

Assets

Scale your Model Deployments with the Dell Enterprise Hub

Thu, 05 Sep 2024 20:46:16 -0000
|Read Time: 0 minutes
Overview
The Dell Enterprise Hub (https://dell.huggingface.co/) is a game changer for obtaining and using optimized models that run on some of the latest and greatest Dell hardware. The Dell Enterprise Hub has a curated set of models that have been deployed and validated on Dell Hardware.
This blog shows how a user can go from the Dell Enterprise Hub portal to a running model in minutes and will step you through the setup from the beginning until the containers are running.
Implementation
The Dell Optimized containers are built on top of the TGI framework (https://huggingface.co/docs/text-generation-inference/index) . This allows a user to rely on all the existing benefits of the TGI framework with it being optimized for Dell Hardware. In addition, once a Dell container is downloaded, it comes preconfigured with all of the required weights. This pre-configuration with weights may increase the download size to provide larger containers, however this provides simplicity to the user and no additional searching is needed to have a running system.
In the past, we showed how to run models from the Dell Enterprise Hub with Docker https://infohub.delltechnologies.com/en-us/p/hugging-face-model-deployments-made-easy-by-dell-enterprise-hub/. In this blog, we look at how to scale up model deployments using Kubernetes.
Kubernetes setup
In the Dell AI Labs, we leveraged the Dell Validated Design for Generative AI to perform models from the Dell Enterprise Hub. This blog focuses on deploying on to a Kubernetes cluster of Dell XE9680 servers that each have 8 x H100 NVIDIA GPUs. Support is also available on the Dell Enterprise Hub for 760XA servers that leverage H100 and L40S GPUs. Therefore, there is a lot of flexibility available when deploying a scalable solution on Dell servers from the Dell Enterprise Hub.
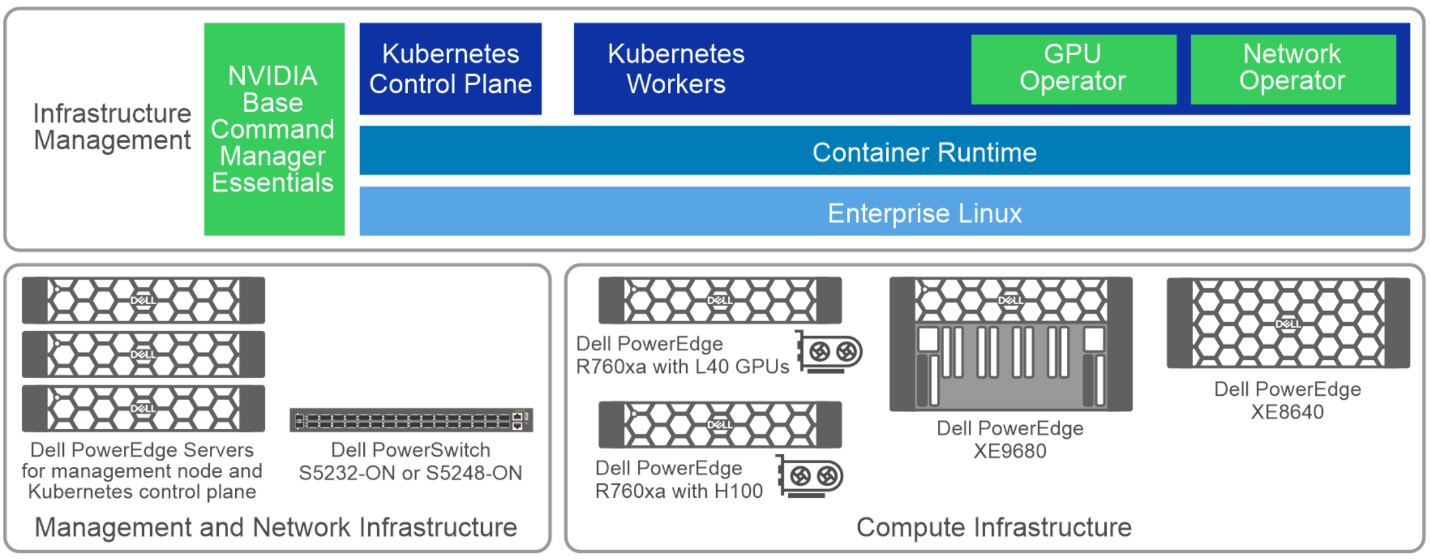 Example of Enterprise Kubernetes Deployment
Example of Enterprise Kubernetes Deployment
Note: This example shows an Enterprise Kubernetes deployment. Other Kubernetes distributions should also work fine.
