
Temporary site outage (TSO)
Temporary site outage (TSO)
-
Temporary site outages occur when a site is temporarily inaccessible to other sites in a replication group. ECS allows administrators two configuration options that affect how objects can be accessed during a temporary site outage.
- Disable the Access During Outage (ADO) option, which retains strong consistency by:
- Continuing to allow access to data owned by sites that are accessible
- Preventing access to data owned by an inaccessible site
- Enable the Access During Outage option, which allows read access and, optionally, write access to all geo-replicated data including that which is owned by the site marked as failed. During a TSO with Access During Outage enabled, the data in the bucket temporarily switches to eventual consistency. Once all sites are back online, the data reverts to strong consistency.
The default is for Access During Outage to be disabled.
The Access During Outage option can be set at the bucket level, so you can enable this option for some buckets and not for others. This bucket option can be changed at any time as long as all sites are online; it cannot be changed during a site failure.
During a temporary site outage:
- Buckets, namespaces, object users, authentication providers, replication groups, and NFS user and group mappings cannot be created, deleted, or updated from any site. (Replication groups can be removed from a VDC during a permanent site failover.)
- You cannot list buckets for a namespace when the namespace owner site is not reachable.
- File systems within NFS buckets that are owned by the unavailable site are read-only.
- When you copy an object from a bucket owned by the unavailable site, the copy is a full copy of the source object. Therefore, the same object's data is stored more than once. Under normal non-TSO circumstances, the object copy consists of the data indexes of the object, not a full duplicate of the object's data.
- OpenStack Swift users cannot log in to OpenStack during a TSO because ECS cannot authenticate Swift users during the TSO. After the TSO, Swift users must re-authenticate.
Default TSO behavior
Because ECS provides strong consistency, I/O requests require checking with the owner before responding. If a site is inaccessible to other sites within a replication group, some access to buckets and objects might be disrupted.
The following table shows which access is required for an operation to succeed.
Table 15. Access requirements
Operation
Requirements for success
Create object
The bucket owner must be accessible.
List objects
The bucket owner and all objects in the bucket must be accessible by the requesting node.
Read object
Update objectThe requestor must be either one of these:
- The object owner and bucket owner (bucket ownership is only required if Access During Outage is enabled on the bucket containing the object)
- Both the object owner and bucket owner, which are accessible by the requesting node
- A create object operation includes updating the bucket listing with the new object name. This action requires access to the bucket owner and so will fail if the requesting site does not have access to the bucket owner.
- Listing objects in a bucket requires both listing information from the bucket owner and head information for each object in the bucket. Therefore, the following bucket listing requests will fail if Access During Outage is disabled:
- Requests to list buckets owned by a site that is not accessible to the requestor
- Buckets that contain objects owned by a site that is not accessible to the requestor
- Read object requires first reading the object metadata from the object owner.
- If the requesting site is the object owner and Access During Outage is disabled, the request will succeed.
- If the requesting site is the object and bucket owner, the request will succeed.
- If the object owner is not local, the site needs to check with the bucket owner to find the object owner. If either the object owner or bucket owner sites are unavailable to the requestor, the read operation will fail.
- Updates to objects require successfully updating the object metadata on the object owner.
- If the requesting site is the object owner and Access During Outage is disabled, the request will succeed.
- If the requesting site is the object and bucket owner, the request will succeed.
- If the object owner is not local, the site must check with the bucket owner to find the object owner. If either the object owner or bucket owner sites are unavailable to the requestor, the read operation will fail.
The following figure shows an example of the bucket and object layout in a three-site configuration.
