
Maximizing Llama Open Source Model Inference Performance with Tensor Parallelism on a Dell XE9680 with H100s
Llama-2 13B Tokens per second per GPU without any TTFT constraint
Llama-2 13B Tokens per second per GPU without any TTFT constraint
-
We plotted the throughput efficiency per GPU for different tensor parallelism degrees at a full 4k tokens of context length (2k input and 2k output) without any time constraint.
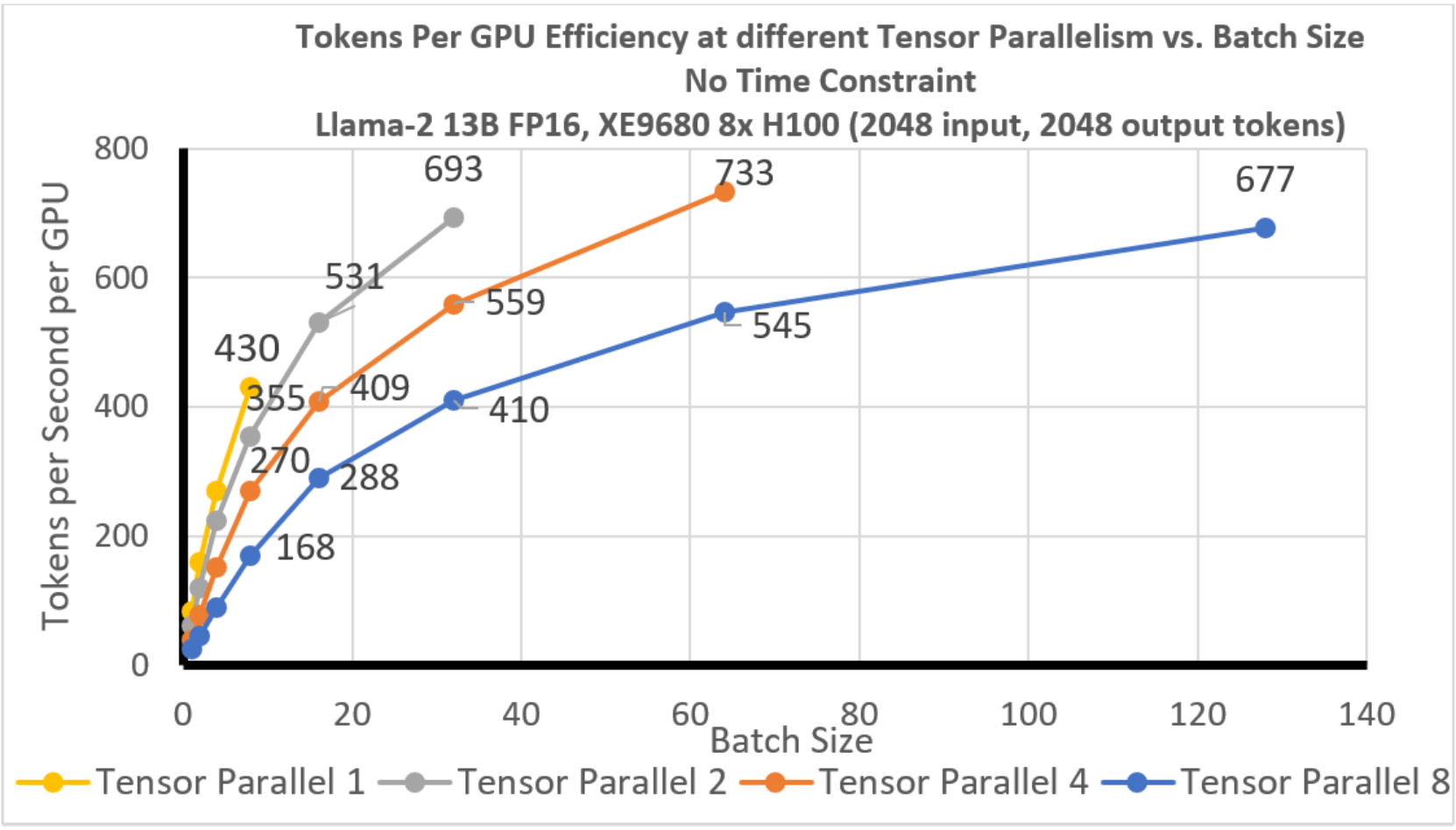
Figure 15. Llama-2 13B: Per GPU Efficiency vs. Batch Size: No time constraint
In Figure 16, we show the throughput per GPU efficiency at the best batch size (maximum batch size for each tensor parallelism). The TP1 case does not have enough memory to be fully effective, but by TP2 the throughput per GPU is .95x of the peak at TP 4. TP 8 continues to be very effective with efficiency of .92x that of TP4.
