
Maximizing Llama Open Source Model Inference Performance with Tensor Parallelism on a Dell XE9680 with H100s
Llama-2 13B Throughput analysis without TTFT constraint
Llama-2 13B Throughput analysis without TTFT constraint
-
In 0, we plot total throughput for different tensor parallelism degrees for Llama-2 13B with 4k tokens of context length (2k input and 2k output).
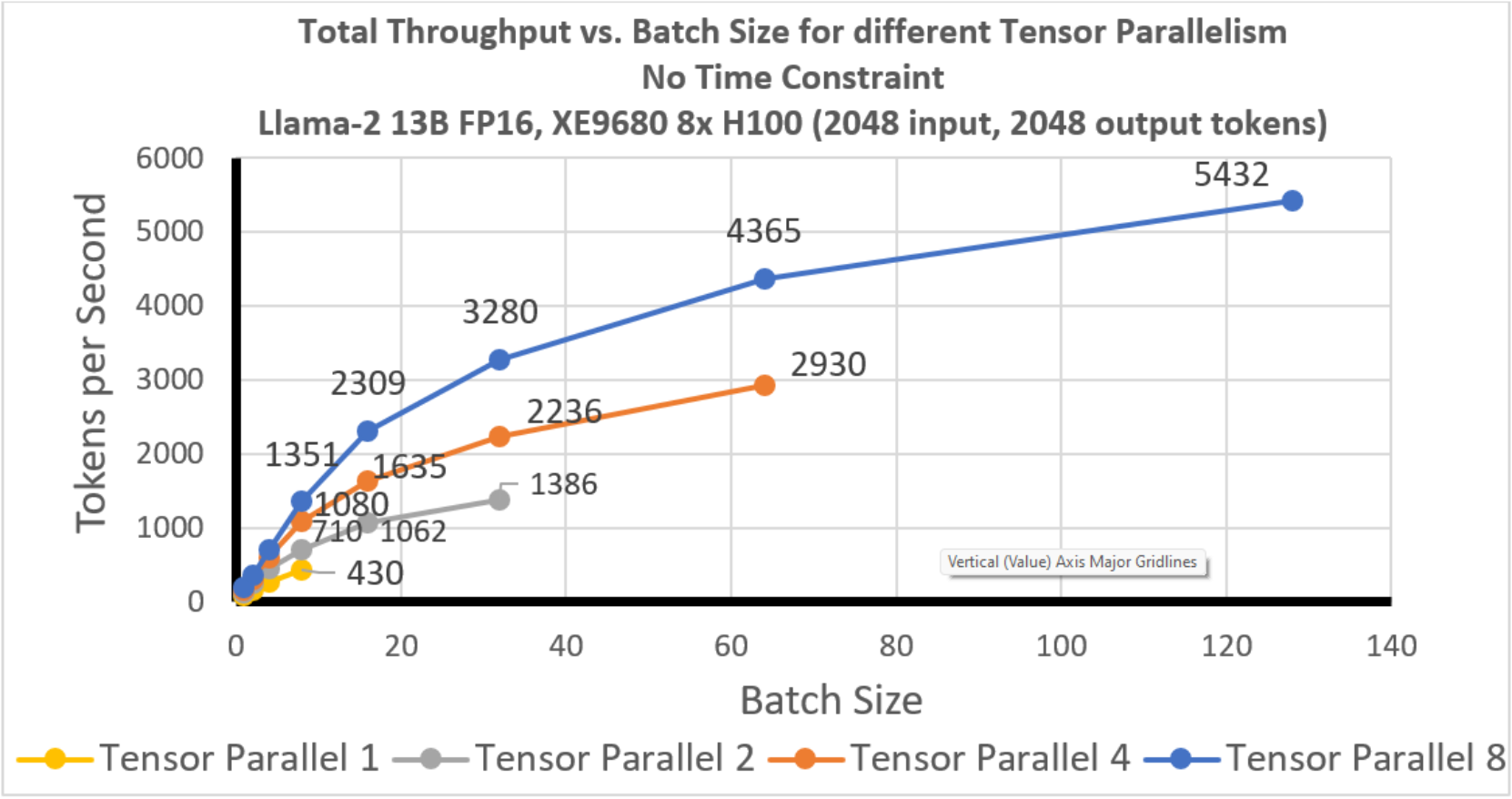
Figure 13. Llama-2 13B: Total Throughput vs. Batch size: No time constraint
In Figure 14, we show the total throughput at the best batch size (maximum batch size for each tensor parallelism). The maximum throughput observed with TP 8 is 5432 tokens per second.
