
Job engine recommendations
Job engine recommendations
-
In a OneFS powered cluster, there are jobs that are responsible for taking care of the health and maintenance of the cluster itself. These jobs are all managed by the OneFS job engine. The Job Engine runs, or maps, jobs across the entire cluster and reduces them into smaller work items, which are allocates to multiple worker threads on each node. Jobs are typically run as background tasks across the cluster, using spare or especially reserved capacity and resources.
With large clusters, there is obviously a high degree of opportunity for job parallelization across a high node count. The flip side to this is that there is also an increased management overhead as a result of coordinating tasks across a large, distributed infrastructure. There is also the need to deal in the background with increased levels of hardware transience, failure, and repair. As such, the Job Engine relies upon fine grained impact measurement and management control in order to avoid significantly impacting the core workflows.
The Job Engine jobs themselves can be categorized into three primary classes:
Job category
Description
File system maintenance
These jobs perform background file system maintenance, and typically require access to all nodes. These jobs are required to run in default configurations, and often in degraded cluster conditions. Examples include file system protection and drive rebuilds.
Feature support jobs
The feature support jobs perform work that facilitates some extended storage management function, and typically only run when the feature has been configured. Examples include deduplication and anti-virus scanning.
User action jobs
These jobs are run directly by the storage administrator to accomplish some data management goal. Examples include parallel tree deletes and permissions maintenance.
Figure 10. OneFS Job Engine job classes
The Job Engine allows up to three jobs to be run simultaneously. This concurrent job execution is governed by the following criteria:
- Job Priority
- Exclusion Sets - jobs which cannot run together (FlexProtect and AutoBalance)
- Cluster health - most jobs cannot run when the cluster is in a degraded state.
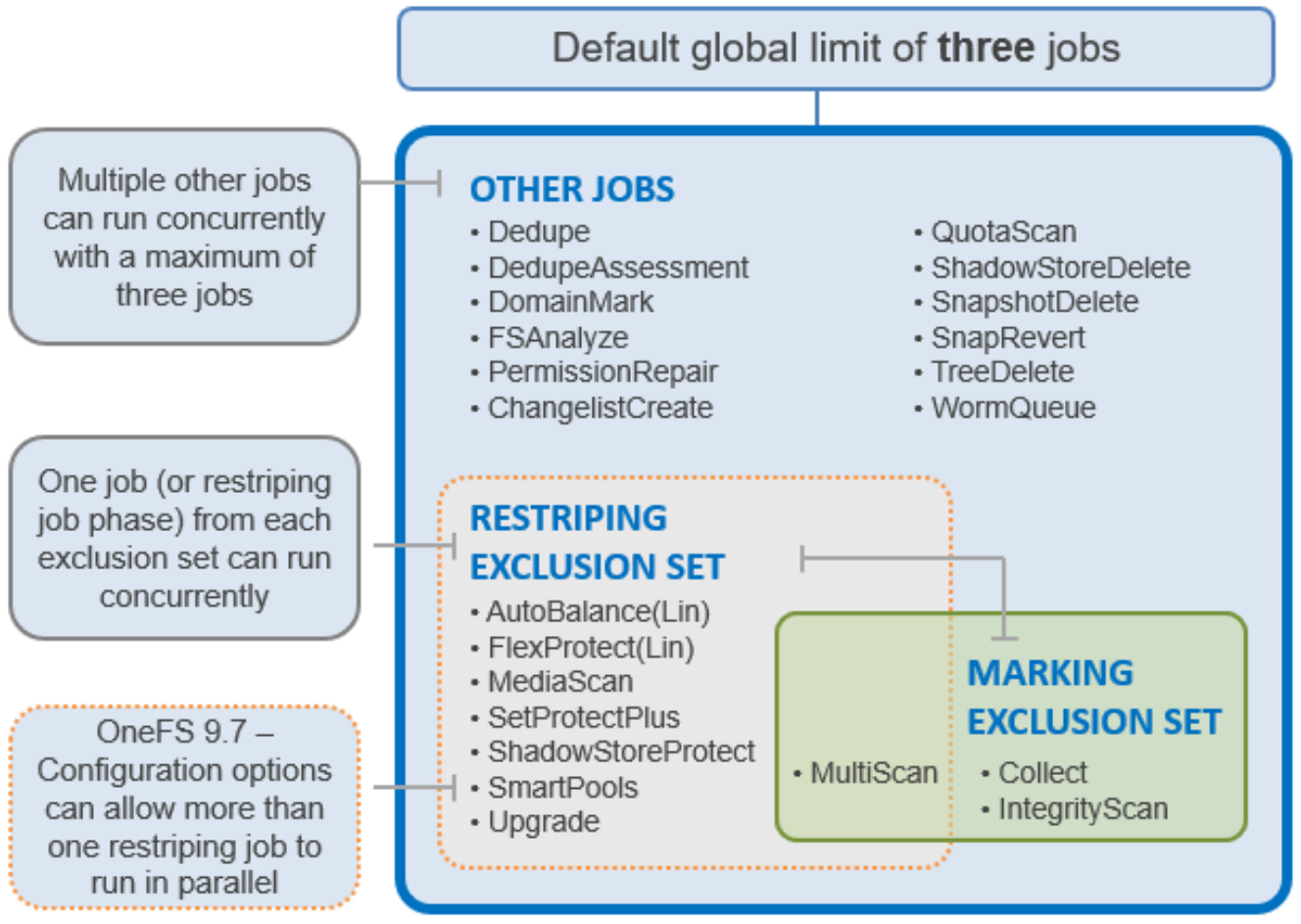
Figure 11. Job Engine exclusion sets
The default, global limit of 3 jobs does not include jobs for striping or marking; one job from each of those categories can also run concurrently.
For optimal cluster performance, we recommend observing the following Job Engine best practices:
- Schedule regular maintenance jobs to run during the cluster’s low usage hours—overnight, weekends.
- Maintain 15% cluster free space due to the amount of work that SmartPools (if licensed) will do to rebalance data. If SmartPools is unlicensed, SetProtectPlus will be run instead.
- Where possible, use the default priority, impact and scheduling settings for each job.
- When reconfiguring the default priority, schedule and impact profile for a job, consider the following questions:
