




Bare Metal Compared with Kubernetes
Mon, 17 Aug 2020 23:55:52 -0000
|Read Time: 0 minutes
It has been fascinating to watch the tide of application containerization build from stateless cloud native web applications to every type of data-centric workload. These workloads include high performance computing (HPC), machine learning and deep learning (ML/DL), and now most major SQL and NoSQL databases. As an example, I recently read the following Dell Technologies knowledge base article: Bare Metal vs Kubernetes: Distributed Training with TensorFlow.
Bare metal and bare metal server refer to implementations of applications that are directly on the physical hardware without virtualization, containerization, and cloud hosting. Many times, bare metal is compared to virtualization and containerization is used to contrast performance and manageability features. For example, contrasting an application on bare metal to an application running in a container can provide insights into the potential performance differences between the two implementations.
Figure 1: Comparison of bare metal to containers implementations
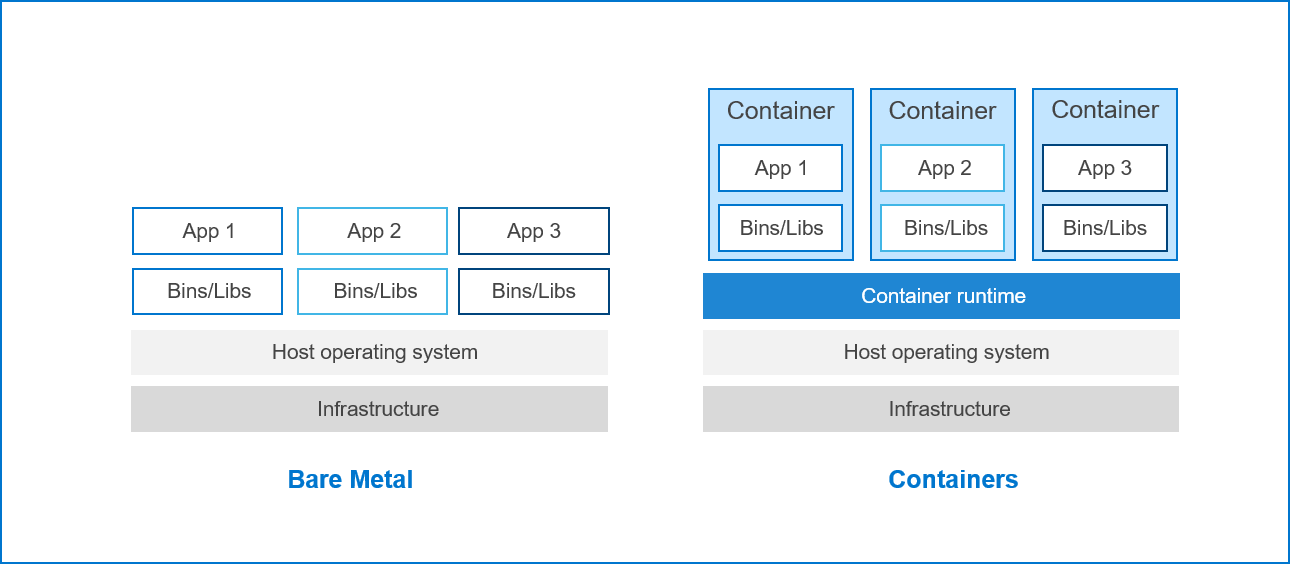
Containers encapsulate an application with supporting binaries and libraries to run on one shared operating system. The container’s runtime engine or management applications, such as Kubernetes, manage the container. Because of the shared operating system, a container’s infrastructure is lightweight, providing more reason to understand the differences in terms of performance.
In the case of comparing bare metal with Kubernetes, distributed training with TensorFlow performance was measured in terms of throughput. That is, we measured the number of images per second when training CheXNet. Five tests were run in which each test consecutively added more GPUs across the bare metal and Kubernetes systems. The solid data points in Figure 2 show that the tests were run using 1, 2, 3, 4, and 8 GPUs.
Figure 2: Running CheXNet training on Kubernetes compared to bare metal
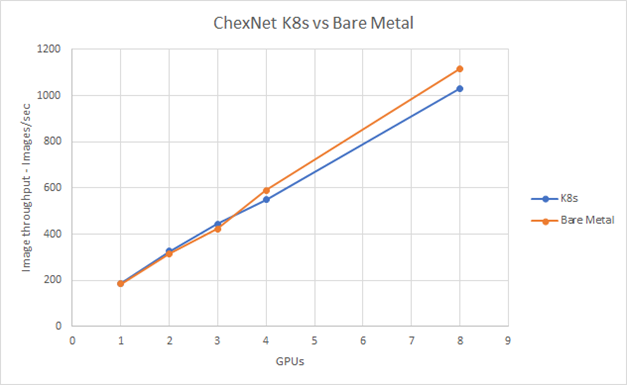
Figure 2 shows that the Kubernetes container configuration was similar in terms of performance to the bare metal configuration through 4 GPUs. The test through 8 GPUs shows an eight percent increase for bare metal compared with Kubernetes. However, the article that I referenced offers factors that might contribute to the delta:
- The bare metal system takes advantage of the full bandwidth and latency of raw InfiniBand while the Kubernetes configuration uses software defined networking using flannel.
- The Kubernetes configuration uses IP over InfiniBand, which can reduce available bandwidth.
Studies like this are useful because they provide performance insight that customers can use. I hope we see more studies that encompass other workloads. For example, a study about Oracle and SQL Server databases in containers compared with running on bare metal would be interesting. The goal would be to understand how a Kubernetes ecosystem can support a broad ecosystem of different workloads.
Hope you like the blog!