
Single large cluster
Single large cluster
-
A single large, or extra-large, cluster is often deployed to support a wide variety of workloads and their requisite protocols and performance profiles – from primary to archive - within a single, scalable volume and namespace. This approach, referred to as a ‘data lake architecture’, usually involves more than one style of node.
OneFS can support up to fifty separate tenants in a single cluster, each with their own subnet, routing, DNS, and security infrastructure. OneFS provides the ability to separate data layout with SmartPools, export and share level isolation, granular authentication and access control with Access Zones, and network partitioning with SmartConnect, subnets, and VLANs.
Furthermore, analytics workloads can easily be run against the datasets in a single location and without the need for additional storage and data replication and migration.
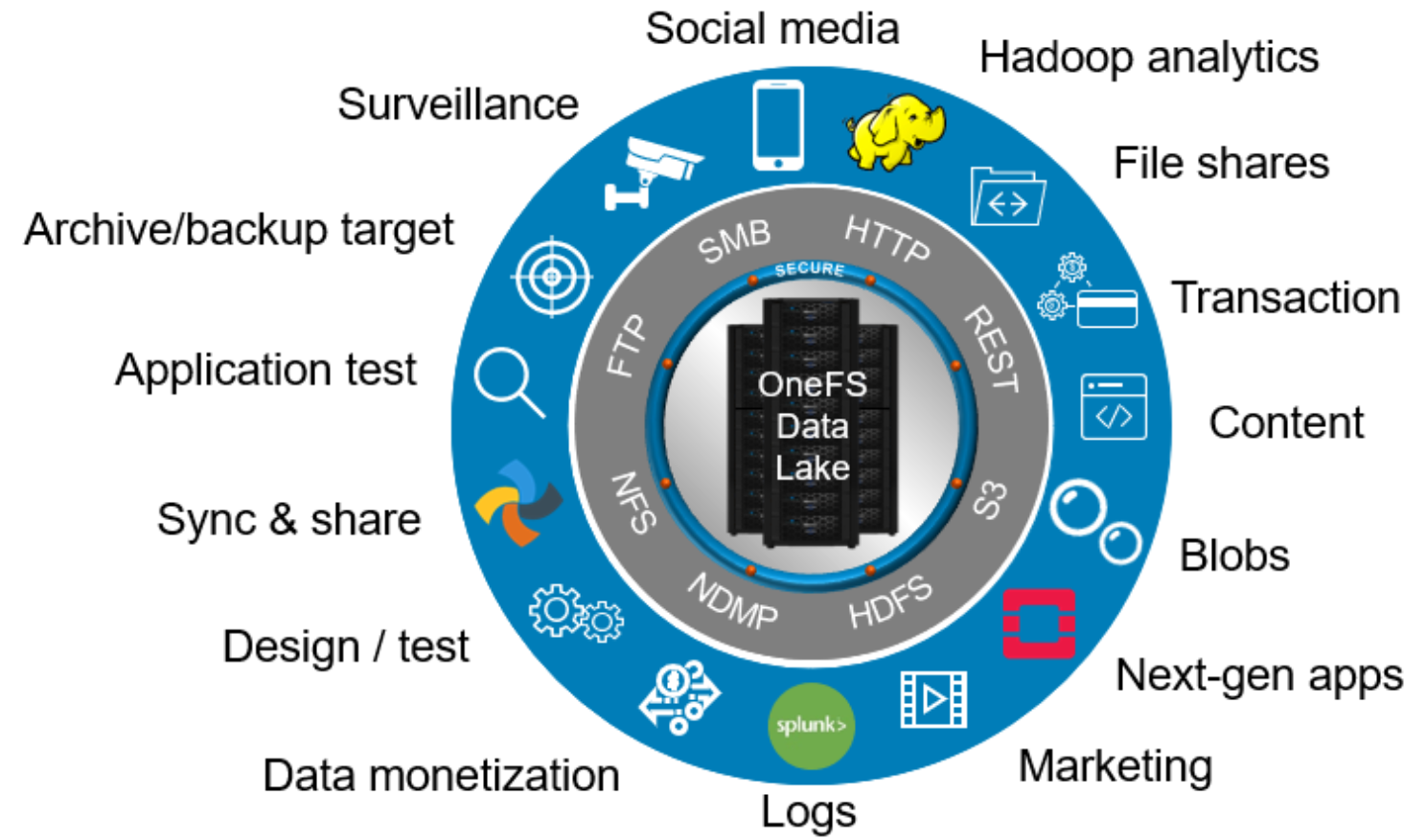
Figure 1. OneFS data lake
For the right combination of workloads, the data lake architecture has many favorable efficiencies of scale and centralized administration.
Another use case for large clusters is in a single workflow deployment, for example as the content repository for the asset management layer of a content delivery workflow. This is a considerably more predictable, and hence simpler to architect, environment that the data lake.
Often, as in the case of a MAM for streaming playout, a single node type is deployed. The I/O profile is typically heavily biased towards streaming reads and metadata reads, with a smaller portion of writes for ingest.
There are trade-offs to be aware of as cluster size increases into the extra-large cluster scale. The larger the node count, the more components are involved, which increases the likelihood of a hardware failure. When the infrastructure becomes large and complex enough, there is more often than not a drive failing or a node in an otherwise degraded state. At this point, the cluster can be in a state of flux such that composition, or group, changes and drive rebuilds/data re-protection operations will occur frequently enough that they can start to significantly impact the workflow.
Higher levels of protection are required for large clusters, which has a direct impact on capacity utilization. Also, cluster maintenance becomes harder to schedule since many workflows, often with varying availability SLAs, need to be accommodated.
Additional administrative shortcomings that also need to be considered when planning on an extra-large cluster include that InsightIQ only supports monitoring clusters of up to eighty nodes and the OneFS Cluster Event Log (CELOG) and some of the cluster WebUI and CLI tools can prove challenging at an extra-large cluster scale.
That said, there can be wisdom in architecting a clustered NAS environment into smaller buckets and thereby managing risk for the business vs putting the ‘all eggs in one basket’. When contemplating the merits of an extra-large cluster, also consider:
- Performance management
- Risk management
- Accurate workflow sizing
- Complexity management