- What resources am I impacting?
- What would I be gaining or losing if I re-prioritized this job?
- What are my impact options and their respective benefits and drawbacks?
- How long will the job run and what other jobs will it contend with?
- In a large heterogeneous cluster, tune job priorities and impact policies to the level of the lowest performance tier.
- To complement the four default impact profiles, create additional profiles such as “daytime_medium”, “after_hours_medium”, or “weekend_medium”, to fit specific environment needs.
- Ensure the cluster, including any individual node pools, is less than 85% full, so performance is not impacted and that there is always sufficient space to re-protect data in the event of drive failures. Also enable virtual hot spare (VHS) to reserve space in case you need to smartfail devices.
- Configure and pay attention to alerts. Set up event notification rules so that you will be notified when the cluster begins to reach capacity thresholds. Make sure to enter a current email address to ensure you receive the notifications.
- Recommend running MediaScan run to completion before upgrading. However, given the number of drives in a typical large cluster, MediaScan will take a significant duration, so budget time appropriately.
- By default, FlexProtect is the only job allowed to run if a cluster is in degraded mode. Other jobs will automatically be paused and will not resume until FlexProtect has completed and the cluster is healthy again.
- Restriping jobs only block each other when the current phase may perform restriping. This is most evident with MultiScan, whose final phase only sweeps rather than restripes. Similarly, MediaScan, which rarely ever restripes, is usually able to run to completion more without contending with other restriping jobs.
- FlexProtect can take longer than expected on large clusters - typically up to a day or more. SmartFailing and replacing entire nodes can also be a very lengthy process.
- If FlexProtect is running, allow it to finish completely before powering down any node(s), or the entire cluster. While shutting down the cluster during restripe will not hurt anything directly, it does increase the risk of a second device failure before FlexProtect finishes re-protecting data.
- If you need to delete snapshots and there are down or smartfailed devices on the cluster, or the cluster is in an otherwise “degraded protection” state, contact Dell Technical Support for assistance.
- SyncIQ, the OneFS replication product, does not use job engine. However, it has both influenced, and been strongly influenced by, the job engine’s design. SyncIQ also terms its operations "jobs", and its processes and terminology bear some similarity to job engine. The job engine impact management framework is aware of the resources consumed by SyncIQ, in addition to client load, and will throttle jobs accordingly.
Further information is available in the Dell PowerScale OneFS Job Engine white paper.