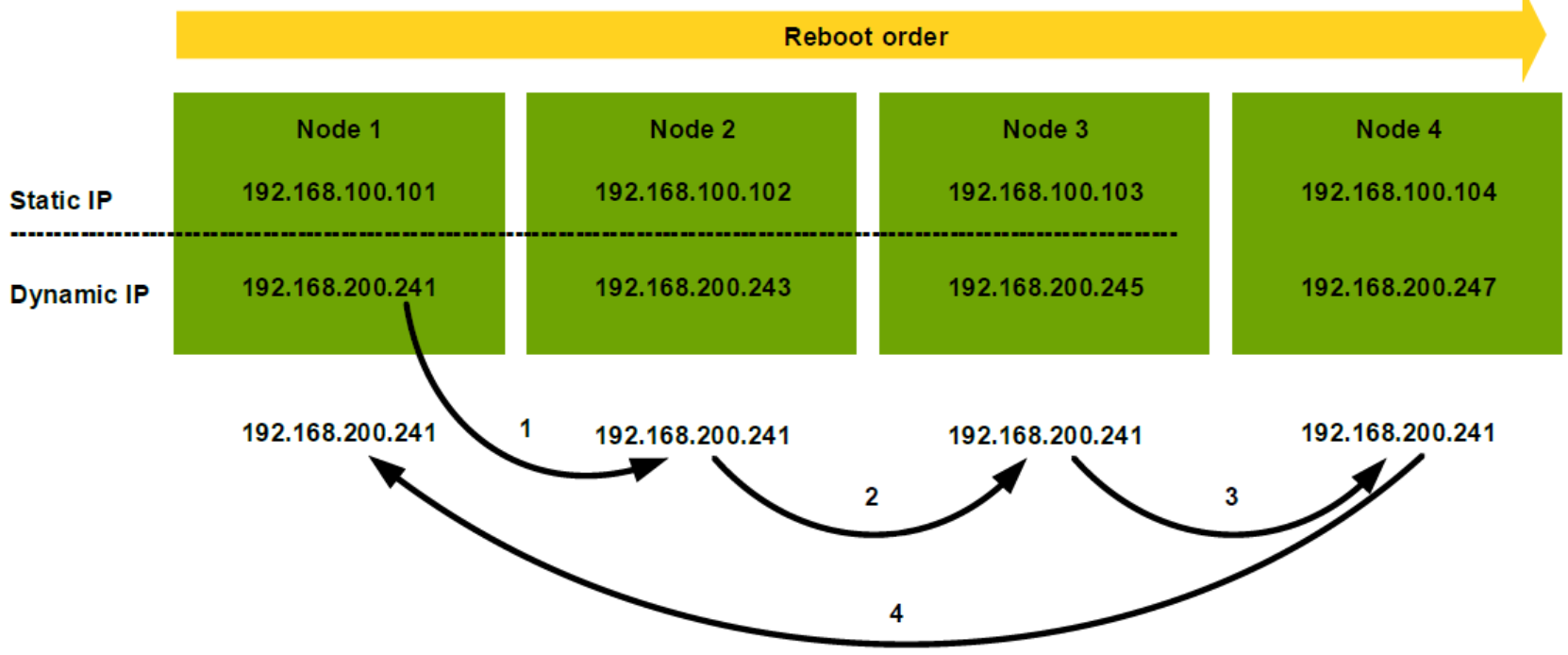
Figure 7. Worst case of OneFS rolling upgrade
The above example is the worst case which tends to be unlikely to happen. This is because from OneFS 8.0, when performing NFS failover using SmartConnect dynamic IP, we tend to favor nodes that are already upgraded. For example, on a three-node PowerScale cluster with 8 IPs in a dynamic pool, if PowerScale node 3 has been upgraded and node 1 and node 2 have not, OneFS will rebalance IPs so that node 3 will have 4 IPs and at the same time node 1 and node 2 only have two IPs each. This awareness reduces the overall rolling upgrade process to the overall services.
