
Tuning OneFS for HDFS operations
Tuning OneFS for HDFS operations
-
OneFS TCP tuning
The default TCP stack of OneFS requires tuning for Hadoop and 40 GbE connectivity. The tuning must be done within the CLI directly on PowerScale. A tcptune.sh script is available at GitHub.
Run sh ./tcptune.sh Max to make the changes. An example script run is shown below:
Before changes:
isilon# sh ./tcptune.sh Max
Tuning TCP stack to Max
TCP sysctls before...
kern.ipc.maxsockbuf=2097152
net.inet.tcp.sendbuf_max=2097152
net.inet.tcp.recvbuf_max=2097152
net.inet.tcp.sendbuf_inc=8192
net.inet.tcp.recvbuf_inc=16384
net.inet.tcp.sendspace=131072
net.inet.tcp.recvspace=131072
efs.bam.coalescer.insert_hwm=209715200
efs.bam.coalescer.insert_lwm=178257920
After changes:
Apply tuning...
Value set successfully
Value set successfully
Value set successfully
Value set successfully
Value set successfully
Value set successfully
Value set successfully
Value set successfully
TCP sysctls after...
kern.ipc.maxsockbuf=104857600
net.inet.tcp.sendbuf_max=52428800
net.inet.tcp.recvbuf_max=52428800
net.inet.tcp.sendbuf_inc=16384
net.inet.tcp.recvbuf_inc=32768
net.inet.tcp.sendspace=26214400
net.inet.tcp.recvspace=26214400
efs.bam.coalescer.insert_hwm=209715200
efs.bam.coalescer.insert_lwm=178257920
net.inet.tcp.mssdflt=8948
Block sizes
On a PowerScale cluster, the default HDFS block size is 128 MB, which optimizes performance for most use cases. Aligning HDFS client block size with OneFS HDFS block size lets PowerScale nodes read and write in large blocks, which can decrease drive-seek operations and increase performance for MapReduce jobs.
HDFS connection and limits
A four-node PowerScale cluster would support 1,600 parallel HDFS connections in a minute. That is 1600 YARN containers before tasks begin to fail due to timeout.
If you consider a compute machine with dual 24-core processors, that would be 48 cores with hyperthreading enabled, and the total cores will be 48 * 2 = 96. Considering one core for each container, there will be 96 containers a Physical compute server.
From the above details, we can determine Fan-in ration as 1600 / 96 ~= 16 servers or 4:1 compute server to PowerScale node ratio.
HDFS Statistics for tuning
Run the isi statistics command to obtain statistics for client connections, the file system, and protocols. For HDFS protocol statistics, run isi statistics pstat –protocol=hdfs.
By analyzing the columns titled NetIn and NetOut, you can determine whether HDFS connections are predominantly reading or writing data. Looking at the distribution if input and output across all the nodes shows whether Hadoop is using all the nodes for a MapReduce job.
Hadoop scratch space
Local high-speed disk SSD is preferred for scratch space. A local direct-attached disk will always be faster than a NFS-mounted file system for a scratch disk. This represents a standard analytics workflow: The shared data—remote/HDFS; the scratch/shuffle space— should be local to node for better performance. If sufficient local disk is not available, use an NFS mount to provide extra disk space to a disk lite client through NFS from the same Isilon cluster. However, it will always have performance implications, since you are placing this data across the wire on the same shared resource that HDFS is using. This setting would allow modification to the location of the mapred shuffle space if needed.
Storage pools: NodePools for different datasets
A difficulty arises if you are analyzing two different datasets, one with large files and another with small files. In such a case, you might be able to cost-effectively store and optimally analyze both types by using storage pools. Storage pools let you group different files by attributes and then store them in different pools of storage: Small files can be routed by a OneFS policy to SSDs, for instance, and large files can be routed to X-Series nodes. Then, you can use OneFS SmartConnect zones to associate a set of compute clients with each dataset to optimize the performance of the MapReduce jobs that analyze each set. For more information, see the section Align datasets with storage pools. You could, for example, direct one compute cluster to S-series DataNodes and another compute cluster to X-series DataNodes with Isilon virtual racks. For more information, see the section on rack awareness.
Data protection
OneFS takes a more efficient approach to data protection than HDFS. The HDFS protocol, by default, replicates a block of data three times to protect it and to make it highly available (3X Mirroring). Instead of replicating the data, OneFS stripes the data across the cluster over its internal InfiniBand network and protects the data with forward error correction codes.