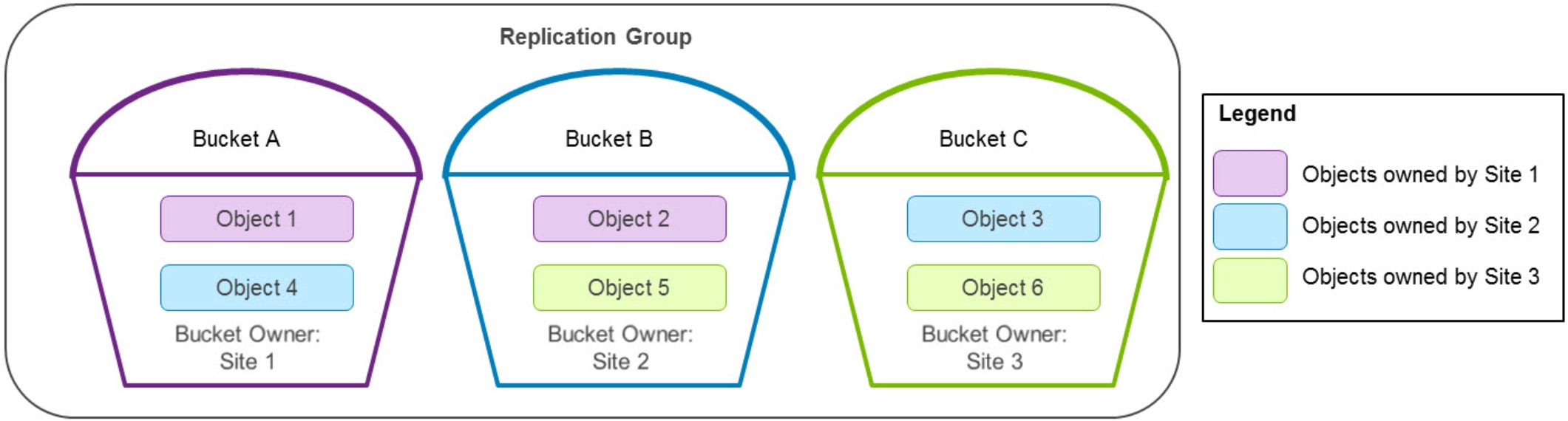
Figure 11. Bucket and object ownership example
The following table lists which operations will succeed or fail in the three-site configuration example in the preceding figure if Site 1 is inaccessible to the other sites in the replication group. To simplify interpretation of the table, the inaccessible site is listed as “failed” and the other two sites are listed as “online.”
Table 16. Operations that succeed or fail if Site 1 is inaccessible to other sites
Operation
Bucket/object
Request sent to
Site 1 (failed)
Site 2 (online)
Site 3 (online)
Create objects in
Bucket A
Success
Bucket owned locally
Fail
Cannot access bucket owner
Fail
Cannot access bucket owner
Bucket B
Fail
Cannot access bucket owner
Fail
Cannot access bucket owner
Fail
Cannot access bucket owner
Bucket C
Fail
Cannot access bucket owner
Success
Bucket owned by online site
Success
Bucket owned locally
List objects in
Bucket A
Fail
Although bucket is owned locally, it contains an object that is owned by a site it cannot access
Fail
Cannot access bucket owner
Fail
Cannot access bucket owner
Bucket B
Fail
Cannot access bucket owner
Fail
Although bucket is owned locally, it contains an object that is owned by the failed site
Fail
Although bucket owner is online, the bucket contains an object that is owned by the failed site
Bucket C
Fail
Cannot access bucket owner
Success
Bucket owner is online site and all objects are from online sites
Success
Bucket owned locally and all objects are from online sites
Read or update object
Object 1
Success
Object owned locally
Fail
Cannot access object owner
Fail
Cannot access object owner
Object 2
Success
Object owned locally
Fail
Cannot access object owner
Fail
Cannot access object owner
Object 3
Fail
Cannot access object owner
Success
Object owned locally
Success
Object is not locally owned so gets object owner from bucket owner, which is online
Object 4
Fail
Cannot access object owner
Success
Object owned locally
Fail
Object is not locally owned so requires accessing the bucket owner, which is the failed site
Object 5
Fail
Cannot access object owner
Success
Object is not locally owned, so it gets object owner from bucket owner
Success
Object owned locally
Object 6
Fail
Cannot access object owner
Success
Object is not locally owned, so gets object owner from bucket owner, which is online
Success
Object owned locally
TSO behavior with Access During Outage enabled
When a site is first inaccessible to other sites within a replication group, the behavior is detailed in the default TSO behavior section. After the heartbeat is lost between sites for a sustained period of time (the default is 15 minutes), ECS marks a site as failed.
Enabling Access During Outage (ADO) on a bucket changes the TSO behavior after a site is marked as failed, allowing objects in that bucket to use eventual consistency. Thus, after a site is marked as temporarily failed, any buckets that have the option Access During Outage enabled will support reads and, optionally, writes from a non-owner site. ECS accomplishes this result by allowing usage of the replicated metadata when the authoritative copy on the owner site is unavailable. You can change the Access During Outage bucket option at any time except during a site failure.
The benefit of enabling Access During Outage is that it allows access to data after a site is marked as failed. The disadvantage is that the data returned might be outdated.
ECS 3.1 and later versions have an additional bucket option for Read-Only Access During Outage. This option ensures that object ownership never changes and removes the chance of conflicts otherwise caused by object updates on both the failed and online sites during a TSO.
The Read-Only Access During Outage option is available during bucket creation only, it cannot be modified afterwards.
The disadvantage of Read-Only Access During Outage is that after a site is marked as failed, no new objects can be created. Also, no existing objects in the bucket can be updated until after all sites are back online.