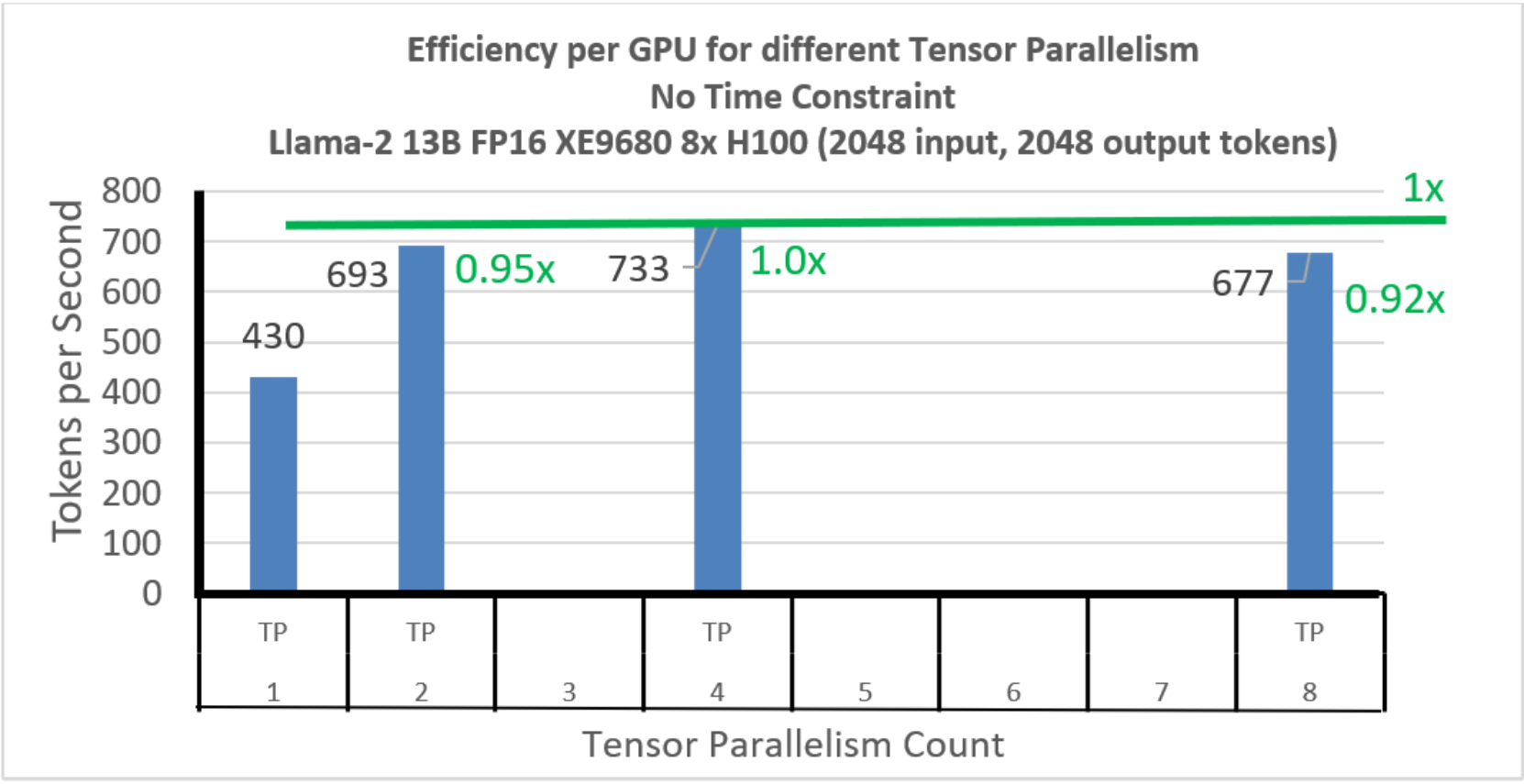
Figure 16. Llama-2 13B: Per GPU Efficiency at maximum batch size TP Comparison: No time constraint