
Stretched clusters and Storage Replica
A stretched cluster setup has two sites and two storage pools. Replicating data across WAN and writes on both sites results in lower performance compared to a standalone Storage Spaces Direct Cluster. Low latency inter-site links are necessary for optimum performance of workloads. Low bandwidth and high latency between sites can result in very poor performance on the primary site in the case of both synchronous and asynchronous replication.
Synchronous replication involves data blocks being written to log files on both sites before being committed. In asynchronous replication, the remote node accepts the block of replicated data and acknowledges back to the source copy. Application performance is not affected unless the rate of change of data is faster than the bandwidth of the replica link between the sites for large periods of time. This point is critical and must be taken into consideration when you are designing the solution.
The size of the log volume has no bearing on the performance of the solution. A larger log collects and retains more write I/Os before they are wrapped out. This allows for an interruption in service between the two sites (such as a network outage or the destination site being offline) to go on for a longer period.
| Scenario | Writes in two-way mirrored volumes | Writes in three-way mirrored volumes |
| Standalone storage spaces | 2x | 3x |
| Replication to secondary site | 4x | 6x |
The following figure illustrates the difference between synchronous and asynchronous replication:
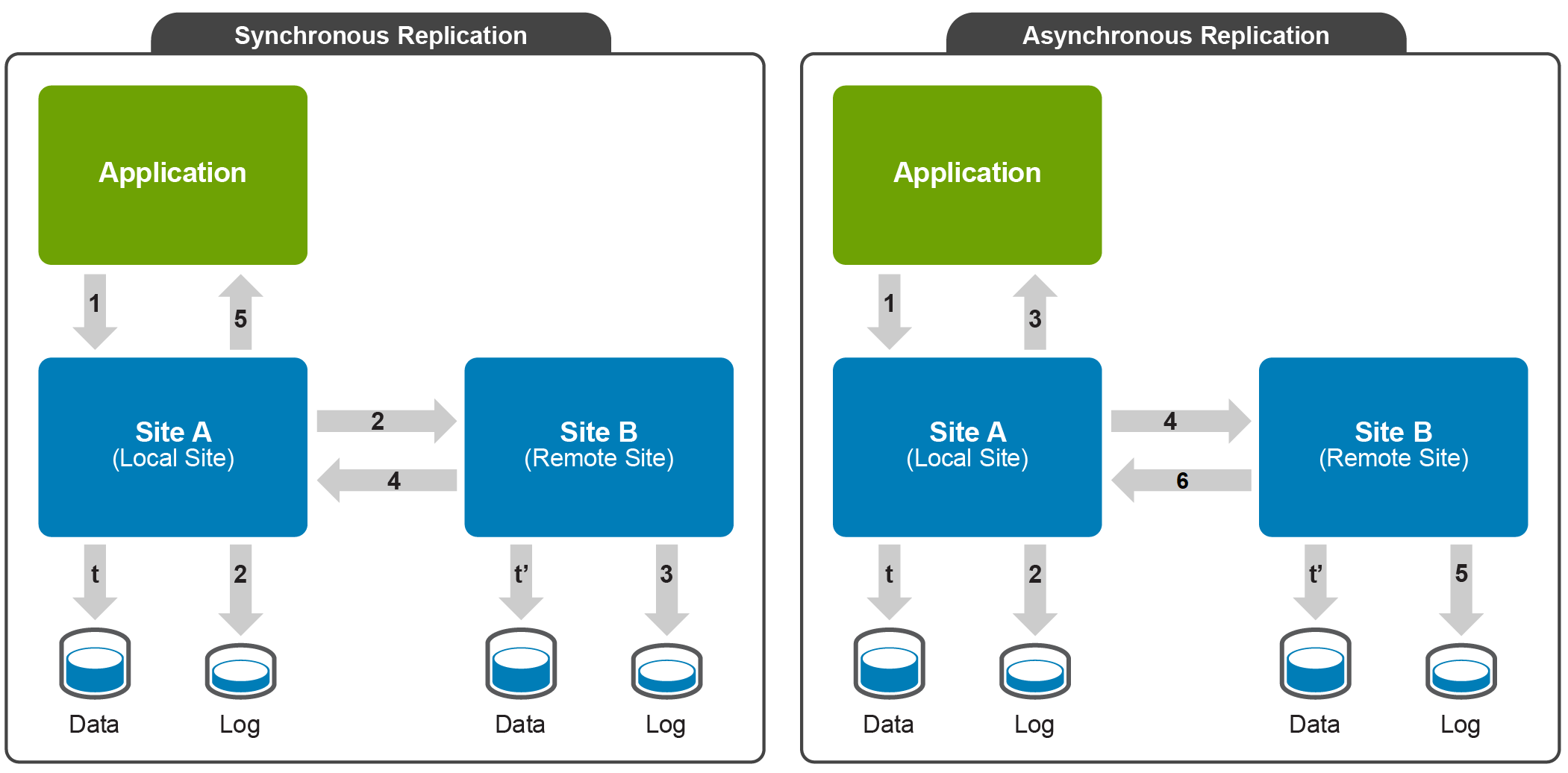
Synchronous replication: A block of data written by an application to a volume on Site A (1) is written first to the corresponding log volume on the same site (2), and is then replicated to Site B (2). At site B, the block of data is written to the Replica log volume (3) before a commit is sent back to the application using the same route (4 and 5). The block is subsequently pushed to the data volumes on both sites. For each block of data that the application writes, the commit is issued only after data is written to the secondary site. Thus there is no data loss at file system level in the event of a site failure. This results in a lower application write performance compared to a standalone deployment.
Asynchronous replication: A block of data written by an application to a volume on Site A (1) is written first to the corresponding log volume on the same site (2). A commit is immediately sent back to the application. At the same time, the block of data is replicated to Site B and written to the Replica log volume. In the case of a site failure, the cluster ensures that no data is lost beyond the configured Recovery Point Objective (RPO). Application performance is not affected unless the rate of change of data is faster than the bandwidth of the replica link between the sites for large periods of time. This is critical and must be taken into consideration when designing the solution.