On the other hand, we have multiple dynamic IPs per pool to spread the load across multiple nodes to mitigate the impact. Determining the number of IP addresses within a dynamic allocation pool varies depends on the PowerScale node count, the estimated number of clients that would be in a failover event and so on. For detailed best practices, refer to PowerScale Network Design Considerations.
NFSv4 with dynamic IP pool
NFSv4 is a stateful protocol and in this case, it expects the NFS server to maintain session state information. This means each PowerScale node runs its own NFS daemon and the session information is unique per node. For this reason, we usually recommended using PowerScale static IP pool for NFSv4. However, beginning in PowerScale OneFS 8.0, the NFSv4 session state information is kept in sync across multiple nodes. In the OneFS 8.0 and later, it is recommended to use a dynamic IP pool for NFSv4 connections.
In the case where a static IP pool is applied for NFSv4 workloads, there will be a much longer time during which NFS clients will not receive any response from a PowerScale node. This is because static IPs cannot move among the interfaces. Clients that cannot communicate to the specific PowerScale node may receive an “NFS server not responding” message until the PowerScale node comes back online. In some cases, the NFS client may timeout.
NFS recovery/retry mechanism
The behavior of NFS recovery is determined by several NFS mount options as below. These mount options apply to both NFSv3 and NFSv4.
timeo=n
The timeo is measured in deciseconds (tenths of a second) and it means how long the NFS client waits for a response before it retries an NFS request. In this period of time, NFS clients will see an “NFS server not responding” response.
For NFS over TCP the default timeo value is 600 (60 seconds). As shown in Figure 8, the NFS client performs linear backoff algorithm for timeout value, which means after each retransmission the timeout is increased by timeo up to the maximum of 600 seconds. Figure 8 shows an example where timeo equals 600.
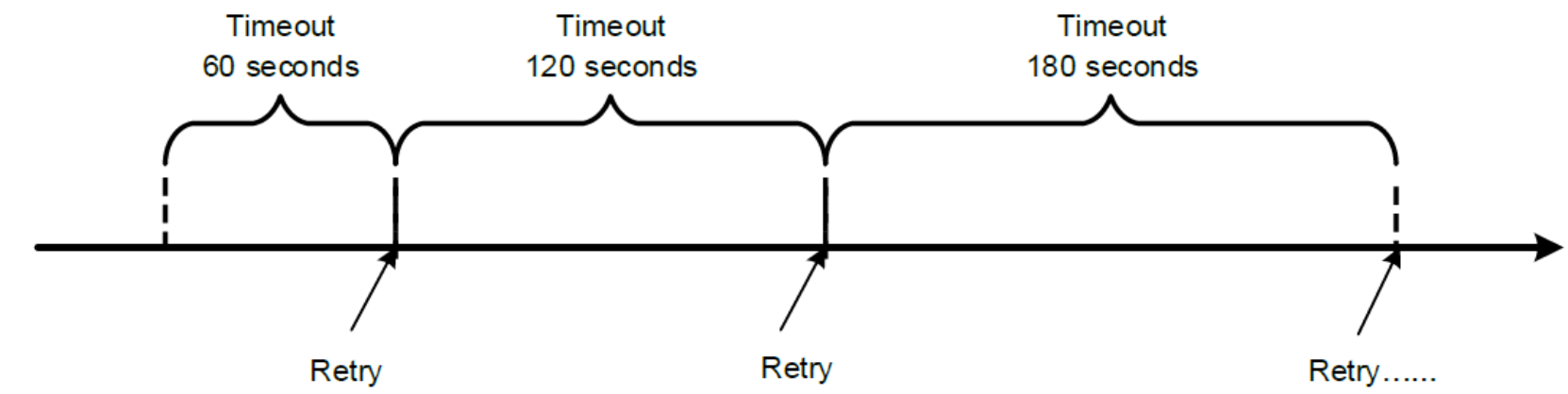
Figure 8. An example of an NFS timeout linear backoff algorithm (timeo=600)
retrans=n
The retrans is the number of times the NFS client retries a request before it attempts further recovery action. If the retrans option is not specified, the NFS client tries each request three times. Figure 9 shows an example of retrains equal to 2 and timeo equaling to 600.
