
Storage pod
Storage pod
-
An alternative approach for HPC and high-IOPS workloads is the Storage Pod architecture. Here, design considerations for new clusters revolve around multiple smaller homogenous clusters, with each cluster itself acting as a fault domain – in contrast to the monolithic extra-large cluster described above.
Pod clusters can easily be tailored to the individual demands of workloads as necessary. Optimizations per storage pod can include size of SSDs, drive protection levels, data services, and availability SLAs. In addition, smaller clusters greatly reduce the frequency and impact of drive failures and their subsequent rebuild operations. This, coupled with the ability to schedule maintenance, manage smaller datasets, and simplify DR processes more easily, can all help alleviate the administrative overhead for a cluster.
A Pod infrastructure can be architected per application, workload, similar I/O type (streaming reads), project, tenant (business unit), or availability SLA. This pod approach has been successfully adopted by a number of large customers in industries such as semiconductor, automotive, life sciences, and others with demanding performance workloads.
This Pod architecture model can also fit well for global organizations, where a cluster is deployed per region or availability zone. An extra-large cluster architecture can be usefully deployed in conjunction with Pod clusters to act as a centralized disaster recovery target, using a hub and spoke replication topology. Since the centralized DR cluster will be handling only predictable levels of replication traffic, it can be architected using capacity-biased nodes.
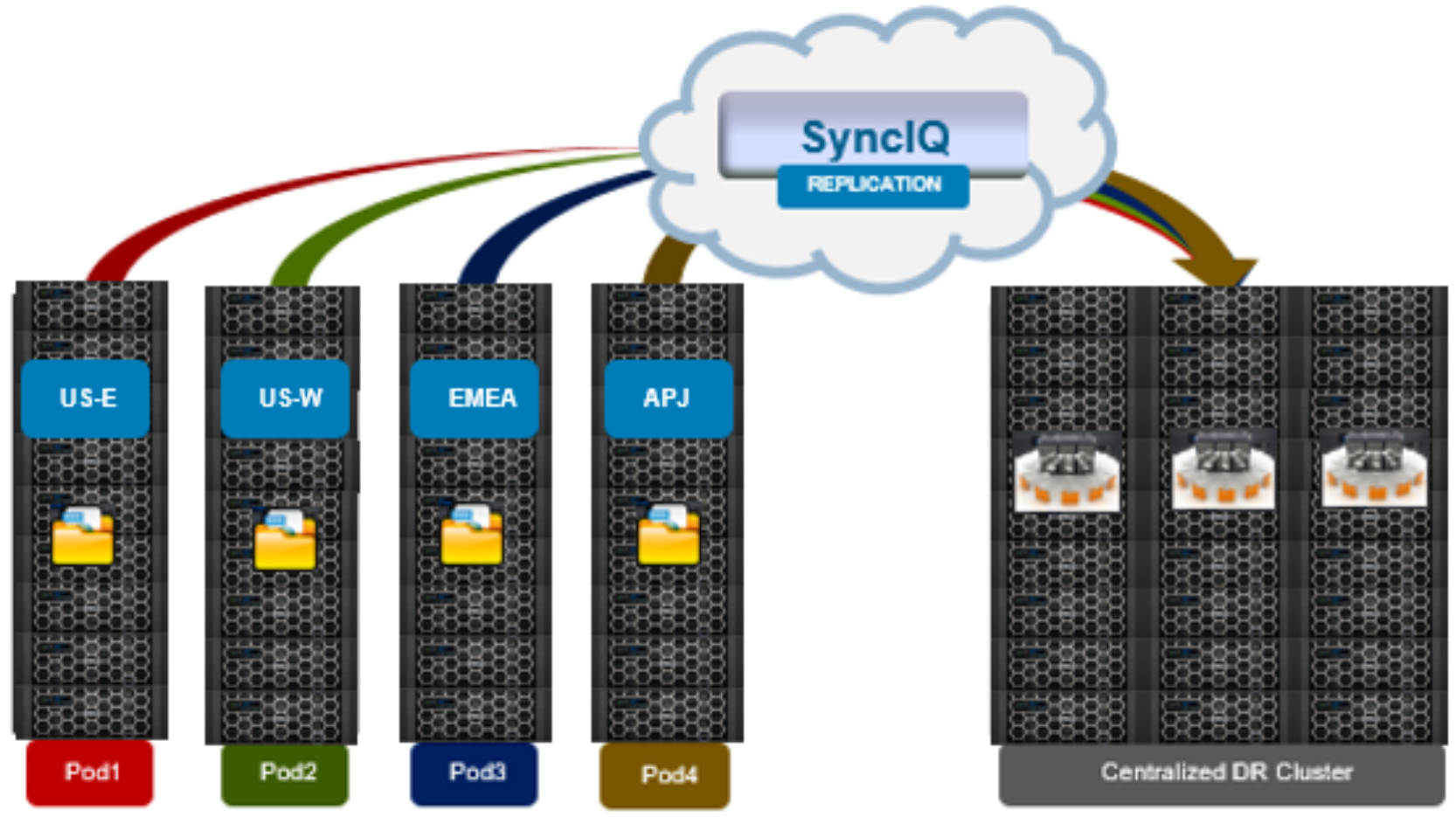
Figure 2. Pod architecture
Before embarking upon either a data lake or Pod architectural design, it is important to undertake a thorough analysis of the workloads and applications that the cluster(s) will be supporting.