As previously mentioned, a site is marked as failed when the heartbeat is lost between sites for a sustained period of time. The default is 15 minutes. If the heartbeat is lost for a sustained period of time:
- In a two-site configuration, each site considers itself as online and mark the other site as failed.
- In a configuration with three or more sites, a site will only be marked as failed if both of these conditions are met:
- Most sites lose heartbeat for the sustained period of time to the same ECS site
- All remaining sites are marked as online
A failed site might still be accessible by clients and applications—for example, when a company’s internal network loses connectivity to a single site, but extranet networking remains operational. As an example, in a five-site configuration, if Sites 2 through 5 lose network connectivity to Site 1 for a sustained period of time ECS will mark Site 1 as temporarily failed. If Site 1 is still accessible to clients and applications, it can service requests for locally owned buckets and objects because lookups to other sites are not required. However, requests to Site 1 for non-owned buckets and objects will fail. The following table shows which access is required after a site is marked as failed for an operation to succeed if Access During Outage is enabled.
Table 17. Successful operations after a site is marked as failed with Access During Outage enabled
Operation
Request sent to the failed site
(in a federation that contains three or more sites)
Request sent to an online site including:
- Any online site in a federation that contains three or more sites
- Either site in a federation that contains only two sites
Create object
Success for locally owned buckets unless Read-Only Access During Outage is enabled on the bucket
Fail for remotely owned buckets
Success unless Read-Only Access During Outage is enabled on the bucket
List objects
Only lists objects in its locally owned buckets if all objects are also locally owned
Success
Will not include objects owned by failed site that have not finished being replicated
Read object
Success for locally owned objects in locally owned buckets (might not be most recent version)
Fail for remotely owned objects
Success.
If the object is owned by the failed site, it requires that the original object had finished replication before the failure occurred
Update object
Success for locally owned objects in locally owned buckets unless Read-Only Access During Outage is enabled on the bucket
Fail for remotely owned objects
Success, unless Read-Only Access During Outage is enabled on the bucket.
Acquires ownership of object
- Create object:
After a site is marked as failed, create object will not succeed if Read-Only Access During Outage is enabled on the bucket. If it is disabled:
- In a federation that contains three or more sites, the site marked as failed—if accessible by clients or applications—can create objects only in its locally owned buckets. These new objects can only be accessed from this site. Other sites will not be aware of these objects until the failed site is back online and they gain access to the bucket owner.
- The online sites can create objects in any bucket including buckets owned by the site marked as failed. Creating an object requires updating the bucket listing with the new object name. If the bucket owner is down, an object history is created. This action inserts the object into the bucket listing table during recovery or rejoin operations of the bucket owner.
- List object:
- In a federation that contains three or more sites, the site marked as failed requires local ownership of both the bucket and all objects within the bucket to successfully list objects in a bucket. The listing from the failed site does not include objects created remotely while it is marked as temporarily failed.
- The online sites can list objects in any bucket including a bucket owned by the site marked as failed. The online site lists the latest version of the bucket listing that it has; the version might be slightly outdated.
- Read object:
- In a federation that contains three or more sites, the failed site, if accessible by clients or applications, can read only locally owned objects in locally owned buckets.
- The read request to a failed site first needs access to the bucket owner to validate the current object owner. If it can access the bucket owner and the current object owner is local, the read request will succeed. If either the bucket owner or the current object owner is not accessible, the read request will fail.
- The online sites can read any objects, including objects owned by the site marked as failed, as long as the original object has completed replication. The online site checks the object history and responds with the latest version of the object that is available. If an object is later updated on the site marked as failed and geo-replication of the updated version was not completed, the older version is used to service the read request.
Note: Read requests sent to online sites where the bucket owner is the failed site will use the online site’s local bucket listing information and object history to determine the object owner.
- Update object:
- After a site is marked as failed, update objects will not succeed if Read-Only Access During Outage is enabled on the bucket. If it is disabled in a federation that contains three or more sites, the failed site, if accessible by clients or applications, can update only locally owned objects in locally owned buckets.
- The update request first needs access to the bucket owner to validate the current object ownership. If it can access the bucket owner and the current object owner is local, the update request will succeed. If either the bucket owner or the current object owner is not accessible, the update request will fail.
- After rejoin operations are complete, this update will not be included in read operations if the remote site also updated the same object during the same TSO.
An online site can update both objects owned by online sites and failed sites. If an object update request is sent to an online site for an object owned by the site marked as failed, the online site will update the latest version of the object available on a system marked as online.
The site performing the update becomes the new object owner and updates the object history with the new owner information and sequence number. This information will be used in recovery or rejoin operations of the original object owner to update the site’s object history with the new owner.