Generating Kubernetes YAML
The first step is to log in to the Dell Enterprise Hub and navigate to a model you want to deploy. A sample for deploying Llama 70B with 3 replicas is:
An example of how that looks is below:
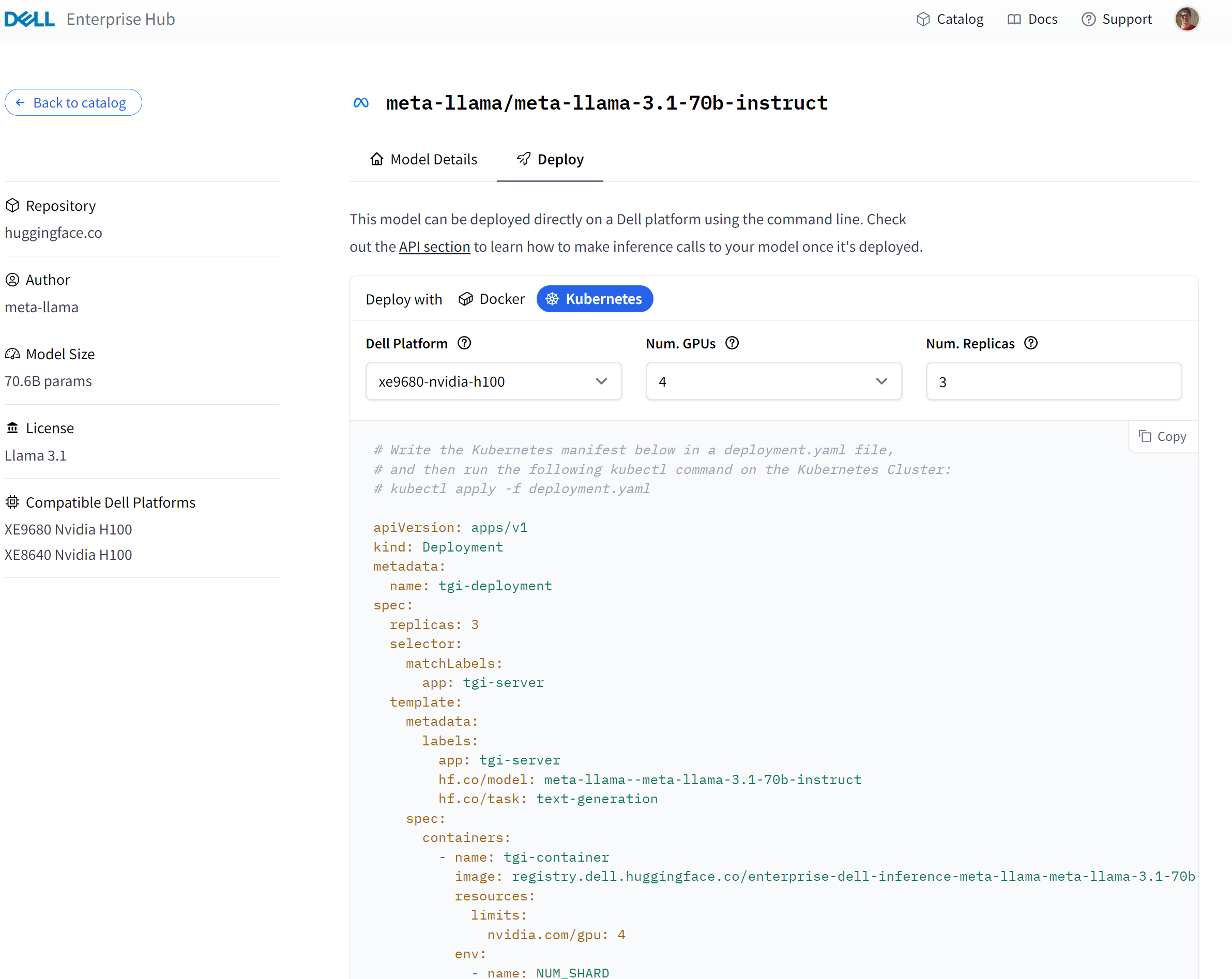
Model Deployment
When you select a model to deploy and select Kubernetes to deploy it with, a Kubernetes YAML snippet is generated. This snippet should be copied and inserted to a file, for example deployment.yaml, on your server where you have access to kubectl.
