



Training Neural Network Models for Financial Services with Intel® Xeon Processors
Fri, 12 Jun 2020 12:22:20 -0000
|Read Time: 0 minutes
Originally published on Nov 5, 2018 9:10:17 AM
Time series is a very important type of data in the financial services industry. Interest rates, stock prices, exchange rates, and option prices are good examples for this type of data. Time series forecasting plays a critical role when financial institutions design investment strategies and make decisions. Traditionally, statistical models such as SMA (simple moving average), SES (simple exponential smoothing), and ARIMA (autoregressive integrated moving average) are widely used to perform time series forecasting tasks.
Neural networks are promising alternatives, as they are more robust for such regression problems due to flexibility in model architectures (e.g., there are many hyperparameters that we can tune, such as number of layers, number of neurons, learning rate, etc.). Recently applications of neural network models in the time series forecasting area have been gaining more and more attention from statistical and data science communities.
In this blog, we will firstly discuss about some basic properties that a machine learning model must have to perform financial service tasks. Then we will design our model based on these requirements and show how to train the model in parallel on HPC cluster with Intel® Xeon processors.
Requirements from Financial Institutions
High-accuracy and low-latency are two import properties that financial service institutions expect from a quality time series forecasting model.
High Accuracy A high level of accuracy in the forecasting model helps companies lower the risk of losing money in investments. Neural networks are believed to be good at capturing the dynamics in time series and hence yield more accurate predictions. There are many hyperparameters in the model so that data scientists and quantitative researchers can tune them to obtain the optimal model. Moreover, data science community believes that ensemble learning tends to improve prediction accuracy significantly. The flexibility of model architecture provides us a good variety of model members for ensemble learning.
Low Latency Operations in financial services are time-sensitive. For example, high frequency trading usually requires models to finish training and prediction within very short time periods. For deep neural network models, low latency can be guaranteed by distributed training with Horovod or distributed TensorFlow. Intel® Xeon multi-core processors, coupled with Intel’s MKL optimized TensorFlow, prove to be a good infrastructure option for such distributed training.
With these requirements in mind, we propose an ensemble learning model as in Figure 1, which is a combination of MLP (Multi-Layer Perceptron), CNN (Convolutional Neural Network) and LSTM (Long Short-Term Memory) models. Because architecture topologies for MLP, CNN and LSTM are quite different, the ensemble model has a good variety in members, which helps reduce risk of overfitting and produces more reliable predictions. The member models are trained at the same time over multiple nodes with Intel® Xeon processors. If more models need to be integrated, we just add more nodes into the system so that the overall training time stays short. With neural network models and HPC power of the Intel® Xeon processors, this system meets the requirements from financial service institutions.
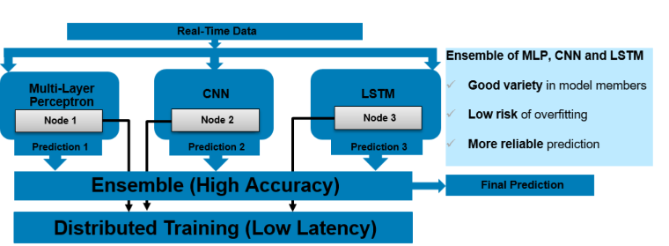 Training high accuracy ensemble model on HPC cluster with Intel® Xeon processors
Training high accuracy ensemble model on HPC cluster with Intel® Xeon processors
Fast Training with Intel® Xeon Scalable Processors
Our tests used Dell EMC’s Zenith supercomputer which consists of 422 Dell EMC PowerEdge C6420 nodes, each with 2 Intel® Xeon Scalable Gold 6148 processors. Figure 2 shows an example of time-to-train for training MLP, CNN and LSTM models with different numbers of processes. The data set used is the 10-Year Treasury Inflation-Indexed Security data. For this example, running distributed training with 40 processes is the most efficient, primarily due to the data size in this time series is small and the neural network models we used did not have many layers. With this setting, model training can finish within 10 seconds, much faster than training the models with one processor that has only a few cores, which typically takes more than one minute. Regarding accuracy, the ensemble model can predict this interest rate with MAE (mean absolute error) less than 0.0005. Typical values for this interest rate is around 0.01, so the relative error is less than 5%.
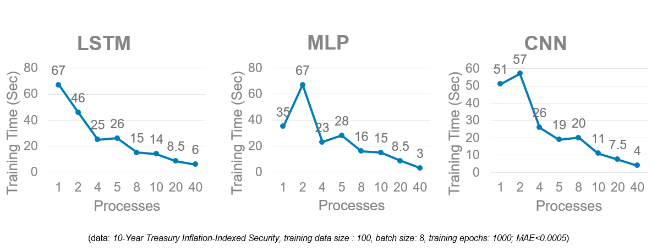 Training time comparison: Each of the models is trained on a single Dell EMC PowerEdge C6420 with 2x Intel Xeon® Scalable 6148 processors
Training time comparison: Each of the models is trained on a single Dell EMC PowerEdge C6420 with 2x Intel Xeon® Scalable 6148 processors
Conclusion
With both high-accuracy and low-latency being very critical for time series forecasting in financial services, neural network models trained in parallel using Intel® Xeon Scalable processors stand out as very promising options for financial institutions. And as financial institutions need to train more complicated models to forecast many time series with high accuracy at the same time, the need for parallel processing will only grow.