
GPUs not only provide numerous compute cores, but also their own communication capabilities. For example, an NVIDIA H100 GPU provides more than 10,000 computation cores and 18 NVLink4 interfaces, each running at 200Gb/s, for a total aggregate bandwidth of 450GB/s. The most advanced NICs run today at the speed of 400Gb/s, a single H100 GPU can drive a bandwidth of 450GB/s, more than an order of magnitude higher.
As shown in Figure 10, the Scale Up Fabric interconnects the eight GPUs in a XE9680 to form a high bandwidth domain using the native interfaces of the GPU. This type of fabric enables efficient sharing and coordination of embedded resources, allowing multiple GPUs to work together. Scale Up Fabrics can seamlessly address complex tasks such as AI training and finetuning, and they are transparently supported by the Communication Library provided by the GPU vendor.
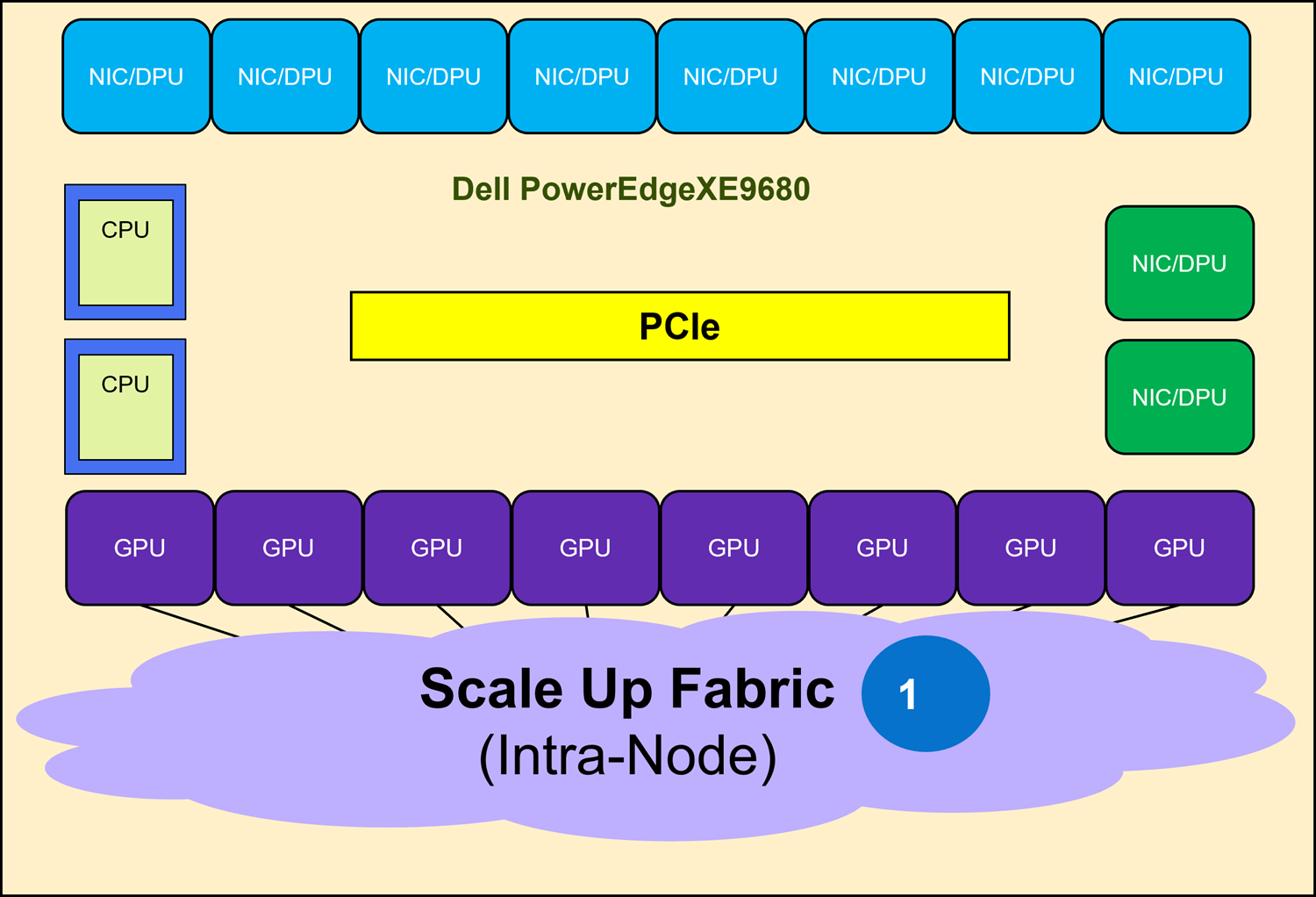
A Scale Up Fabric uses different technologies depending on the vendor. NVIDIA uses switched NVLink, AMD uses a full mesh of point-to-point XGMI links, and Intel uses Ethernet.
A Scale Up Fabric provides high bandwidth among the interconnected GPUs; however, it is spatially limited (that is, within a single server). A Scale Out Fabric is used to build a GPU cluster that is not limited to a single node.