Note: Update requests sent to online sites where the bucket owner is the failed site will use the online site’s local bucket listing information and object history to determine the object owner.
The following example shows what would happen with the bucket and object layout for namespace 1 in the three-site configuration depicted in the following figure.
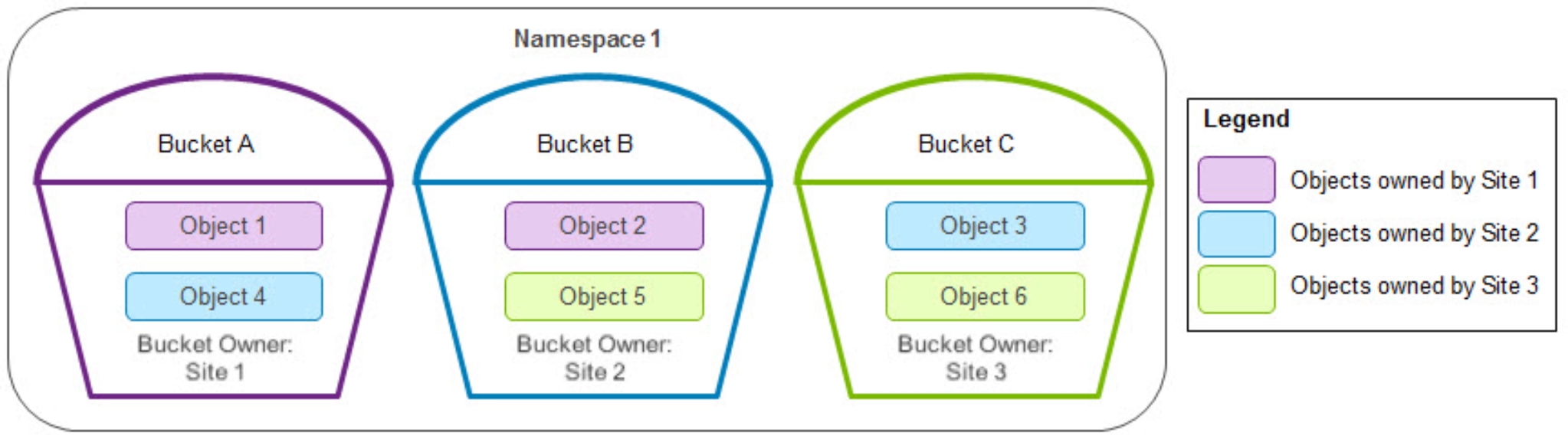
Figure 12. Bucket and object ownership for namespace 1
Table 18 shows an example in this three-site configuration if all three of these conditions are met:
- Access During Outage is enabled.
- Read-Only Access During Outage is disabled.
- Site 1 is marked as failed.
Operation
Bucket/object
Request sent to
Site 1 (marked as failed)
Site 2 or Site 3 (online)
Create objects in
Bucket A
Success
Success
Bucket B
Fail
Failed site can only create objects in locally owned buckets
Success
Bucket C
Fail
Failed site can only create objects in locally owned buckets
Success
List objects in
Bucket A
Fail
Although the bucket is owned locally, it contains remotely owned objects
Success
Will not include objects owned by failed site that have not been replicated
Bucket B
Fail
Failed site can only list objects in locally owned buckets
Success
Bucket C
Fail
Failed site can only list objects in locally owned buckets
Success
Read or update object
Object 1
Success, both object and bucket are owned locally
Success
Requires object to have completed replication before TSO
Update acquires object ownership
Object 2
Fail, bucket is not owned locally
Object 3 Object 4
Object 5
Object 6
Fail
Failed site can only read and update locally owned objects in locally owned buckets
Success
Once the heartbeat is reestablished between sites, the system marks the site as online, and access to this data continues as it did before the failure. The rejoin operation:
- Updates the bucket listing tables
- Updates object ownerships where necessary
- Resumes processing the previously failed sites’ replication queue
Note: ECS only supports access during the temporary failure of a single site.
In the following two-site example, both sites think they are online and mark the other site as failed when a TSO happens. All create, list, read, and update operations succeed.
