




Dell EMC Servers Excel in MLPerf™ Training v1.0 Benchmarks
Thu, 08 Jul 2021 15:28:25 -0000
|Read Time: 0 minutes
Dell Technologies has submitted MLPerf training v1.0 results. This blog provides an explanation of what is new with MLPerf training v1.0 and a high-level overview of our submissions. Results indicate that Dell EMC DSS8440 and PowerEdge XE8545 servers offer promising performance for Deep Learning training workloads across different areas.
MLCommons™ is a community that contains a consortium of experts in the Machine Learning/Deep Learning industry from different fields within AI technology. It consists of experts from industry, academia, startups, and individual researchers. MLPerf™ Training is the community-led test suite focusing on deep learning training. This test suite aims to measure how fast a system can train deep learning models across eight different problem types:
- Image classification
- Medical image segmentation
- Light-weight object detection
- Heavy-weight object detection
- Speech recognition
- Natural language processing
- Recommendation
- Reinforcement learning
These benchmarks provide a consistent and reproducible way to measure accuracy and convergence on individual accelerators, systems, and cloud setups. As of June 2021, MLPerf™ Training released the latest v1.0 results in the fourth round of submissions of MLPerf Training. The following changes are new with v1.0:
- Addition of two benchmarks:
- RNN-T—RNN-T is a speech recognition model. Speech recognition accepts raw audio samples and produces a corresponding text transcription. It uses the Libri-speech dataset, which is derived from audiobooks. An example of the use of speech recognition is Google Voice Search.
- 3D-UNet—3D-Unet is a model for 3D medical image segmentation. It accepts 3D images that contain tumors; the model divides (or segments) the tumor from the other parts in the image. It uses the KiTs19 dataset. An example of the use of 3D medical image segmentation is for the identification of kidney tumors.
- Introduction of a uniform and more mature process for evaluation and submission:
- Reference Convergence Points (RCP) checker to ensure hyperparameters are assessed consistently and uniformly across different submissions.
- Other checkers such as compliance checker, system desc checker, and package checker to check the accuracy of the submission.
- Result summarizer to provide a submission summary.
- Retirement of two language translation benchmarks from v0.7:
- GNMT
- Transformer
BERT serves as a replacement for language model tasks.
The following figure demonstrates the numbers from the Deep Learning v1.0 benchmarks submitted by Dell Technologies:
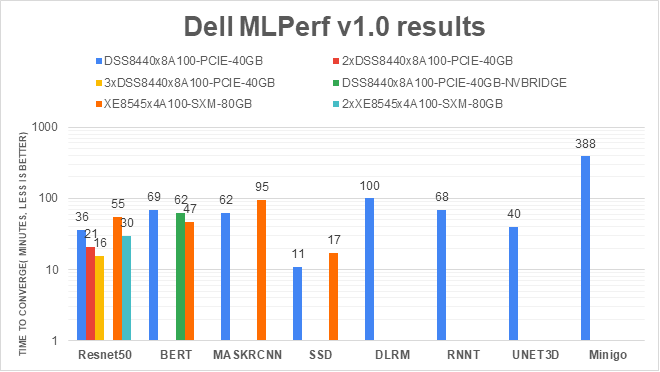
Figure 1: MLPerf v1.0 results from Dell Technologies
Contributions from Dell Technologies
Our submissions focused on Dell EMC DSS 8440 and Dell EMC PowerEdge XE8545 servers. The DSS 8440 server is an Intel-based, PCIe Gen3 4U server that supports up to 10 double-wide PCIe GPUs, focused on Machine Learning/Deep Learning applications such as training. The 4U PowerEdge XE8545 server supports the latest 3rd Gen AMD EPYC processors, PCIe Gen4, and the latest NVIDIA A100 Tensor Core GPUs for cutting edge machine learning workloads. Both of these system configurations are NVIDIA-Certified, which means they have been validated for best performance and optimal scalability. The submission from Dell Technologies also included multinode training entries to showcase scale-out performance.
Multinode training is important. Training is compute intensive, therefore, more compute nodes are used while training models. Because extra compute nodes help to reduce the turnaround time, it is critical to showcase multiple nodes’ performance. Dell Technologies and NVIDIA are the only submitters that submitted multiple nodes on GPUs. The submissions from NVIDIA run on Docker with a customized Slurm environment to optimize performance; we submitted multinode submissions with Singularity on our DSS 8440 servers as well as Docker and Slurm submissions on PowerEdge XE8545 servers. Singularity is a secure containerization solution primarily used in traditional HPC GPU clusters. Setup scripts with singularity help traditional HPC customers run MLPerf™ Training on their cluster without the need to fully restructure their existing cluster setup.
The PowerEdge XE8545 server provides the best performing submission with an air-cooled solution for NVIDIA A100-SXM-80GB 500W GPUs. Typically, 500W GPUs of most vendors' systems are cooled with liquid, due to the challenges presented by the high TDP. However, Dell Technologies invested engineering and design time to solve the thermal challenge and allows customers to avoid the need for costly changes to a standard data center setup.
The DSS 8440 server submissions to MLPerf™ Training v1.0 using the latest generation NVIDIA A100 40 GB-PCIe GPUs show a 2.1 to 2.4 times increase from equivalent MLPerf™ Training v0.7 submissions using NVIDIA V100S PCIe GPUs. Dell Technologies is committed to bringing the latest performance advancements to customers as quickly as possible.
Out of 12 different organizations, Dell Technologies and NVIDIA are the only two organizations that submitted results for all eight models in the MLPerf™ training v1.0 benchmarking suite.
Next steps
As a next step, we will publish more technical blogs to provide deep dives into DSS 8440 server and PowerEdge XE8545 server results.