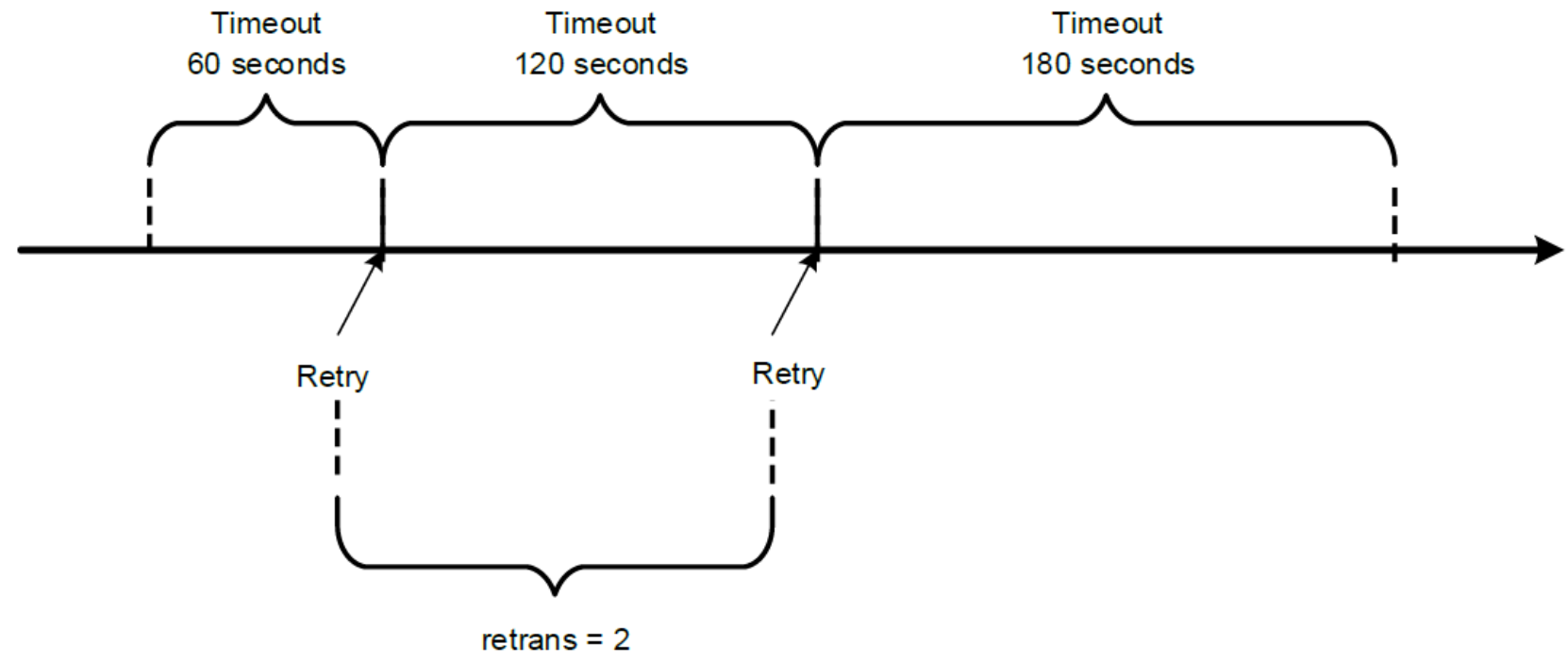
Figure 9. An example of NFS retrans = 2
Soft/hard mount
The soft or hard mount option determines the recovery behavior of the NFS client after an NFS request times out as described in Table 3. For most clients, Dell Technologies recommends using the hard mount option and avoid soft mount.
Table 3. Soft and hard mount options
Mount type
Description
Hard (or not specify)
After an NFS request timeout, it will attempt to retry and NFS requests are retried indefinitely.
Soft
Once an NFS request timeout, it will attempt to retry. But after retrans retransmissions have been sent, the NFS client fails an NFS request, causing the NFS client to return an error to the calling application. For example if retrans equals 2, the NFS client will return an error after two attempts to retry. This example is also shown in Figure 10.