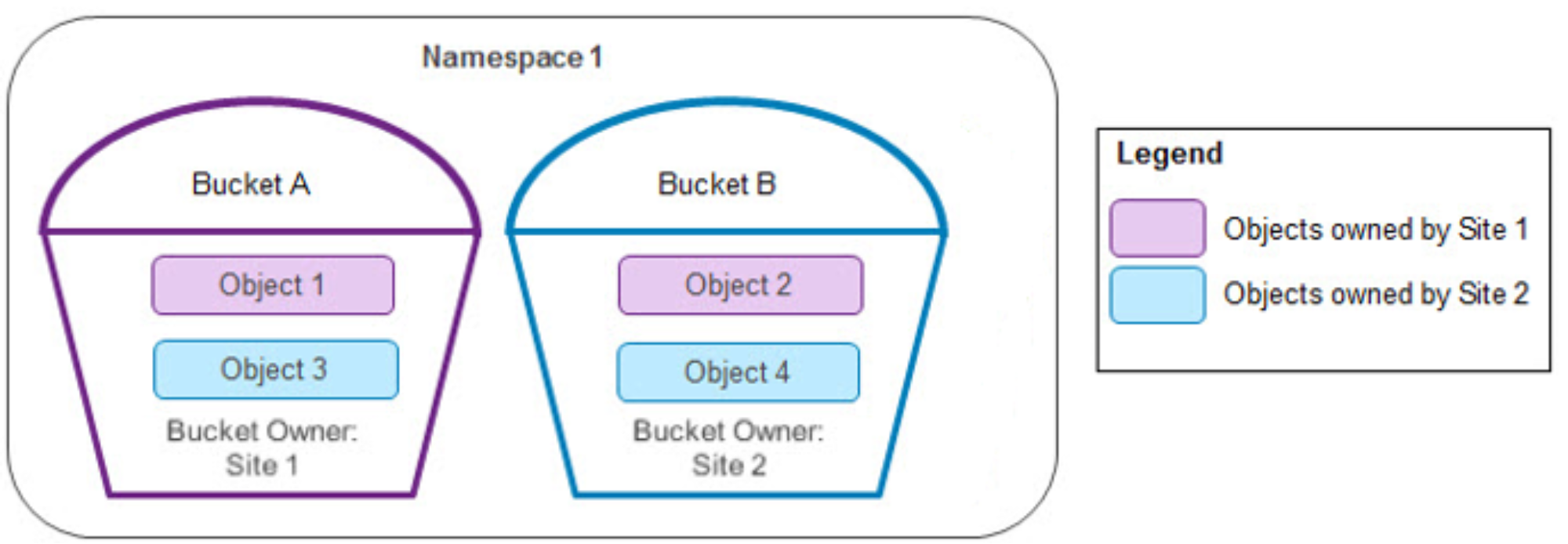
Figure 13. Bucket and object ownership in two sites
During the TSO, all the objects are updated in each site. The following table shows the final data in the site once the heartbeat is reestablished between sites.
Table 19. Winning site after two sites reestablished
Object
Bucket name
Bucket owner
Object owner
“Winning” site
Object 1
Bucket A
Site 1
Site 1
Site 2
Object 2
Bucket B
Site 2
Site 1
Random
Object 3
Bucket A
Site 1
Site 2
Random
Object 4
Bucket B
Site 2
Site 2
Site 1
Note: In this example, starting with ECS version 3.7, for Object 2 and Object 3, the winning site was changed from the site with the latest timestamp to Random.
XOR decoding with three or more sites.
As described in XOR encoding, ECS maximizes storage efficiency of data that is configured with a replication group containing three or more sites. The data in secondary copies of chunks might be replaced by data in a parity chunk after an XOR operation.
Requests for data in a chunk that has been encoded are serviced by the site containing the primary copy. If this site is failed, the request goes to the site with the secondary copy of the object. However, because this copy was encoded, the secondary site must first retrieve the copy of the chunks that were used for encoding from the online primary sites. Then it will perform an XOR operation to reconstruct the requested object and respond to the request. After the chunks are reconstructed, they are also cached so that the site can respond more quickly to subsequent requests.
The following table shows an example of a portion of a chunk manager table on Site 4 in a four-site configuration.
Table 20. Site 4 chunk manager table after completing XOR encoding
Chunk ID
Primary site
Secondary site
Type
C1
Site 1
Site 4
Encoded
C2
Site 2
Site 4
Encoded
C3
Site 3
Site 4
Encoded
C4
Site 4
Parity (C1, C2 & C3)
The following figure illustrates the requests involved in re-creating a chunk to service a read request during a TSO.