Then it is as simple as running the following:
>kubectl apply -f deployment.yaml deployment.apps/tgi-deployment created service/tgi-service created ingress.networking.k8s.io/tgi-ingress created
Note: The containers come prebuilt with all the weights so some models can be >100 GB. It takes time to download the models for the first time, depending on the size.
Gated Models
Some models may be private, or they may also require you to accept terms and conditions over the Hugging Face portal. The gated model deployment above fails if no token is passed since it is required for Llama models.
To solve for this it is possible to specify your token in two ways:
- Set your token as an environment variable in the deployment.yaml.
env: - name: HF_TOKEN value: “hf_...your-token”
- A good alternative is to use the Kubernetes secret feature. A sample of creating a secret for your token is:
kubectl create secret generic hf-secret --from-literal=hf_token=hf_**** --dry-run=client -o yaml | kubectl apply -f -
To use this token in your deployment.yaml you can insert the following:
env: - name: HF_TOKEN valueFrom: secretKeyRef: name: hf-secret key: hf_token
It is important to secure your token and not to post it in any public repository. For full details on how to use tokens see https://huggingface.co/docs/text-generation-inference/en/basic_tutorials/gated_model_access .
Testing the Deployment
Once the deployment is run, the following happens:
- A Deployment is made that pulls down the Llama 70B container.
- A LoadBalancer service is created.
- An Ingress component (based on nginx) is created.
In your environment it is possible that a LoadBalancer and Ingress may already exist. In that case the deployment.yaml can be adjusted to match your environment. This example was performed in an empty Kubernetes namespace without issues.
Validate the deployment
In this example, we have deployed three replicas of the Llama 3.1 70B model. Each model uses 4xH100 GPUs, which means that our model will be scaled across multiple XE9680 servers.
After the deployment has completed, and the Dell Enterprise Hub containers are downloaded, you can check on the state of your Kubernetes Pods using the following:
kubectl get pods
This does not show the location of the pods so the following command can be run to get the nodes that they are deployed to:
kubectl get pod -o=custom-columns=NODE:.spec.nodeName,NAME:.metadata.name
This shows something similar to the following:

Here the pods running Llama 3.1 70B are distributed across 2 different XE9680 servers (node005 and node002). The replicas can be increased as long as resources are available on the cluster.
Invoke the models
The Dell Enterprise Hub containers expose HTTP endpoints that can be used to perform queries in various formats. The full swagger definition of the API is available at https://huggingface.github.io/text-generation-inference/#/ .
Since we have deployed three replicas across multiple servers, it is necessary to access the HTTP endpoints through the Kubernetes LoadBalancer service. When running the models for Inference, it is important to note that the calls are stateless and there is no guarantee that subsequent requests go to the same model. To get the IP of the LoadBalancer you can run:
kubectl describe services tgi-service
For a simple test we can use the “generate” endpoint to POST a simple query to the model that we deployed in the previous step:
curl 123.4.5.6:80/generate \
-X POST \
-d '{"inputs":"What is Dell Technologies World?", "parameters":{"max_new_tokens":50}}' \
-H 'Content-Type: application/json'This produces the following output:
{"generated_text":" Dell Technologies World is an annual conference held by Dell Technologies, a multinational technology company. The conference is designed to bring together customers, partners, and industry experts to share knowledge, showcase new products and services, and network with others in the technology industry.\n"}In the example above, the response is successfully generated and keeps within the maximum limit of 50 tokens that was specified in the query.
Conclusion
The Dell Enterprise Hub simplifies the deployment and execution of the latest AI models. The prebuilt optimized containers deploy seamlessly on Dell Hardware.
In this blog we showed how quick and easy it is to run the latest Llama 3.1 model on a scalable Kubernetes cluster built on Dell servers.
For more infformation, see Simplifying AI: Dell Enterprise Hub Enables Kubernetes Deployment for AI Models.