
Failure domains and neighborhoods
Failure domains and neighborhoods
-
The PowerScale Gen6 platform, where four nodes are contained in a 4RU chassis, enhances the concept of disk pools, node pools, and ‘neighborhoods’ to add another level of resilience into the OneFS failure domain concept.
The PowerScale Gen6 chassis architecture provides three fundamental areas of hardware resilience, in addition to data protection using OneFS erasure coding. These are of particular importance in large clusters, where the sheer scale of componentry involved suggests a higher rate of hardware failure. These three areas of resilience are:
- Drive sled protection
- Partner node protection
- Chassis protection
In OneFS, a failure domain is the portion of a dataset that can be negatively impacted by a specific component failure. A disk pool consists of a group of drives spread across multiple compatible nodes, and a node usually has drives in multiple disk pools which share the same node boundaries. Since each piece of data or metadata is fully contained within a single disk pool, OneFS considers the disk pool as its failure domain.
With sled protection, each drive in a sled is automatically located in a different disk pool. This ensures that if a sled is removed, rather than a failure domain losing four drives, the affected failure domains each only lose one drive.
For larger clusters, ‘neighborhoods’ help organize and limit the width of a disk pool. Neighborhoods also contain all the disk pools within a certain node boundary, aligned with the disk pools’ node boundaries. As such, a node will often have drives in multiple disk pools, but a node will only be in a single neighborhood.
Neighborhoods, node pools, and tiers are all layers on top of disk pools. Node pools and tiers are used for organizing neighborhoods and disk pools.
The primary purpose of neighborhoods is to improve reliability of large clusters, and guard against data unavailability from the accidental removal of drive sleds, for example. For self-contained nodes like the PowerScale F710, OneFS has an ideal size of 20 nodes per node pool, and a maximum size of 39 nodes. On the addition of the 40th node, the nodes split into two neighborhoods of twenty nodes. However, for the Gen6 modular chassis-based platform, the ideal size of a neighborhood changes from 20 to 10 nodes. This protects against simultaneous node-pair journal failures and full chassis failures.
Neighborhood
F-series nodes
H-series and A-series nodes
Smallest Size
3
4
Ideal Size
20
10
Maximum Size
39
19
Partner nodes are nodes whose journals are mirrored. With the PowerScale chassis-based platforms, rather than each node storing its journal in NVRAM as in previous platforms, the nodes’ journals are stored on SSDs - and every journal has a mirror copy on another node. The node that contains the mirrored journal is referred to as the partner node. There are several reliability benefits gained from the changes to the journal. For example, SSDs are more persistent and reliable than NVRAM, which requires a charged battery to retain state. Also, with the mirrored journal, both journal drives have to die before a journal is considered lost. As such, unless both of the mirrored journal drives fail, both of the partner nodes can function as normal.
With partner node protection, where possible, nodes will be placed in different neighborhoods - and hence different failure domains. Partner node protection is possible once the cluster reaches five full chassis (20 nodes) when, after the first neighborhood split, OneFS places partner nodes in different neighborhoods:
Partner node protection increases reliability because if both nodes go down, they are in different failure domains, so their failure domains only suffer the loss of a single node.