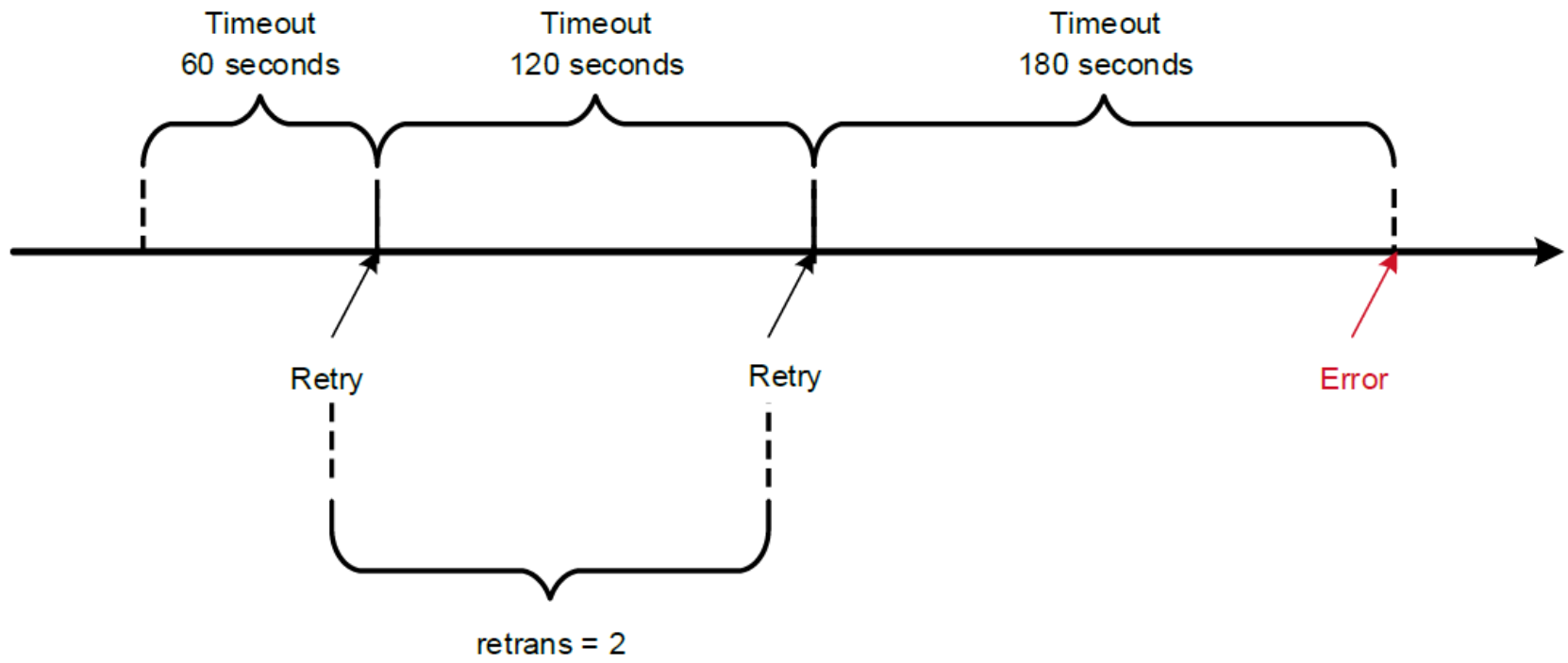
Figure 10. An example of soft mount failure (retrains = 2)
It is obvious to see how the client behaves during the noticeable pause in a rolling upgrade is determined by the above three mount options. The detailed explanation is as the following:
- In the case of a hard mount, because the NFS client request will attempt to retry indefinitely, there will be no error message in the NFS layer during the noticeable pause in a rolling upgrade process.
Note: Although in the NFS layer, there will be no errors and the NFS client will try to retry indefinitely for hard mount, some applications may still encounter errors and this depends on how the application is implemented. Consult your application vendors for this situation.
