




From Bare-Metal Edge Devices to a Full-Blown Kubernetes Cluster

Deploying a Kubernetes cluster on the edge involves setting up a lightweight, efficient Kubernetes (K8s) environment suitable for edge computing scenarios. Edge computing often involves deploying clusters on remote or resource-constrained locations, such as remote data centers, or even on-premise hardware in locations with limited connectivity.
This blog describes the steps for deploying an edge-optimized Kubernetes cluster on Dell NativeEdge.
Step 1: Select an Edge-Optimized Kubernetes Stack
Our Kubernetes stack is comprised of a Kubernetes controller, storage, and a virtual IP (also known as load balancer). We have chosen open-source components as our first choice for obvious reasons.
Standard K8s comes with a relatively high footprint cost which doesn’t fit low-cost functional edge use cases, and this is why MicroK8, K3s, K0, KubeVirt, Virtlet, and Krustlet have emerged as smaller footprint variants of Kubernetes.
We have chosen K3s as our Kubernetes cluster, Longhorn for storage, and Kube-VIP for our cluster networking.
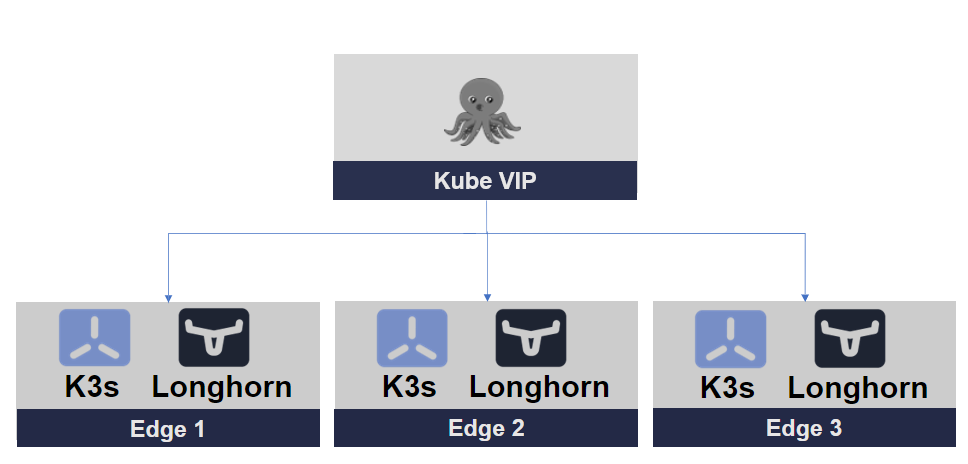
Figure 1. Edge-Optimized Kubernetes Stack
The following sections provide a quick overview of each element in the stack.
Edge-Optimized Kubernetes Cluster
Edge is a constrained environment that is often limited by resource capacity.
K3s is a lightweight, certified Kubernetes distribution designed for lightweight environments, including edge computing scenarios. It's an excellent choice for deploying Kubernetes clusters on the edge due to its reduced resource requirements and simplified installation process.
K3s Key Features:
- Minimal resource usage—K3s is designed to have a small memory and CPU footprint. It can run on devices with as little as 512MB of RAM and is suitable for single-node setups.
- Reduced dependencies—K3s eliminates many of the dependencies that are present in a full Kubernetes cluster, resulting in a smaller installation size and simplified management. It uses SQLite as the default database, for example, instead of etcd.
- Lightweight images—K3s uses lightweight container images, which further reduces its overall size. It includes only the necessary components to run a Kubernetes cluster.
- Single binary—K3s is distributed as a single binary, making it easy to install and manage. This binary includes both the server and agent components of a Kubernetes cluster.
- Highly compressed artifacts—K3s uses highly comp
ressed artifacts, including container images and binary files to reduce disk space usage. - Reduced network overhead—K3s can operate in network-constrained environments, making it suitable for edge computing scenarios.
- Efficient updates—K3s is designed to handle updates efficiently, ensuring that the cluster stays small and doesn't accumulate unnecessary data.
Edge-Optimized Storage
Longhorn is an open-source, cloud-native distributed storage system for Kubernetes. It is designed to provide persistent storage for containerized applications in Kubernetes environments.
