
Detailed performance analysis
Detailed performance analysis
-
To better understand the load on the storage subsystem, the Isilon performance was profiled using Isilon InsightIQ while training the model. In Figure 6, only two compute nodes are performing training (AlexNet, FP16, 1.448 TB dataset). There is an aggregate read throughput of 12 Gbits/sec (1500 MB/sec) and the Isilon front-end network traffic is split evenly between two Isilon nodes. Disk throughput also starts at around 12 Gbits/sec (1500 MB/sec), but it is split evenly between all four Isilon nodes. Additionally, the disk throughput decreases simply because more of the data is coming from Isilon’s cache. For these benchmarks, the cache was cleared before each run and a real-world 1.448 TB data set was used to guarantee the data set couldn’t be cached in-memory on Isilon to ensure a valid load on the disk. The Isilon cluster was configured with 4 nodes with 256 GB RAM each). Note: The 1024 files are read in random order (but sequentially within each file) so some files can be served from cache if they were accessed recently.
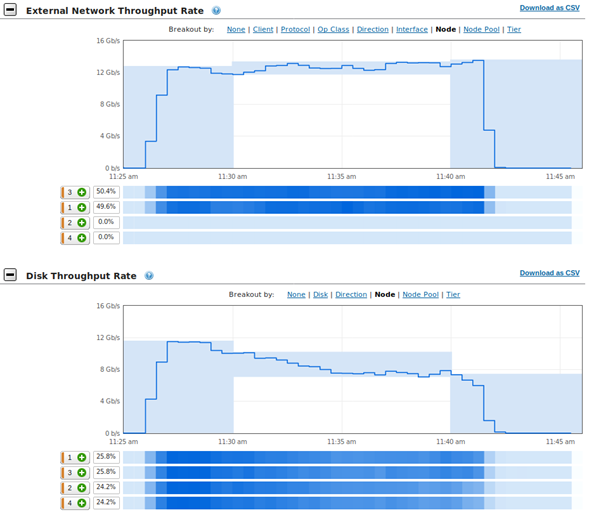
Figure 6. InsightIQ metrics during training of AlexNet, 2 compute nodes, FP16, 1.448 TB dataset
The preceding figure shows the CPU, memory, and GPU utilization on one compute node (with 4 GPU’s), and the network and disk throughput on a single Isilon chassis (4 nodes) when running Resnet50 FP16 training with the 1.448 TB dataset. The training speed is steady at 2941 images/sec throughout the duration of training.
The CPU utilization on the C4140 compute nodes is around 33% out of 40 cores, which are used for file I/O, TFRecords parsing, JPEG decoding, distorting, and cropping.
Only around 19% of 384 GiB of memory on the C4140 compute nodes are used. The Linux buffer (page cache) on the compute server usage increases while it caches the TFRecord files until all of the RAM is used. Although the entire 1.448 TB dataset cannot be cached in the compute node, the 1024 files are read in random order (but sequentially with each file) so some files can be served from the Linux page cache if they were accessed recently.
The network and Isilon are fast enough to feed data to GPUs to keep them at high utilization and to keep the training speed at 2,941 images/sec. The average GPU utilization was around 95% across the four GPUs. This high GPU utilization indicates the system was architected (CPU, memory, network, Isilon, etc.) to avoid any IO bottlenecks.
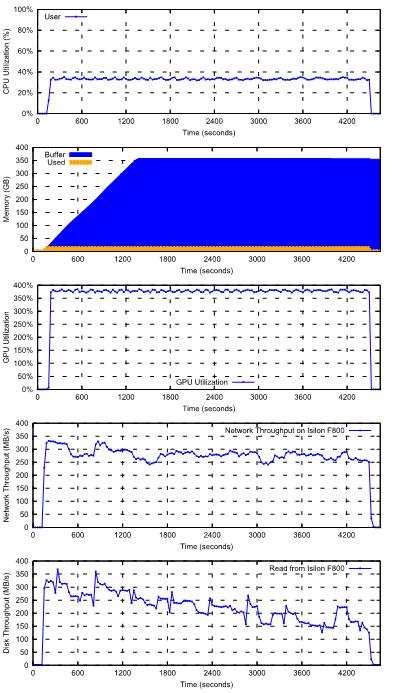
Figure 7. CPU utilization, memory usage and GPU utilization on one compute node, and network and disk throughput on Isilon when running Resnet50 with the 1.448 TB dataset