Best practice: Use a OneFS protection policy that meets the requirements and suggested level for the Isilon cluster configuration. If more nodes are added, the protection policy may need to be reevaluated.
Data access patterns
For most if not all workflows the data access pattern is best represented by the streaming setting. This will increase sequential-read performance, OneFS will stripe data across more drives and prefetches data well before data requests. For large quantities of small files (<1 MB), concurrent access may be better because the impact of prefetch will be much less.
The following graph shows the performance of H5600 for streaming and concurrent data access.
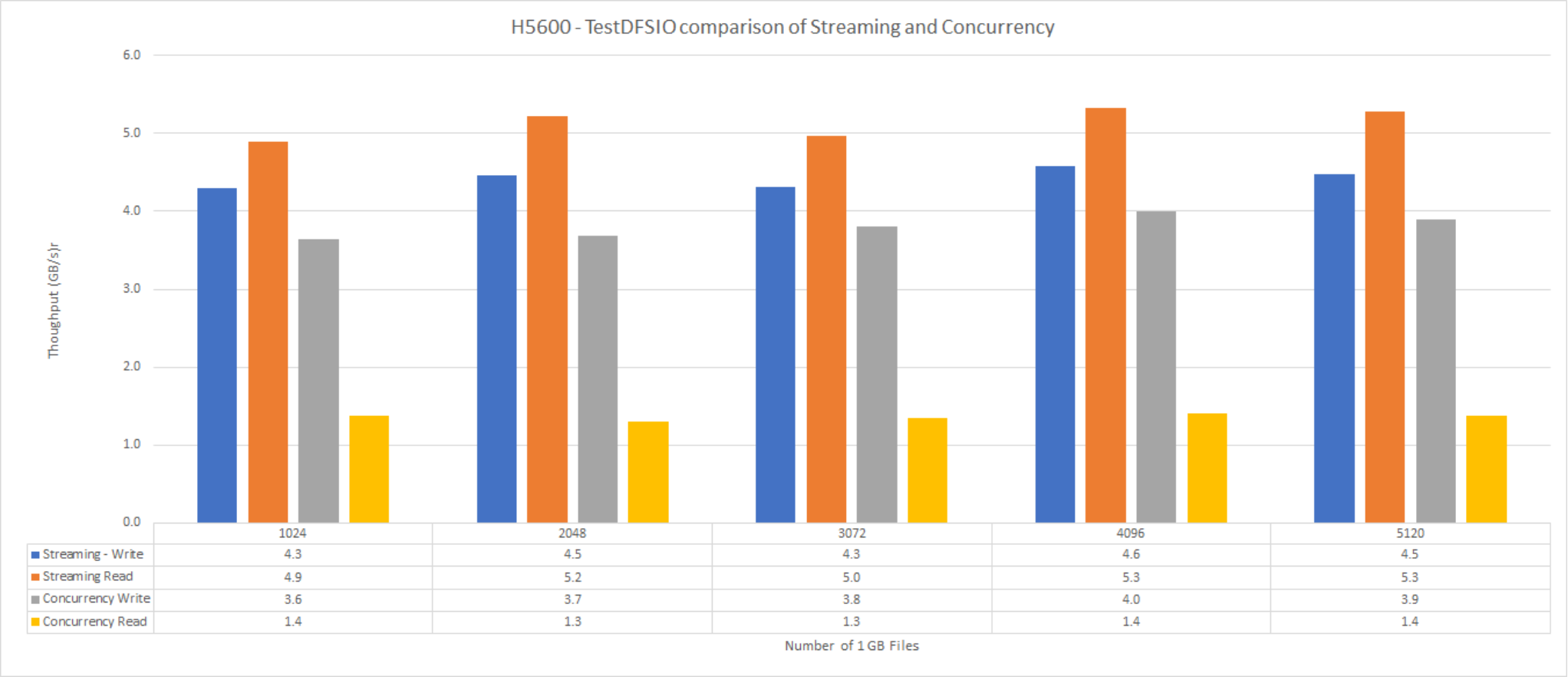
Figure 5. F800 streaming and concurrency
The H5600 streaming and concurrency measured here is the aggregate throughput of a DFSIO job with different counts of 1 GB files.