Longhorn Key Features:
- Distributed block storage—Longhorn offers distributed block storage that can be used as persistent storage for applications running in Kubernetes pods. It uses a combination of block devices on worker nodes to create distributed storage volumes.
- Data redundancy—Longhorn incorporates data redundancy mechanisms such as replication and snapshots to ensure data integrity and high availability. This means that even if a node or volume fails, data is not lost.
- Kubernetes-native—Longhorn is designed specifically for Kubernetes and integrates seamlessly with it. It is implemented as a custom resource definition (CRD) within Kubernetes, making it a first-class citizen in the Kubernetes ecosystem.
- User-friendly UI—Longhorn provides a user-friendly web-based management interface for users to easily create and manage storage volumes, snapshots, and backups. This simplifies storage management tasks.
- Backup and restore—Longhorn offers a built-in backup and restore feature, enabling users to take snapshots of their data and restore them when needed. This is crucial for disaster recovery and data protection.
- Cross-cluster replication—Longhorn has features for replicating data across different Kubernetes clusters, providing data availability and disaster recovery options.
- Lightweight and resource-efficient—Longhorn is resource-efficient and lightweight, making it suitable for various environments, including edge computing, where resource constraints may exist.
- Open source and community-driven—Longhorn is an open-source project with an active community, which means it receives regular updates and improvements.
- Cloud-native storage solutions—It is well-suited for stateful applications, databases, and other workloads that require persistent storage in Kubernetes, offering a cloud-native approach to storage.
Kube-VIP (Load Balancer)
Kubernetes Virtual IP (Kube-VIP) is an open-source tool for providing high availability and load balancing within Kubernetes clusters. It manages a virtual IP address associated with services, ensuring continuous access to services, load balancing, and resilience to node failures.
Kube-VIP Key Features:
- Virtual IP (VIP)—Kube-VIP manages a virtual IP address, which is associated with a Kubernetes service. This IP address can be used to access the service, and Kube-VIP ensures that the traffic is directed to healthy pods and nodes.
- High availability—Kube-VIP supports high-availability configurations, allowing it to function even when nodes or control plane components fail. It can automatically detect node failures and reroute traffic to healthy nodes.
- Load balancing—Kube-VIP provides load-balancing capabilities for services, distributing incoming traffic among multiple pods for the same service. This helps distribute the load evenly and improve the service's availability.
- Support for various load-balancing algorithms—Kube-VIP supports multiple load-balancing algorithms, such as round-robin, least connections, and more, allowing you to choose the most suitable strategy for your services.
- Integration with Kubernetes—Kube-VIP is designed to work seamlessly with Kubernetes clusters and leverages Kubernetes resources to configure and manage the virtual IP and load balancing.
- Customizable configuration—Kube-VIP provides configuration options to fine-tune its behavior based on specific cluster requirements.
- Support for multiple load-balancer implementations—Kube-VIP can be used with different load-balancer implementations, including Border Gateway Protocol (BGP) and other network load-balancing solutions.
Step 2: Automating the Deployment of Edge Kubernetes on Dell NativeEdge
To automate the deployment of Edge Kubernetes on NativeEdge, we need to automate the deployment of all three components of our edge architecture.
For that purpose, we use the NativeEdge Orchestrator blueprint. The blueprint provides the automation scheme for each component and allows us to compose a solution offering an end-to-end automation of the entire cluster on all its components.
