
Architecture
Architecture
-
The way data is laid out across the nodes and their respective drives is fundamental to a cluster’s functionality, and this is particularly true for large files. Because OneFS consists of a single file system providing one vast, scalable namespace, a cluster can support datasets with hundreds of billions of small files, a smaller number of very large files, or some combination of the two—all within the same file system, free from multiple volume concatenations or single points of failure.
OneFS lays data out across multiple nodes, allowing files to benefit from the resources (drives and cache) of up to 20 nodes. This is significant not only for read and write performance but also for the rapid reconstruction of affected files in the event of a drive or node failure. OneFS uses Reed-Solomon erasure coding for protection at the file level, providing exceptional levels of storage utilization as well as enabling the cluster to recover data quickly and efficiently. OneFS provides protection against up to four simultaneous component failures respectively, and a single failure can be as little as an individual disk or an entire node.
Striped, distributed metadata coupled with continuous autobalancing affords OneFS near-linear performance characteristics, regardless of the capacity utilization of the system. Both metadata and file data are spread across up to 20 nodes, keeping the cluster balanced at all times.
The OneFS file system employs a native block size of 8 KB, and 16 blocks are combined to create a 128 KB stripe unit. Files larger than 128 KB are protected with error-correcting code parity blocks (FEC) and striped across nodes. This allows files to use the combined resources of up to 20 nodes, based on the selected protection policy. For instance, a 16 TiB file stored on OneFS will use more than 134 million 128 KB stripe units, organized into data stripes and protected with parity according to the protection level.
In keeping with the goal of storage management simplicity, OneFS automatically calculates and partitions the cluster into node pools, consisting of three or more nodes, which are optimized for both protection and efficient space utilization.
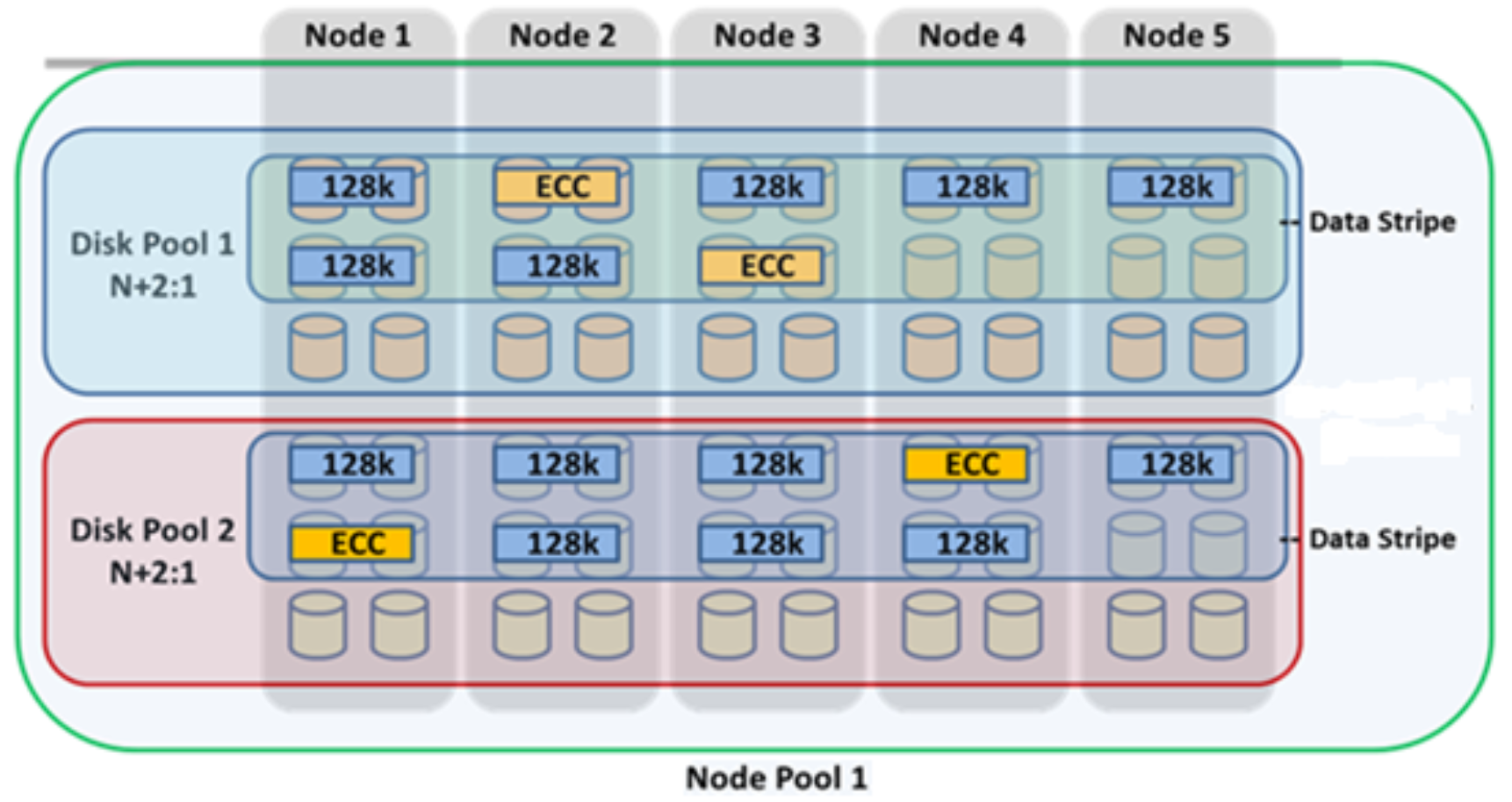
Figure 2. OneFS protection, striping, and pool hierarchy
Note: The best practice is to use the recommended protection level for a particular cluster configuration. This recommended level of protection is clearly marked as suggested in the OneFS WebUI storage pools configuration pages and is typically configured by default. In this example, the ubiquitous +2d:1n protection level guards against two drives or one node failure per node pool.
For more information about OneFS on-disk protection, see the High Availability and Data Protection white paper.
Each node pool is composed of one or mode disk pools from the same type of storage nodes, depending on the number of drives each node contains, and a disk pool may belong to exactly one node pool. Today, each node pool requires a minimum of three nodes.
Finally, OneFS neighborhoods are subdivisions of node pools that have been split into smaller groupings of nodes (fault domains) to increase reliability. Neighborhoods typically contain multiple disk pools and are a subgroup of a node pool and will not extend beyond the node pool bounds.
As described later in this paper, the large file compatibility checking command uses these pool and neighborhood concepts and references them in its output.
For more information on OneFS disk pools, node pools, neighborhoods, and tiers, see the SmartPools white paper.