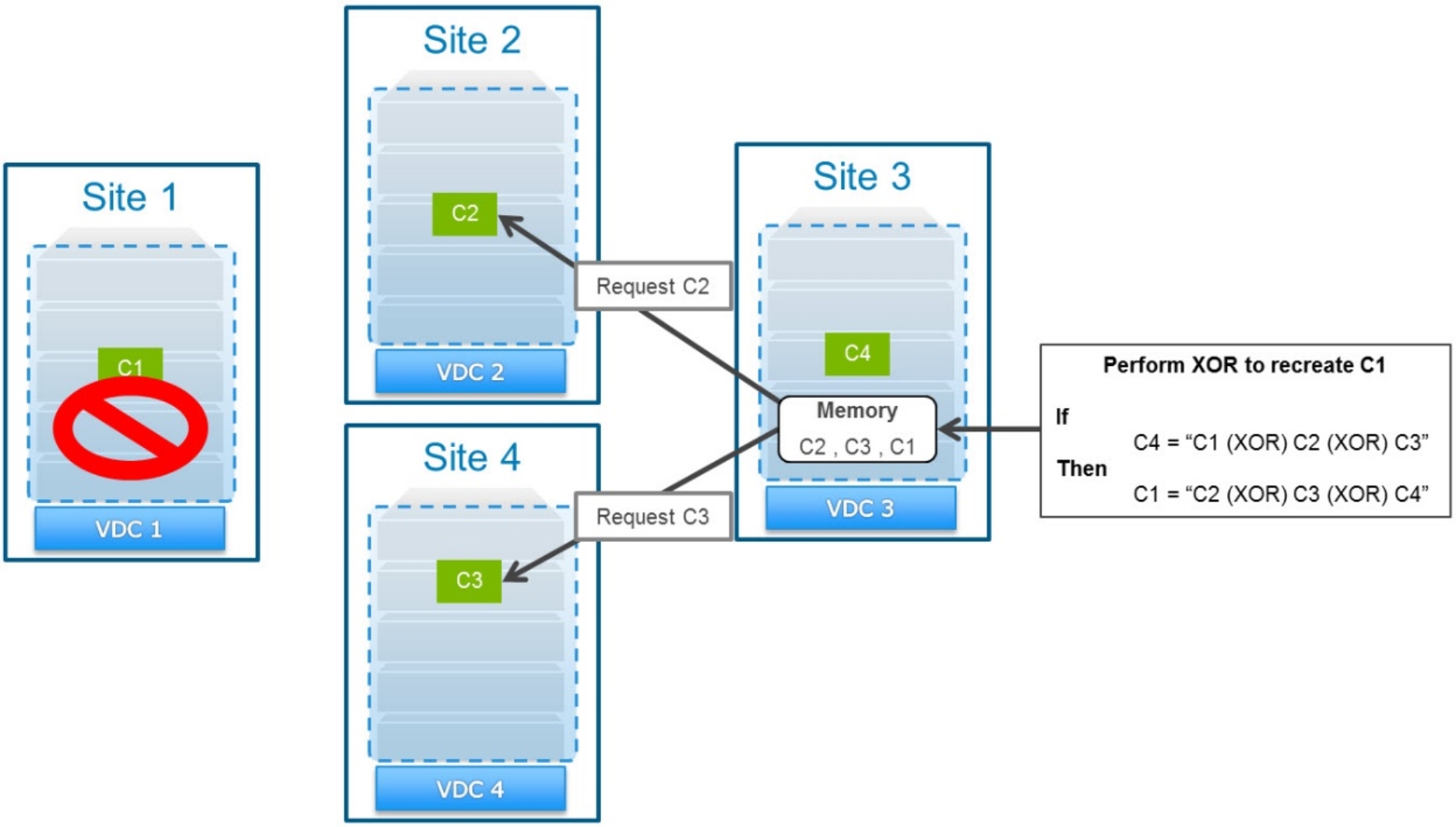
Figure 14. Servicing a read request by reconstructing an XOR-ed chunk
In this example, a read request for an object in chunk C1 when Site 1 is marked as failed initiates the following process:
- Because Site 1 is failed, the request is sent to chunk C1’s secondary site, Site 4.
Site 4 has already performed XORs on chunks C1, C2, and C3. It has replaced its local copy of the data from these chunks with data in parity chunk C4.
- Site 4 requests a copy of chunk C2 from its primary site (Site 2) and caches this copy locally.
- Site 4 requests a copy of chunk C3 from its primary site (Site 3) and caches this copy locally.
- Site 4 performs an XOR operation between the cached chunks C2 and C3 with the parity chunk C4 to re-create chunk C1 and store it locally in cache.
- Site 4 responds to the read request for the object in chunk C1.
Note: The time for reconstruction operations to complete increases linearly based on the number of sites in a replication group.
With passive geo-replication
Any data in a bucket configured with passive geo-replication has between two and four source sites and one or two dedicated replication targets. Data written to the replication targets might be replaced by data in a parity chunk after an XOR operation. Requests for passively geo-replicated data are serviced by the site containing the primary copy. If this site is inaccessible to the requesting site, the data must be recovered from one of the replication target sites.