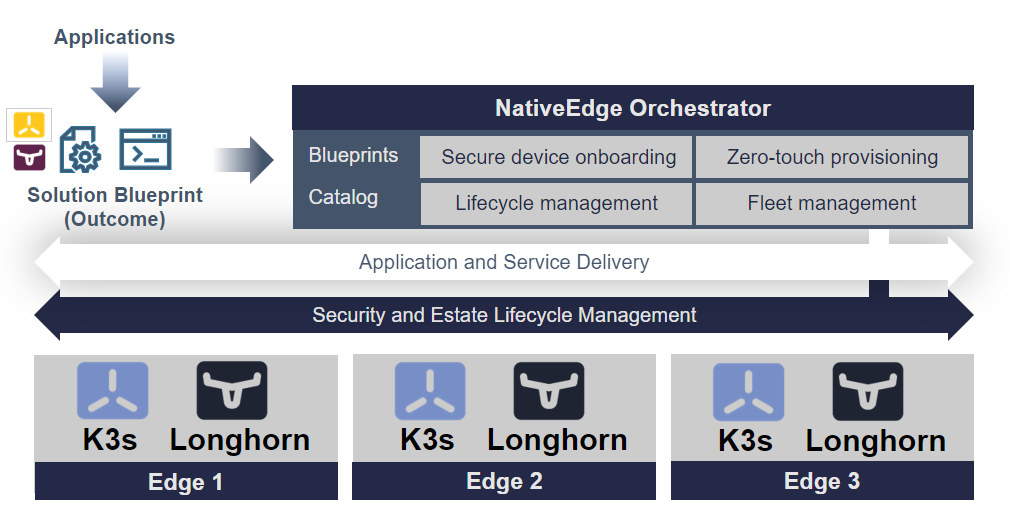
Figure 2. Automating the Kubernetes Cluster Deployment
Step 3: Deployment and Configuration
The following snippets show the blueprint for each of the three components that were previously described. A blueprint is a form of infrastructure as code (IaC) written in YAML format. Each blueprint uses a different automation plugin that fits each unit.
The first snippet shows the provisioning of a virtual IP address (VIP) that serves as the cluster entry point to the outside world. As with any load-balancer, it provides a single VIP address for all three nodes in the cluster. In this case, we chose a fabric plugin (SSH script) to automate the installation and configuration of that VIP service (scripts/install_kvip.sh).

Figure 3. VIP Blueprint Snippet
The second snippet shows the provision of the K3s cluster. It comes in multiple configuration flavors, a single node, and a three or five node HA cluster. We first provision the first node and then, in case of a multi node cluster, provision the rest of the nodes. All of the nodes form a cluster and result in an HA solution.

Figure 4. K3s Blueprint Snippet
The third snippet shows the provision of Longhorn, a cloud-native HA distributed block storage for Kubernetes. It is optional and the user can decide, using inputs, whether to add HA storage to the cluster. Longhorn creates replicas of the data in other nodes' volumes in the cluster, so in the case that a node fails, you still have the other replicas.
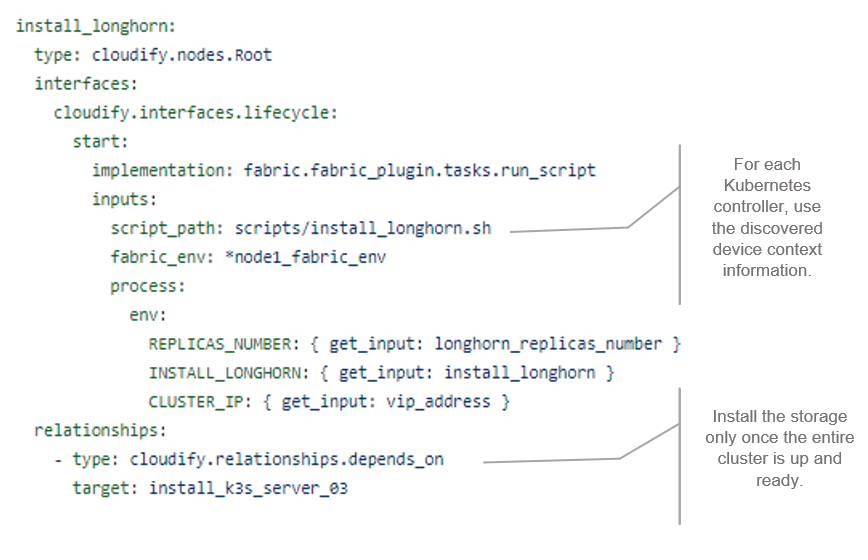
Figure 5. Storage (Longhorn) Helm Chart Blueprint
After you connect all of the components and create the HA Kubernetes cluster, you have a topology of three Kubernetes nodes (in case a of a three-node cluster), plus Kube-VIP as the VIP entry point to the cluster, and a Longhorn storage component, as shown in the following topology diagram.