For larger clusters, chassis protection ensures that each of the four nodes within each chassis will be placed in a separate neighborhood. Chassis protection becomes possible at 40 nodes, as the neighborhood split at 40 nodes enables every node in a chassis to be placed in a different neighborhood. As such, when a 38-node Gen6 cluster is expanded to 40 nodes, the two existing neighborhoods will be split into four 10-node neighborhoods:
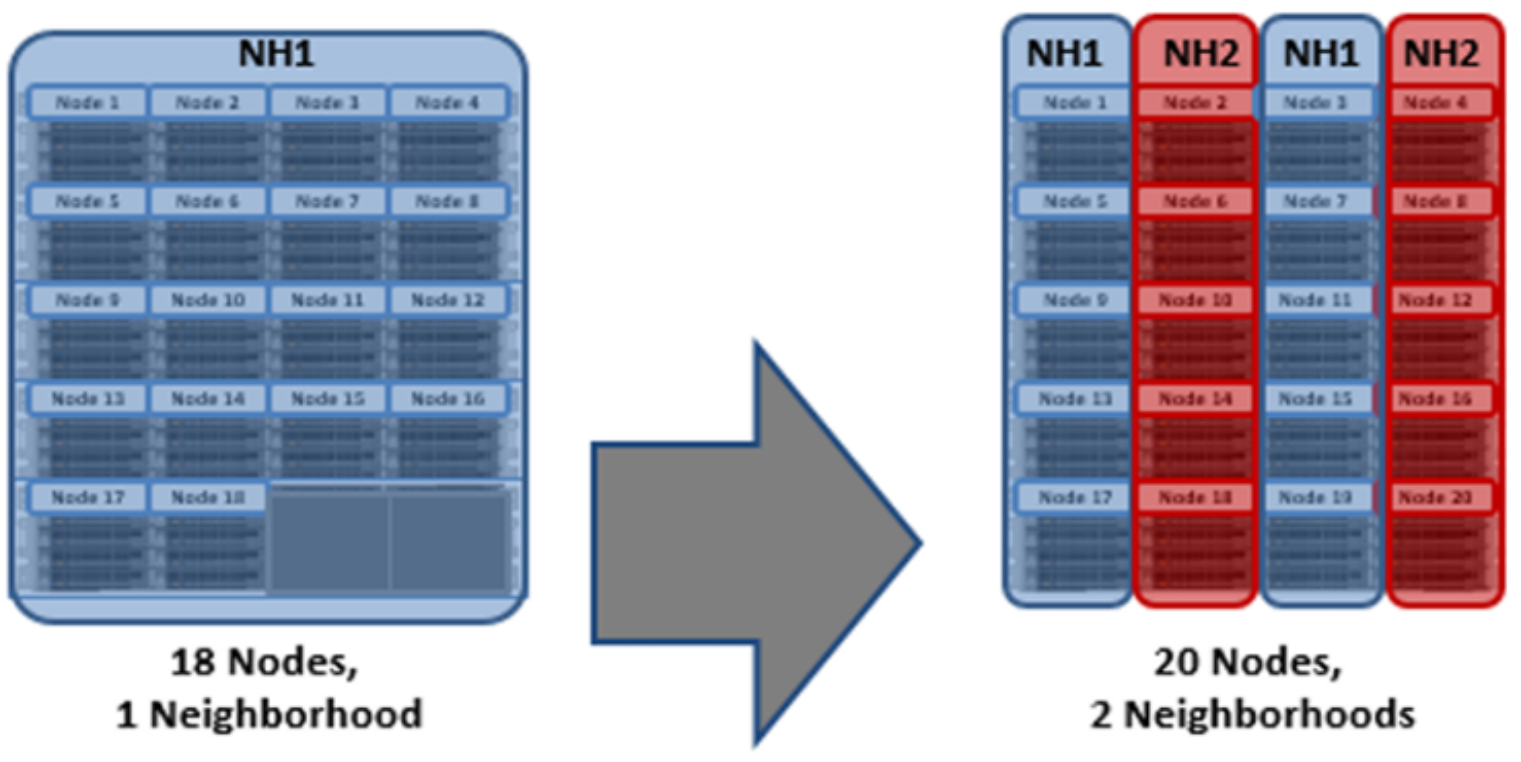
Figure 8. OneFS Neighborhood split – 20 Nodes
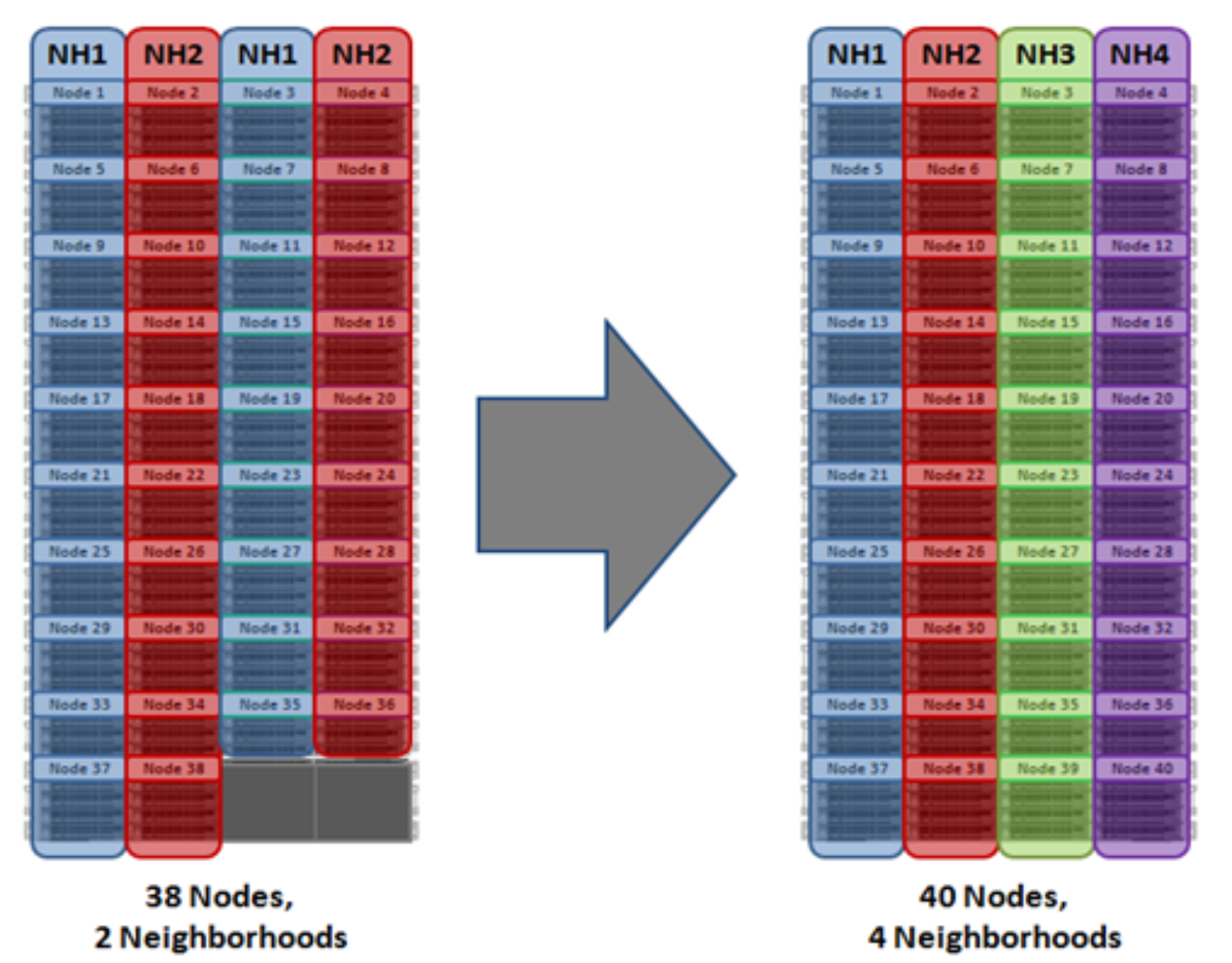
Figure 9. OneFS Neighborhood split – 40 Nodes
Chassis protection ensures that if an entire chassis failed, each failure domain would only lose one node.
So, in summary, a Gen6 platform cluster running will have a reliability of at least one order of magnitude greater than previous generation clusters of a similar capacity as a direct result of the following enhancements:
- Mirrored Journals
- Neighborhoods
- Mirrored Boot Drives
Note that during the neighborhood split process, the job engine will need to run to complete the needed REPROTECT as you add new nodes. There may be up to a 20% performance impact to writes and some read operations during this time. The load mitigation options available are either to reduce the impact level of the job to ‘LOW’ or to disable the job entirely during peak times. However, clearly the downside to both these options is an increase in the time to job completion.