With passive geo-replication, the source sites are always the object and bucket owners. If a replication target site is marked as temporarily failed, all I/O operations will continue as usual. The only exception is replication, which will continue to queue until the replication target site rejoins the federation.
If one of the source sites fails, requests to the online source site must recover non-locally-owned data from one of the replication target sites. In the following example, Site 1 and Site 2 are the source sites, and Site 3 is the replication target site. An object’s primary copy exists in chunk C1, which is owned by Site 1, and the chunk has been replicated to the target destination, Site 3.
If Site 1 fails and Site 2 gets a request to read that object, Site 2 will have to get a copy from Site 3. If the copy was encoded, the secondary site must first retrieve the copy of the other chunk that was used for encoding from the online primary site. Then it performs an XOR operation to reconstruct the requested object and respond to the request. After the chunks are reconstructed, they are also cached so that the site can respond more quickly to subsequent requests.
The following table shows an example of a portion of a chunk manager table on the passive geo-replication target.
Table 21. Passive geo-replication target chunk manager table after completed XOR encoding
Chunk ID
Primary site
Secondary site
Type
C1
Site 1
Site 3
Encoded
C2
Site 2
Site 3
Encoded
C3
Site 3
Parity (C1 and C2)
The following figure illustrates the requests involved in re-creating a chunk to service a read request during a TSO.
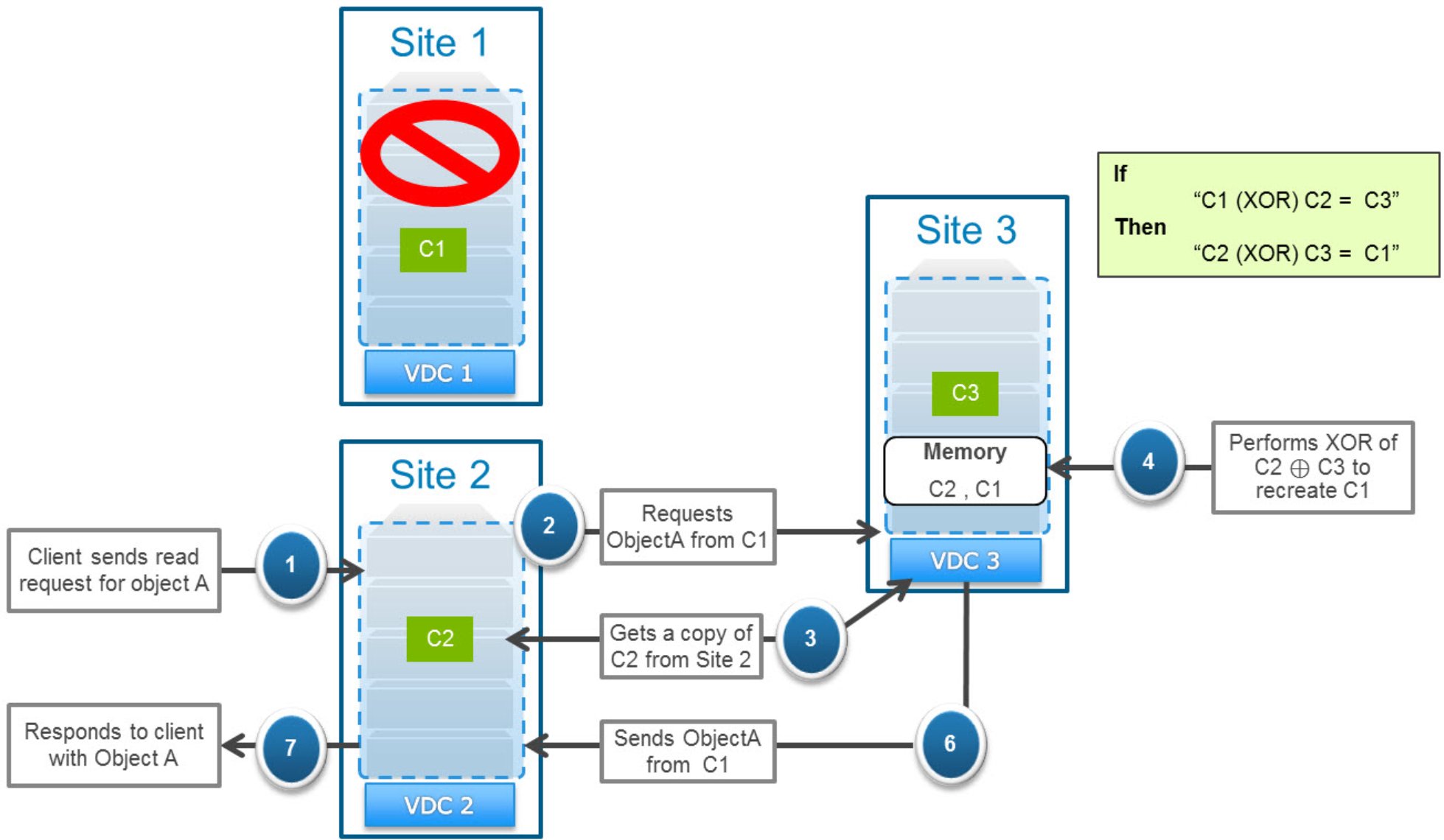
Figure 15. Servicing a read request by reconstructing an XOR-ed chunk
In this example, if a read came in for an object in chunk C1 when Site 1 is marked as temporarily failed, the following process occurs:
- Because Site 1 is failed, the request is sent to chunk C1’s secondary site, Site 3.