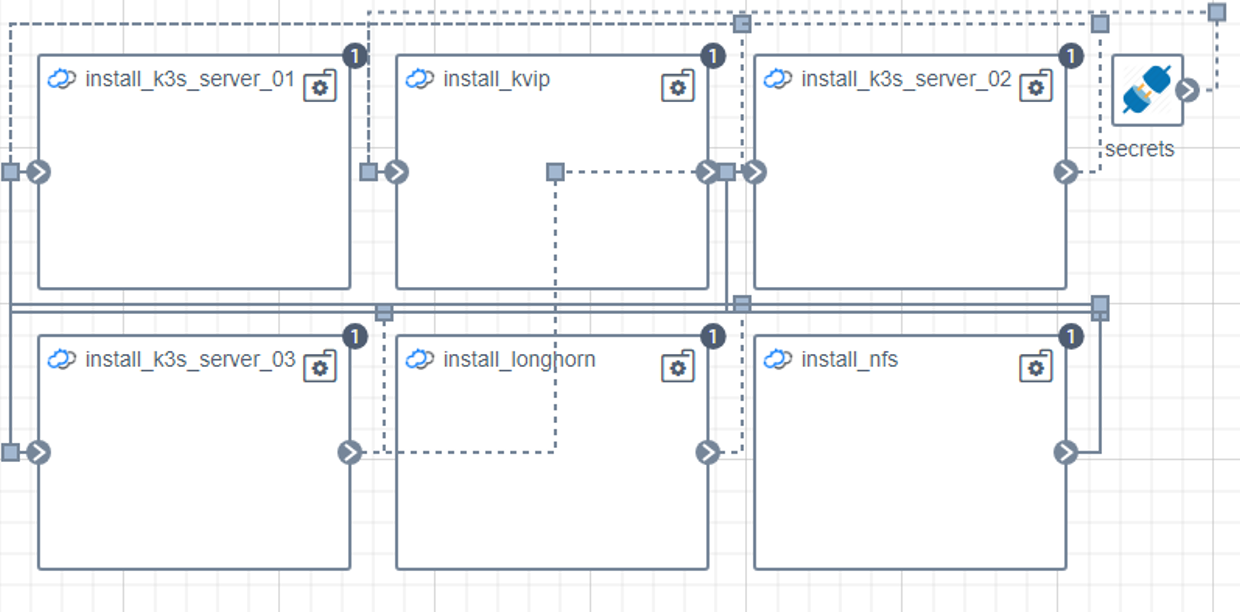
Figure 6. Automation Topology
This process takes a few minutes, and then you have an HA Kubernetes cluster.
Discovery
The discovery phase is responsible for maintaining the list of available edge devices. The result of the discovery is a list of environment entries each containing the relevant device assets management.
This list is used as an input to the deployment phase and lets the user select the designated devices that are used for the cluster.
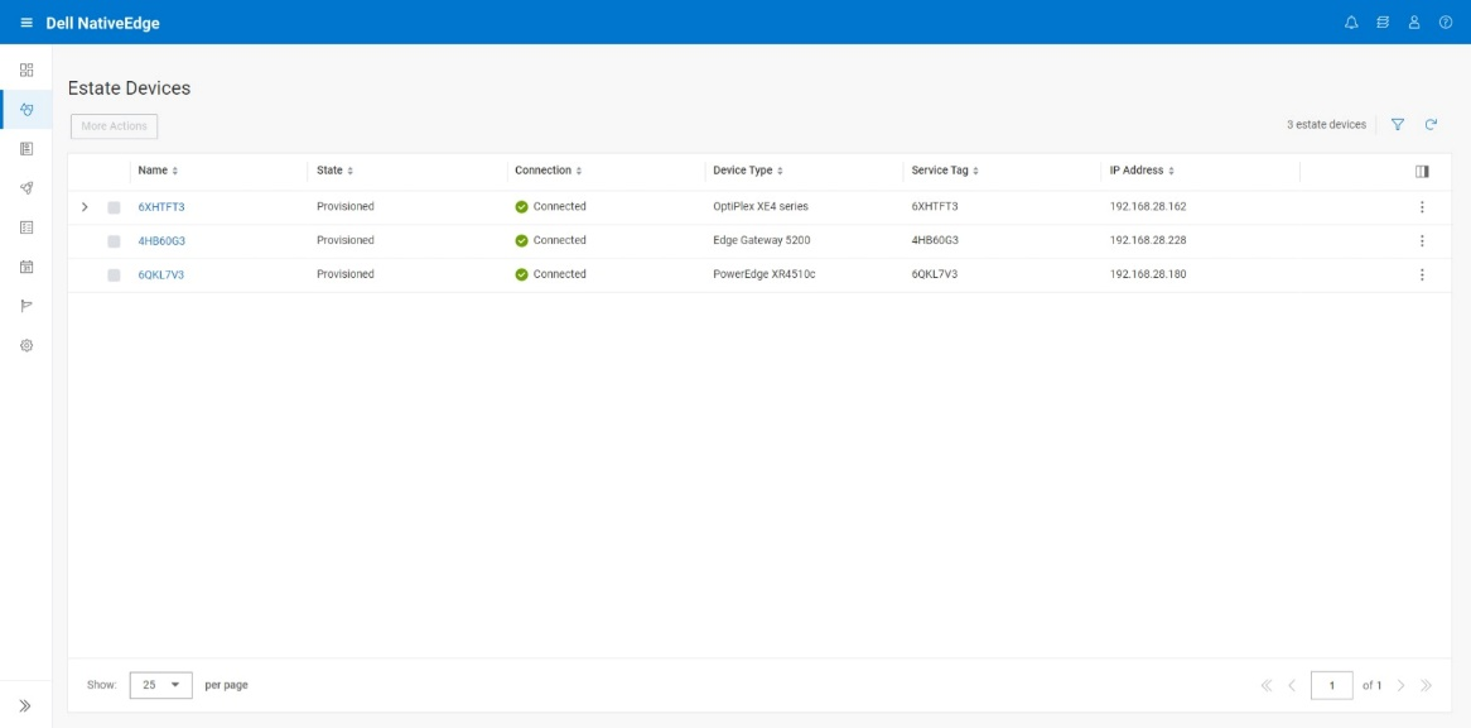
Figure 7. NativeEdge Discovery
In the previous snippet, we see the available NativeEdge Endpoints that the user can choose from to form a cluster. The user can choose either one or three NativeEdge Endpoints to create an HA cluster. An odd number of endpoints is needed for the cluster leader election