
ML workflows with cnvrg.io
ML workflows with cnvrg.io
-
A typical workflow for an ML project using cnvrg.io has multiple steps, as shown in the following figure:

Figure 1. The cnvrg.io workflow (source: cnvrg.io)
The workflow begins with the data. Through cnvrg.io, the data scientist can manage and version multiple ML datasets from a single console without the demands for close administration or management of the underlying infrastructure.
When the data is defined, the next step is research, where data scientists can interactively model the data to analyze and visualize the different potential outcomes.
Coding starts as the data scientists begin building the solution. Because cnvrg.io enables repositories and categorization of pipeline elements, there is a library of existing elements from which to choose. Or new, custom constructs can be created if there is no existing analog. At this level, data scientists are not only working with the software elements but also matching workloads to the underlying compute elements, including processing and storage.
Experimentation then follows, with the ability to manage, track, and visualize the different scenarios and configurations, choosing the best combination of models and coding to meet your organization’s needs.
When the optimal configuration is achieved, a single mouse click takes that complete pipeline from the lab to production where the data, models, and code can begin yielding results immediately. As this new solution moves into production, all the key elements are tracked in cnvrg.io for potential reusability.
cnvrg.io is an advanced modeling tool. The different data sources, models, and underlying elements can be added to an ML project easily through a visual workflow canvas, as shown in the following figure:
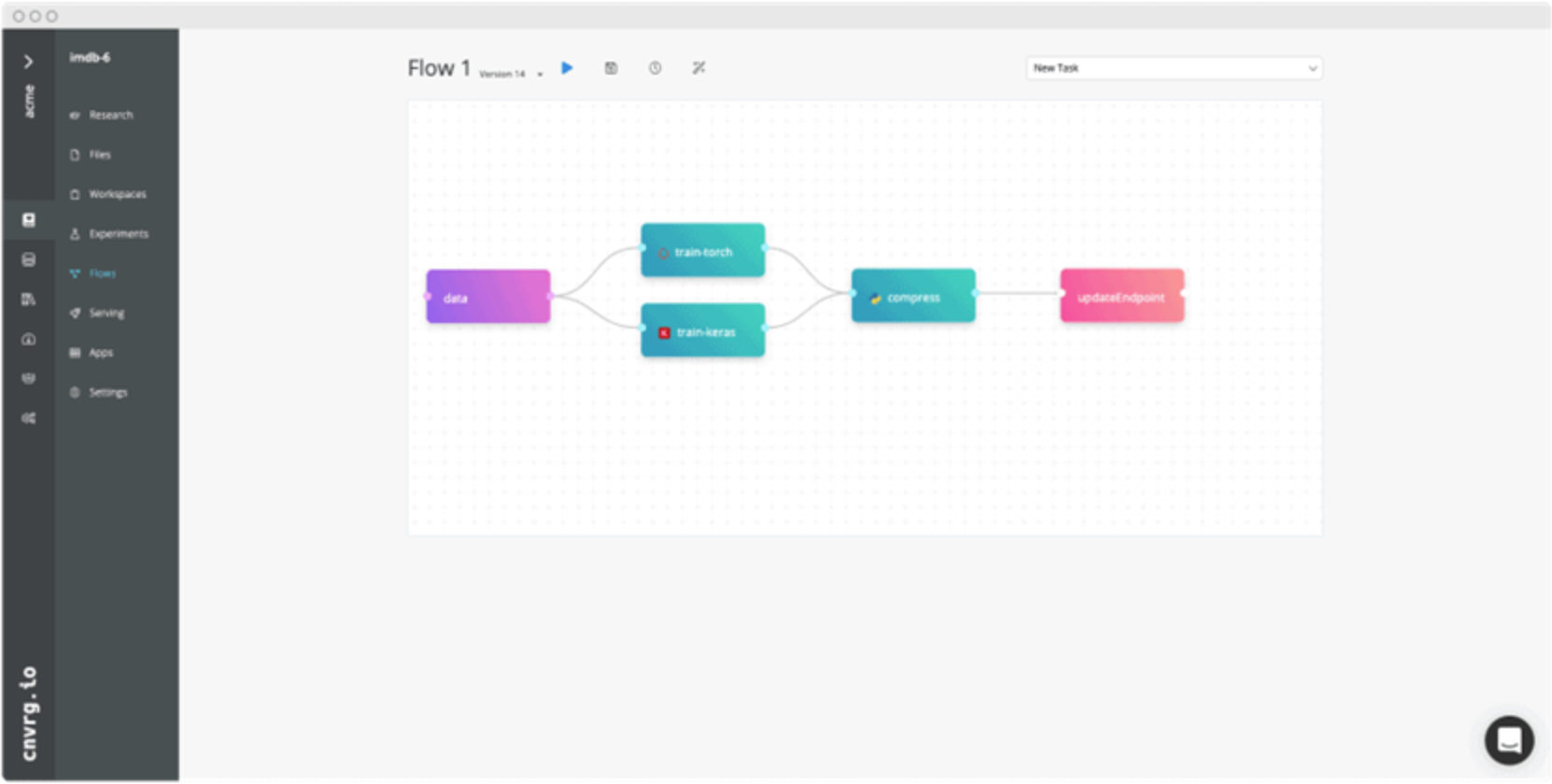
Figure 2. Creating an ML workflow visually with cnvrg.io (source: cnvrg.io)