Site 3 has already performed XORs on chunks C1 and C2, meaning it has replaced its local copy of the data from these chunks with data in parity chunk C3.
- Site 3 requests a copy of chunk C2 from chunk C2’s primary site (Site 2) and caches this copy locally.
- Site 3 performs an XOR operation between the cached chunk C2 with the parity chunk C3 to re-create chunk C1 and store it locally in cache.
- Site 3 responds to the read request for the object in chunk C1.
With Replicate to All Sites enabled
Buckets configured with the options of Replicate to All Sites and Access During Outage can provide faster read performance. The faster read performance comes not only during a time when all sites are online but during a temporary site outage. No XOR decoding operation is required, and there is a greater chance that the data will be read locally.
Data in buckets with Replicate to All Sites enabled is replicated to each site. Create and update objects are handled the same as if Replicate to All Sites was disabled. However, read and list objects are handled slightly differently because some data might have only completed replication to some sites, but not all, before the primary site failed.
During a read operation, the node servicing the request first checks the latest version of the metadata from the object owner.
If the requesting node Is not the object owner:
- If it has a local copy of the data being requested, it uses the local copy to service the request.
- If the object has been updated by another site that failed before it replicated the data, it returns the version that it has locally.
- If the object owner site is online and replication of the object data was completed to this site, it services the request with its local copy of the data.
- If the object owner site is online and replication of the object data was completed to this site, it requests a copy from the object owner and uses that copy to service the request.
- If the object owner is down and replication of the object was not completed to this site, it uses its local copy of the data, which might not be the latest version.
- If the object owner is down and replication of the object data to the requesting site was not completed, the requesting site requests a copy from the secondary site listed first in the chunk manager table. If that secondary site is the requesting site, the read operation will fail.
During a list objects in a bucket operation, the node requires information from the bucket owner and head information for each object in the bucket. If the site that is the object owner or the bucket owner is down and Access During Outage is also enabled, the node can still service the request if all the remaining sites in the replication group are online. It will list the latest version of the bucket listing that it has; it might be slightly outdated and can vary between sites.
Multiple site failures
ECS only supports access during a temporary failure of a single site within a replication group; furthermore, only one site can be marked as failed. Thus, if more than one site within a replication group is failed concurrently, some operations will fail. The first site determined to be failed (due to sustained loss of heartbeat) is marked as failed in the UI. Any remaining sites that also have a sustained loss of heartbeat are not marked as failed and so are considered online.
As an example, in a replication group of five sites, if Site 1 is identified as having a sustained loss of heartbeat, it is marked as failed. If site 2 is also identified as having a sustained loss of heartbeat, it remains listed as online. In such case:
- If Access During Outage is enabled and the bucket owner is Site 2, reads, creates, or updates sent to other sites will fail regardless of the object owner. This result occurs because ECS first checks with the bucket owner to determine the object owner. Unless the bucket owner is marked as failed, the requestor will send the request to Site 2, and the request will fail.
- Read and update requests sent to Site 2 will only succeed if Site 2 is the object owner (and the bucket owner if Access During Outage is enabled).
- Read and update requests sent to sites other than Site 2 will succeed only if the object owner (and bucket owner if Access During Outage is enabled) is not Site 2.
- Create object will fail if the bucket owner is either Site 1 or Site 2. This result occurs because creating an object requires updating the bucket listing with the new object name. Because it cannot succeed in performing this action on all sites marked as online, the create operation will fail.
- Requests to listing objects in a bucket will only succeed if the requesting site can access the bucket owner and all the objects.
- If the request is sent to Site 2, it will only succeed if Site 2 owns the bucket and all the objects in the bucket.
- If the request is sent to another site, it will only succeed if neither the bucket nor any objects within the bucket are owned by Site 2.