algorithm. It is essential to avoid multiple leaders getting elected, a condition known as a split-brain problem. Consensus algorithms use odd number voting to elect the leader. An example of this could be electing the node with majority votes.
Workflow Execution
Workflow execution is the phase where we map the automation plan as described in the blueprint into a chain of tasks. This calls the relevant infrastructure resource API needed to establish our cluster.
The user starts by deploying the K3S blueprint from the application catalog, as shown in the following figure.
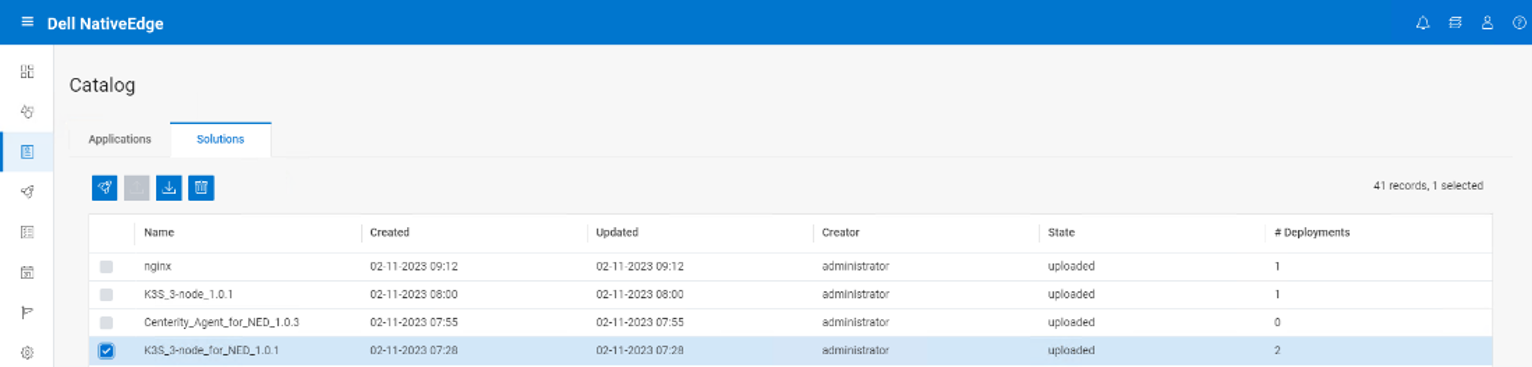
Figure 8. NativeEdge Workflow Execution
In the following figure, we can see the deployment progress bar, at 61 percent complete. It deploys all the necessary cluster resources, the K3S components, the Kube-VIP, and Longhorn.