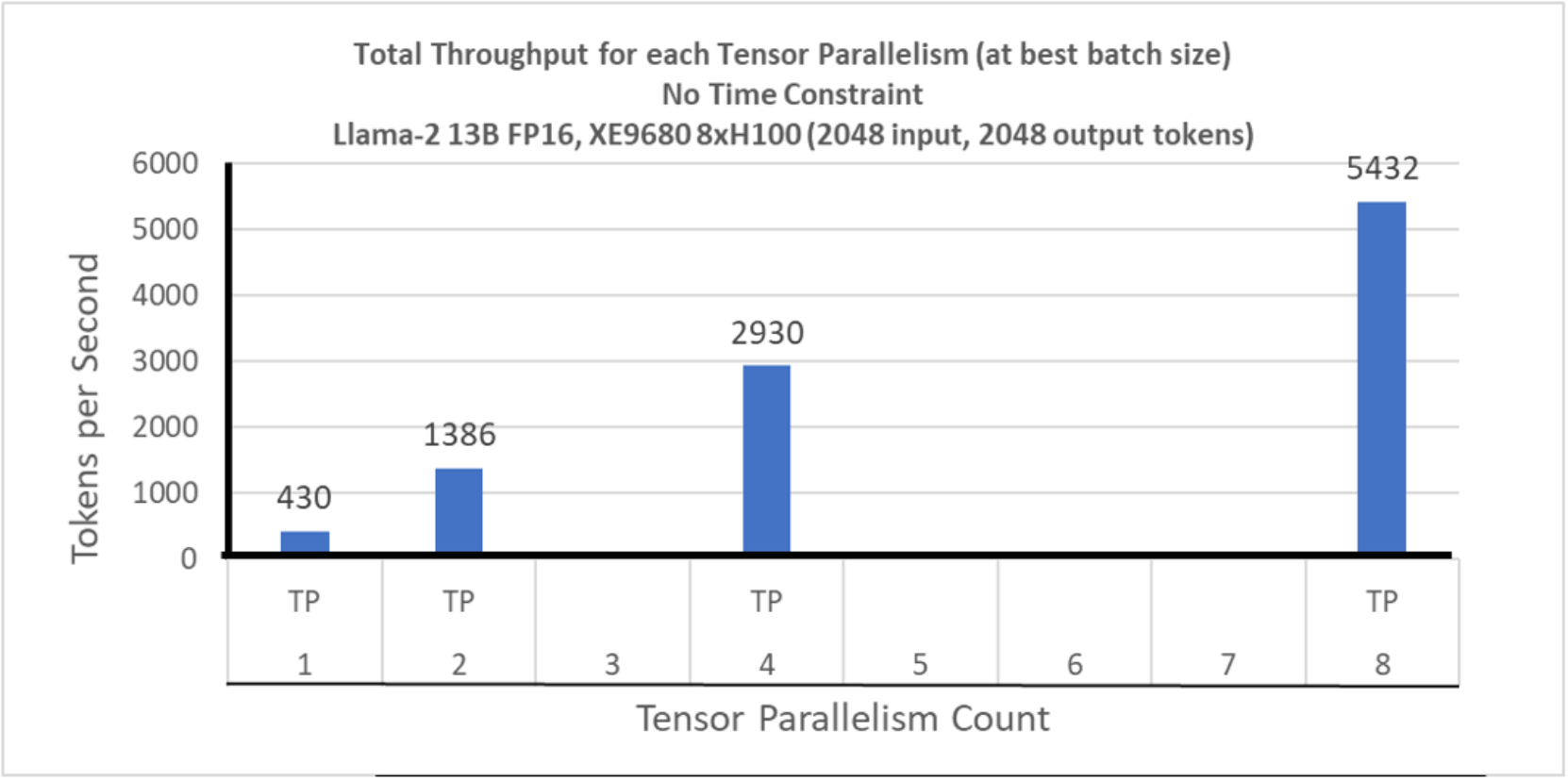
Figure 14. Llama-2 13B: Total Throughput at maximum batch size TP Comparison: No time constraint