- In the case of a soft mount, if the noticeable pause ends in the green area as shown in 0, there will be no error message in the NFS client application. If the noticeable pause ends beyond the green area as shown in Figure 12, the NFS client will send an error message during the OneFS rolling upgrade process. Usually, it recommends using hard mount instead of using soft mount
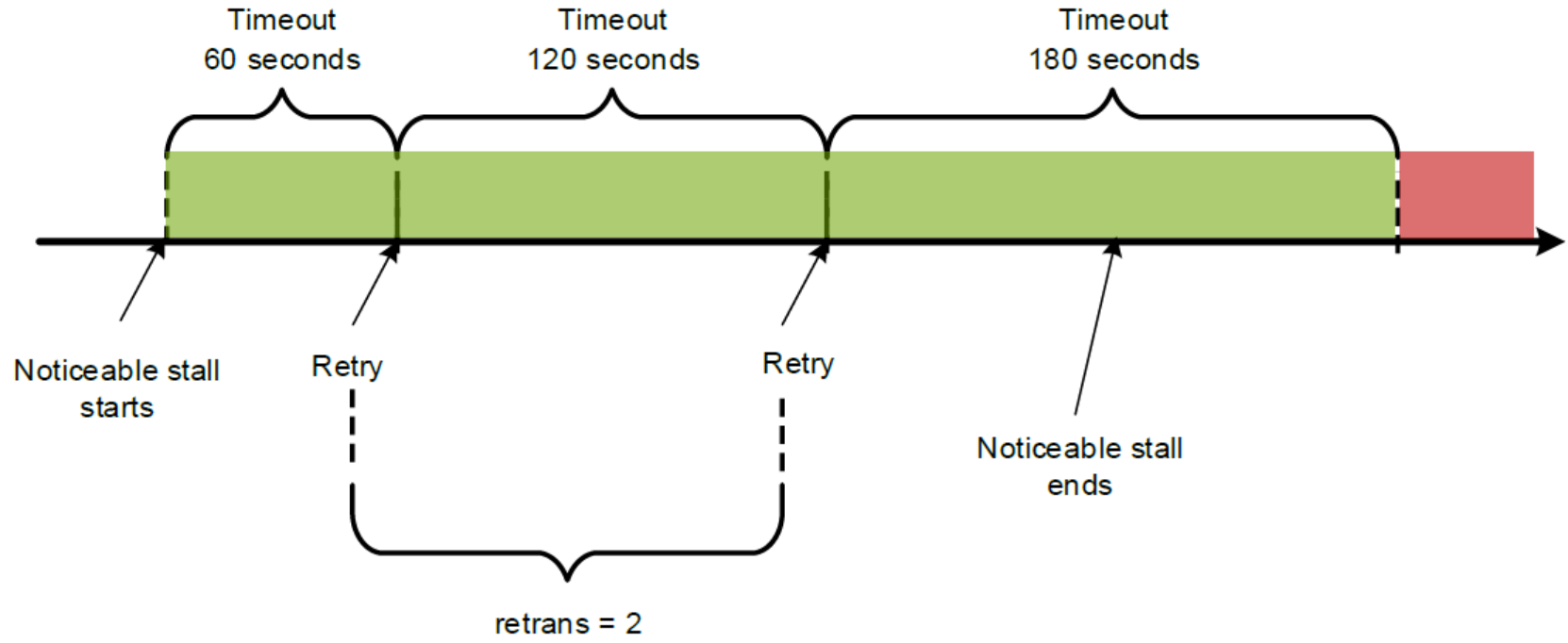
Figure 11. The noticeable pause within the timeout range
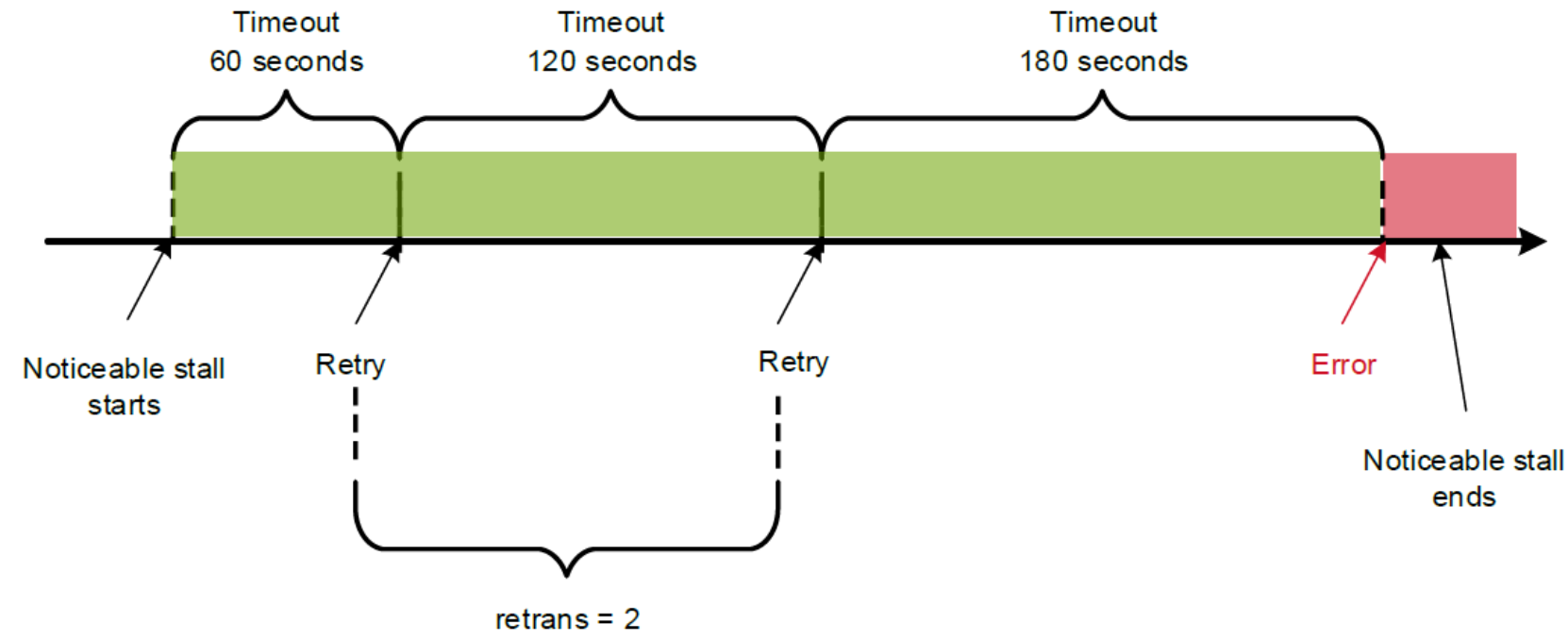
Figure 12. The noticeable pause beyond the timeout range
Performance impact
Dell Technologies recommends all non-disruptive upgrades be performed at a time of low I/O. This is identified as the target maintenance window. If you perform the OneFS rolling upgrade during the maintenance window, you will see minimal performance impact during the overall process.
In case OneFS rolling upgrade is initiated at a time when the cluster is under heavy workload, you will see limited performance impact due to the PowerScale node reboots, since you now have (n-1) PowerScale nodes in the cluster to serve the workload during the reboot time. Performance impacts will be lessened as PowerScale cluster size increases.
NDU best practices concluded for NFSv3/v4
With the knowledge of the section PowerScale dynamic IP pool for NFS workloads, and the section NFS recovery/retry mechanism, we can conclude the following NDU best practices for NFSv3/v4:
- Use PowerScale dynamic IP pool for NFSv3.
- Use PowerScale dynamic IP pool for NFSv4, if the OneFS version is 8.0 and above
- Leverage SmartConnect multiple dynamic IPs and SSIP to spread the load across multiple nodes to mitigate the impact of the OneFS rolling upgrade process.
- Use the NFS hard mount option and the default NFS mount option is good enough for NDU consideration.