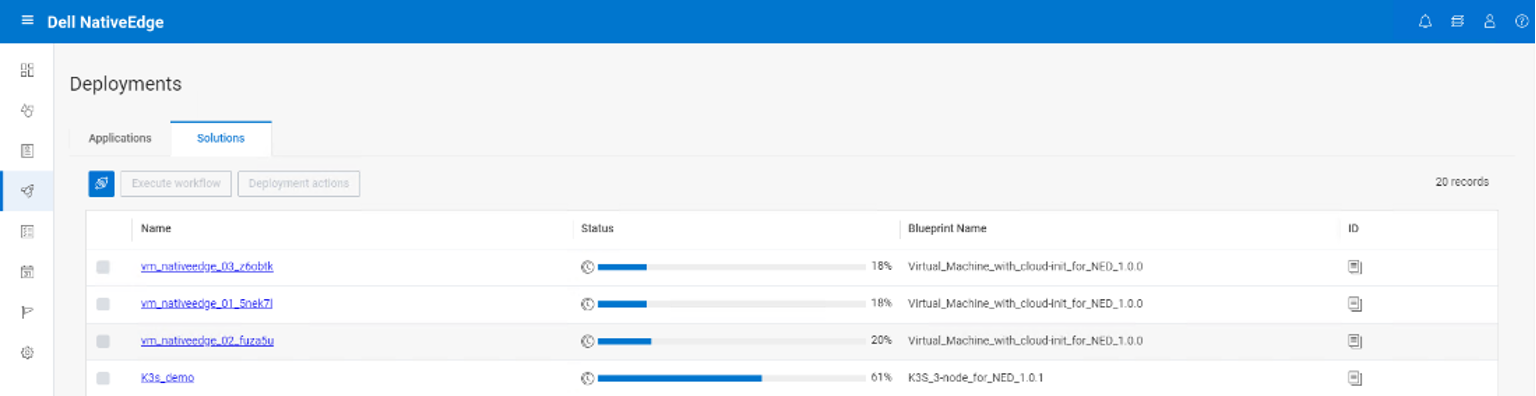
Figure 9. NativeEdge Solution Deployments
Upon deployment completion, NativeEdge shows the Deployment Capabilities and Outputs, as seen in the following figure. This list includes important information such as the K3s cluster endpoint to access the cluster.
The Deployment Capabilities and Outputs display also includes events or logs of the deployment execution, where the user can view various steps of the deployment execution.
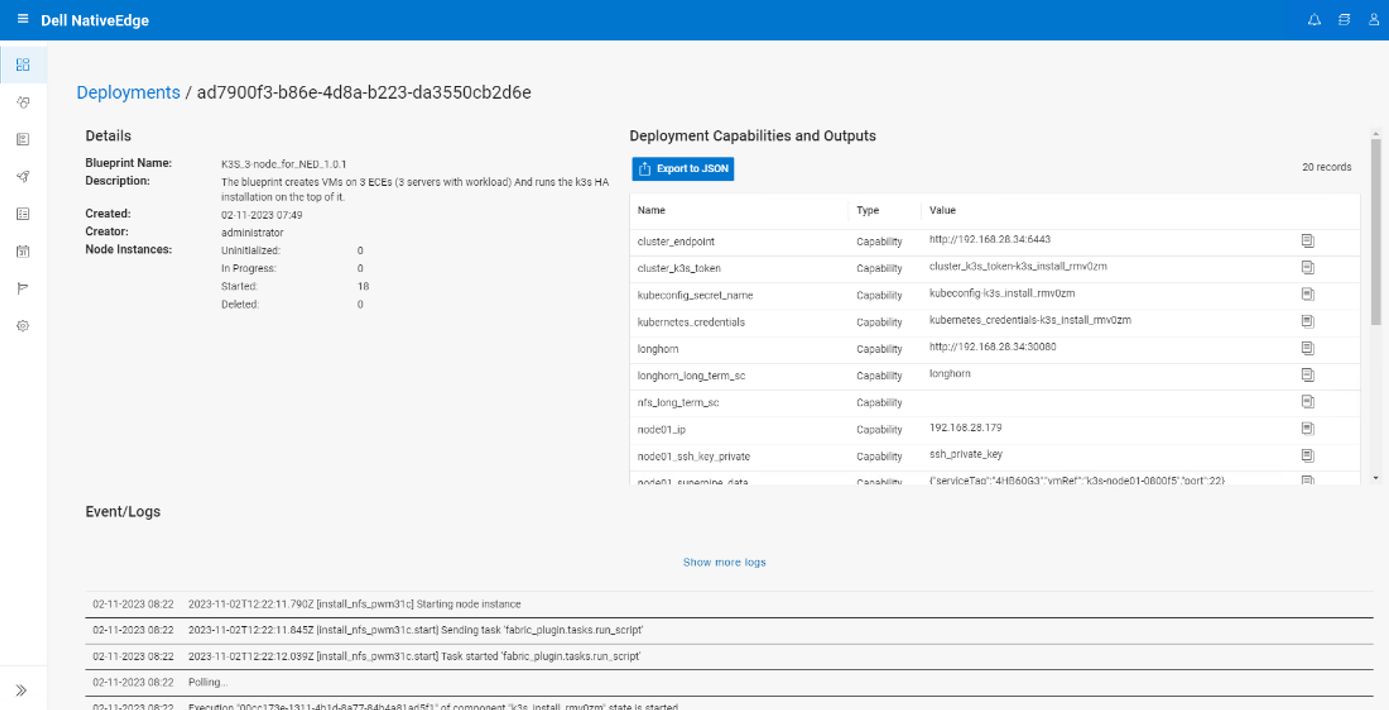
Figure 10. Deployment Details
Final Notes
Edge devices can vary significantly in terms of networking capability, resource level, hardware capabilities, operating systems, and functional role, leading to fragmentation in the edge computing ecosystem.
Edge AI is a catalyst event that leads to even more significant edge device fragmentation. It requires specialized hardware accelerators like GPUs, Neural Processing Units (NPUs), or Tensor Processing Units (TPUs) to efficiently run deep learning models. Different manufacturers produce these accelerators, leading to a variety of hardware platforms and architectures. In addition to that, many organizations, especially in industries such as automotive, healthcare, and industrial IoT, develop custom edge AI solutions tailored to their specific requirements.
Kubernetes Reduces the Edge Fragmentation Complexity
Using Kubernetes at the edge can help reduce device fragmentation complexity through:
- Abstraction—Kubernetes provides an abstraction of hardware differences.
- Containerization—Kubernetes provides a lightweight, portable workload execution framework, and can run consistently across various edge devices, regardless of the underlying operating system or hardware.
- Resource management—Kubernetes provides resource management features that allow you to allocate CPU and memory resources to containers.
- Edge clusters—Kubernetes can be set up to manage clusters of edge devices distributed across different locations, leveraging a fabric or mesh topology architecture.
- Rolling updates and version control—Kubernetes supports rolling updates and version control of containerized applications.
- Avoid vendor lock-in, the right Kubernetes for the job—Evolving extensions or variants of Kubernetes, may be better suited for the edge, including MicroK8, K3s, K0, KubeVirt, Virtlet, and Krustlet.
Having said that, setting up a Kubernetes cluster on edge devices can be a complex task.
NativeEdge provides a built-in blueprint that automates the entire process through a single API call.
It is also important to note that in this specific example, we refer to a specific edge Kubernetes stack. The provided blueprint can be easily extended to fit your specific environment or your choice of Kubernetes stack.